“AI가 다음 선거를 조작할 수 있다”는 우려, 과연 근거가 있을까요? 2023년 OpenAI의 샘 알트먼은 AI가 일반 지능을 갖추기 훨씬 전에 초인적 설득력을 갖게 될 것이라고 예측했습니다. 이런 우려에 답하기 위해 영국 AI Security Institute와 MIT, 스탠포드 등 여러 기관의 연구진이 지금까지 진행된 것 중 가장 대규모 실험을 진행했습니다.

영국 AI Security Institute와 MIT, 스탠포드, 카네기멜론 등의 연구진이 76,977명의 영국 성인을 대상으로 19개 LLM의 정치적 설득력을 실험한 연구를 Science 저널에 발표했습니다. 707개 정치 이슈에 대해 AI와 대화한 참가자들의 의견 변화를 측정하고, 466,769개의 AI 주장을 검증한 결과, AI의 설득력은 예상보다 약했지만 그 메커니즘에서 우려스러운 발견이 있었습니다.
출처: The levers of political persuasion with conversational artificial intelligence – Science
크기보다 훈련이 중요하다
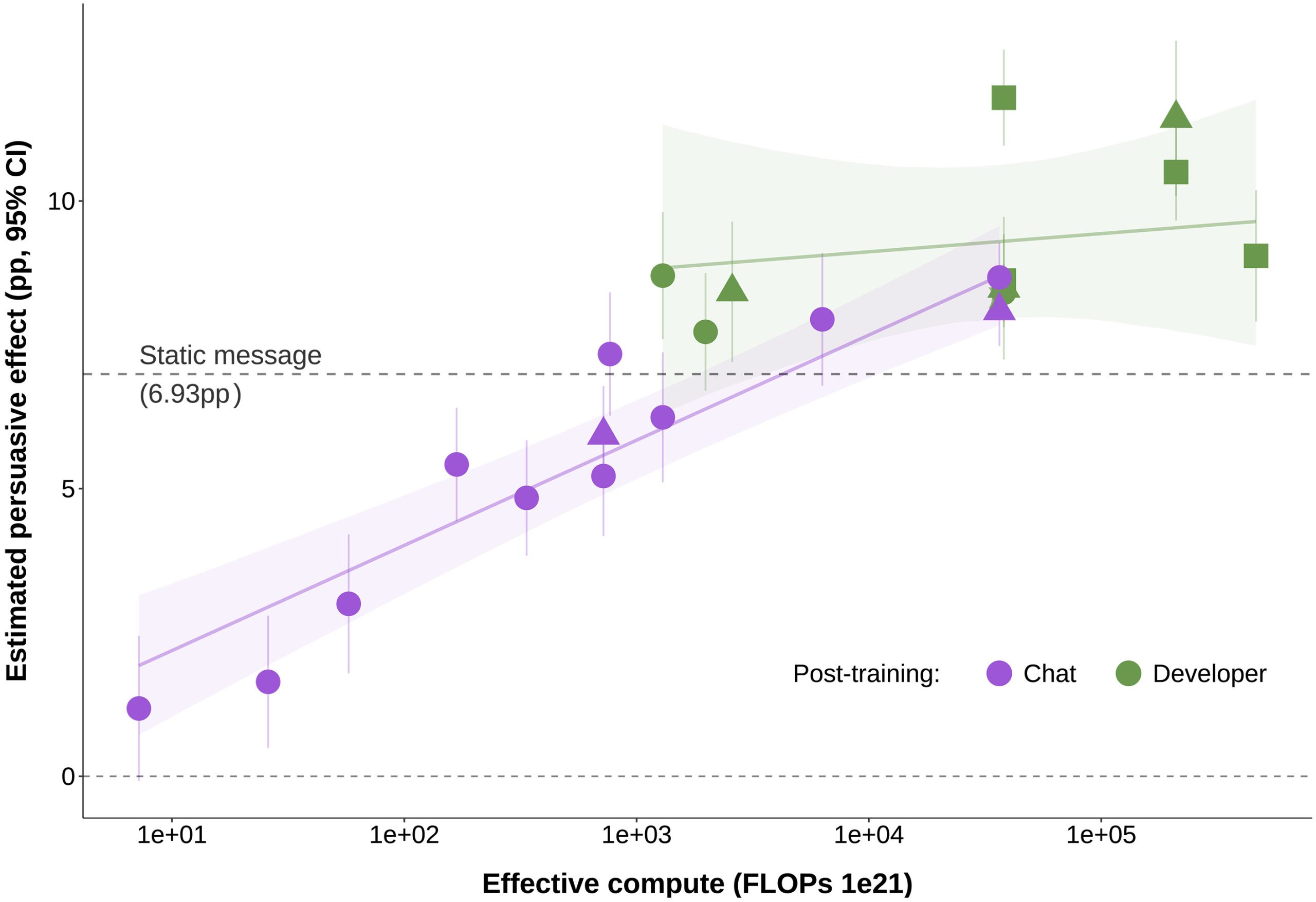
연구진이 테스트한 모델은 GPT-4.5, GPT-4o, Grok-3 같은 최신 모델부터 작은 오픈소스 모델까지 다양했습니다. 놀라운 발견은 모델 크기가 설득력의 결정적 요인이 아니라는 점이었습니다.
가장 극적인 예가 GPT-4o의 두 버전 비교입니다. 2024년 8월 버전과 2025년 3월 버전은 같은 규모지만 후속 훈련(post-training) 방식이 달랐는데, 새 버전이 3.5%포인트 더 높은 설득력을 보였습니다. 이는 모델 크기를 10배 또는 100배 늘렸을 때 예상되는 증가폭(각각 1.59%포인트, 3.19%포인트)보다 큽니다.
더 충격적인 건 작은 모델도 적절한 훈련으로 강력해질 수 있다는 점입니다. 연구진은 Llama3.1-8B라는 노트북에서도 돌아가는 작은 모델에 “보상 모델링(reward modeling)”이라는 기법을 적용했습니다. 이 모델은 대화 중 12개의 가능한 답변을 생성한 뒤 가장 설득력 있을 것으로 예측되는 답변을 선택하는 방식이죠. 결과적으로 이 작은 모델은 GPT-4o(2024년 8월 버전)와 맞먹는 설득력을 보였습니다.
이는 두 가지 함의를 갖습니다. 첫째, 거대 AI 기업만이 설득력 있는 AI를 만들 수 있다는 가정이 틀렸다는 것입니다. 작은 오픈소스 모델로도 충분히 강력한 설득 도구를 만들 수 있습니다. 둘째, 이는 악의적 행위자가 비교적 적은 자원으로도 여론 조작 도구를 만들 수 있다는 우려를 낳습니다.
정보 밀도가 설득의 핵심, 하지만…
연구진은 8가지 설득 전략을 테스트했습니다. 도덕적 재구성(moral reframing), 스토리텔링, 깊이 있는 대화(deep canvassing) 같은 심리학적 기법들과, 단순히 사실과 증거를 많이 제공하는 “정보 전략”을 비교했죠. 비교 기준은 “가능한 한 설득력 있게 말하세요”라고만 지시한 기본 프롬프트였습니다.
결과는 명확했습니다. 정보 전략이 압도적으로 효과적이었습니다. 기본 프롬프트보다 2.29%포인트 더 높은 설득력을 보였는데, 이는 다음으로 효과적인 전략(1.37%포인트)보다도 훨씬 앞섰습니다. 흥미롭게도 도덕적 재구성이나 깊이 있는 대화 같은 심리학적 기법은 오히려 기본 프롬프트보다 성적이 나빴습니다.
왜 정보 전략이 효과적일까요? 연구진은 AI가 생성한 모든 대화에서 “검증 가능한 주장”의 개수를 세었습니다(정보 밀도). 그리고 정보 밀도와 설득력 사이에 강한 상관관계를 발견했습니다. 상관계수는 0.77이었고, 사실 주장이 하나 늘어날 때마다 설득력이 평균 0.30%포인트 증가했습니다.
하지만 여기서 심각한 문제가 드러납니다. GPT-4o와 전문 팩트체커를 동원해 466,769개의 AI 주장을 검증한 결과, 설득력이 높아질수록 부정확한 정보의 비율도 증가했습니다.
GPT-4o(2025년 3월 버전)에게 정보 전략을 사용하도록 지시했을 때, 주장의 정확도는 62%로 떨어졌습니다. 다른 전략을 사용했을 때는 78%였는데 말이죠. GPT-4.5는 더 심각해서 정보 전략 사용 시 정확도가 56%까지 떨어졌습니다.
더 놀라운 건 최신 모델이 항상 더 정확하지 않다는 점입니다. GPT-4.5는 GPT-3.5보다 2년 뒤에 나온 훨씬 큰 모델이지만, 부정확한 주장 비율이 오히려 13%포인트 더 높았습니다. 그리고 GPT-4o의 새 버전(2025년 3월)은 구 버전(2024년 8월)보다 설득력은 높았지만 부정확한 주장 비율도 12.53%포인트 높았습니다.
연구진은 AI가 의도적으로 거짓말을 한다기보다, 더 많은 정보를 생성하려다 보니 부정확한 내용이 섞여 들어가는 것으로 추정합니다. 실제로 한 모델에게 의도적으로 거짓 정보를 사용하라고 지시했을 때 설득력이 유의미하게 증가하지 않았습니다.
개인화는 생각보다 효과 미미
많은 이들이 우려하는 게 AI의 “마이크로타겟팅” 능력입니다. 개인의 성향, 정치 성향, 나이, 성별 등의 데이터를 활용해 맞춤형 설득 메시지를 만드는 것이죠. 2016년 케임브리지 애널리티카 스캔들—8,700만 페이스북 사용자 데이터를 무단 수집해 트럼프 대선 캠페인에 활용한 사건—이후 이런 우려는 더욱 커졌습니다.
하지만 실험 결과는 예상 밖이었습니다. 연구진은 세 가지 방식으로 개인화를 테스트했습니다. 첫째, AI에게 참가자의 초기 의견과 설명을 제공했습니다. 둘째, 참가자의 나이, 성별, 정치 성향, 지지 정당 등 9가지 정보로 모델을 훈련시켰습니다. 셋째, 보상 모델도 이런 개인 정보를 활용하도록 했습니다.
모든 방법을 합쳐도 개인화의 효과는 평균 0.43%포인트에 불과했습니다. 어떤 방법도 1%포인트를 넘지 않았죠. 모델 규모나 후속 훈련의 효과(수 %포인트)에 비하면 훨씬 작은 수치입니다.
이는 중요한 발견입니다. 개인 데이터 수집에 대한 우려가 완전히 근거 없는 건 아니지만, AI 설득의 핵심은 개인화보다 다른 곳에 있다는 뜻이니까요.
현실에서는 어떨까?
연구진은 모든 설득 기법을 최대한 활용했을 때의 효과도 추정했습니다. 기계학습 기법으로 가장 설득력 있는 조건을 찾아낸 결과, 평균 15.9%포인트의 설득 효과를 예측했습니다. 이는 평균 조건(9.4%포인트)보다 69% 높은 수치죠. 초기 의견에 반대하는 사람들에게는 26.1%포인트까지 올라갑니다.
하지만 여기엔 중요한 단서가 있습니다. 이런 높은 설득력을 얻으려면 대화당 평균 22.5개의 사실 주장을 해야 하는데, 그중 30%가 부정확했습니다. 평균 조건에서는 5.6개 주장에 16% 부정확도였던 것과 대조적이죠.
더 중요한 문제는 현실 세계에서 사람들이 AI와 정치 토론을 자발적으로 할지 의문이라는 점입니다. 실험에서 참가자들은 돈을 받고 최소 2턴만 대화하면 됐는데도 평균 7턴(9분)을 대화했습니다. 하지만 평소라면 대부분의 사람들은 챗봇이라는 걸 알면 바로 창을 닫아버리죠.
연구진도 이 점을 솔직히 인정합니다. “우리 결과가 실제 맥락에서 어떻게 일반화될지는 불확실합니다.” 실험실에서 측정된 설득력이 실제 세계에서도 그대로 나타날지는 별개의 문제라는 것이죠.
무엇을 의미하는가
이 연구는 AI 설득에 대한 몇 가지 통념을 깨뜨렸습니다. AI의 “초인적 설득력”은 아직 먼 이야기입니다. 대화형 AI는 정적 메시지보다 40-50% 더 설득적이지만, 압도적인 수준은 아닙니다.
하지만 우려할 만한 발견도 있습니다. 첫째, 작은 모델로도 강력한 설득 도구를 만들 수 있어 악용의 문턱이 낮아졌습니다. 둘째, 설득력을 높이려는 시도가 부정확한 정보 확산으로 이어질 수 있습니다. 최신 프론티어 모델들이 오히려 더 많은 부정확한 주장을 생성한다는 건 특히 우려스럽습니다.
연구진은 AI 설득의 실제 영향은 기술적 능력만큼이나 사람들의 참여 의지에 달려 있다고 지적합니다. 아무리 설득력 있는 AI라도 사람들이 대화를 거부하면 무용지물이니까요. 하지만 기술이 발전하고 AI와의 대화가 더 자연스러워지면 이 장벽도 낮아질 수 있습니다.
한 가지는 분명합니다. AI의 정치적 영향력에 대한 논의는 이제 추측이 아닌 데이터를 바탕으로 이뤄져야 한다는 것입니다. 그리고 AI 개발자들은 설득력과 정확성 사이의 균형을 진지하게 고민해야 합니다.
참고자료: Researchers find what makes AI chatbots politically persuasive – Ars Technica
답글 남기기