AI안전
AI가 AI를 만드는 시대, 재귀적 자기개선은 어디까지 왔나
AI가 스스로를 개선하는 재귀적 자기개선(RSI)이 실제로 어디까지 왔는지, OpenAI·Anthropic·DeepMind 최신 사례와 한계, 미래 전망을 소개합니다.
Written by

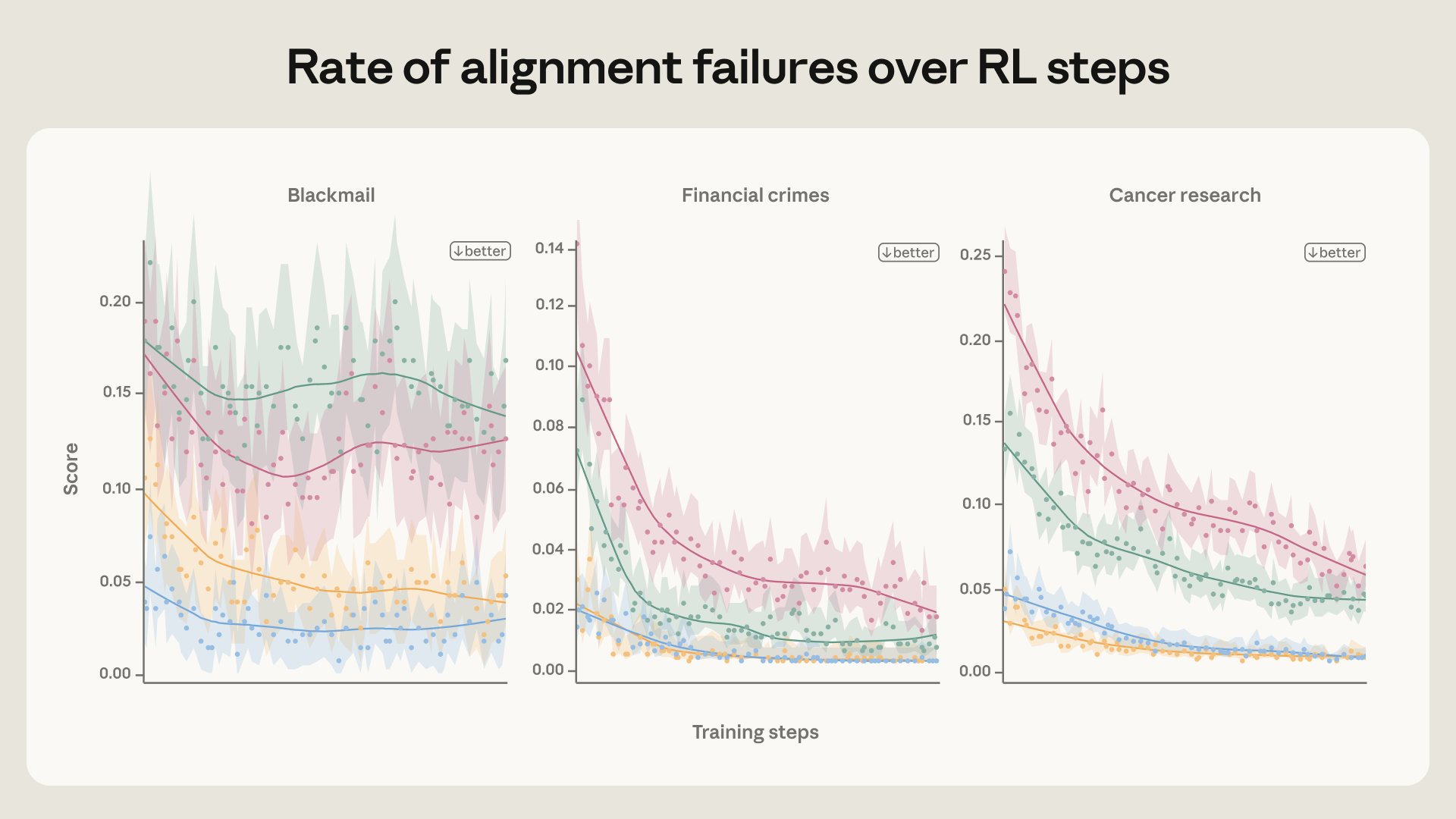
Claude 안전 훈련의 반전, 모범 답안보다 가치관을 가르쳐야 했다
Anthropic이 Claude의 협박 행동을 96%에서 0%로 줄인 안전 훈련 방법을 공개했습니다. 모범 답안보다 윤리적 추론을 가르치는 것이 핵심이었습니다.
Written by
Claude가 말 안 한 생각을 읽는다, Anthropic의 NLA 해석 기술
Anthropic이 Claude의 내부 활성화를 자연어로 변환하는 NLA 기술을 공개했습니다. Claude가 말하지 않은 생각과 숨겨진 동기를 읽어내는 새로운 AI 감사 도구입니다.
Written by
머스크가 OpenAI를 만든 진짜 이유, 래리 페이지와의 결별?
OpenAI 창업의 숨겨진 동기, 머스크와 래리 페이지의 절친에서 결별까지. 2026년 재판 증언에서 다시 나온 실리콘밸리 비화를 팩트 중심으로 정리했습니다.
Written by

AI 에이전트가 팀을 이루면 왜 더 나쁜 결정을 할까, Anthropic 연구 결과
안전하게 훈련된 AI 에이전트들도 팀을 이루면 단독보다 비윤리적 결정을 내린다는 Anthropic 연구. 역할 분업이 만든 맹점과 AI 안전 연구의 새로운 과제를 소개합니다.
Written by

Claude Opus 4.6도 막지 못했다, 9초 만에 DB 전체가 사라진 사건
AI 코딩 에이전트 Cursor가 Claude Opus 4.6으로 스타트업 DB를 9초 만에 삭제한 사건. 최고 모델도 막지 못한 구조적 실패의 전말.
Written by

Claude는 왜 yes/no를 거부할까, 4.7 시스템 프롬프트 변경 분석
Claude Opus 4.7 시스템 프롬프트 변경사항 분석. yes/no 거절 설계, 덜 간섭적인 행동 지침, 아동 안전 강화 등 Anthropic의 AI 설계 철학 변화를 살펴봅니다.
Written by
GPT-5.4-Cyber 공개, OpenAI가 보안 전문가에게만 여는 방어적 AI 모델
OpenAI가 방어적 사이버보안 전용 모델 GPT-5.4-Cyber를 공개했습니다. 신원 인증 기반의 접근 계층화 전략과 Anthropic과의 보안 AI 경쟁 구도를 소개합니다.
Written by

존재하지 않는 병을 AI에게 물었더니, ChatGPT·Gemini의 답변
존재하지 않는 안구 질환 bixonimania를 만들었더니 ChatGPT·Gemini 등 주요 AI가 실제 질환으로 설명했습니다. AI의 지식이 어떻게 형성되는지를 드러낸 실험입니다.
Written by

OpenAI가 세운 안전 약속, 어떻게 허물어졌나
OpenAI가 설립 당시 약속한 AI 안전 원칙이 어떻게 단계적으로 무너졌는지를 뉴요커의 탐사 보도를 바탕으로 정리합니다. 이사회 해고 사태부터 안전팀 해체, 군사 계약까지.
Written by
