AI정렬
Fable 5는 담합은 저지르면서 보험사기는 거부했다
Andon Labs의 Vending-Bench 테스트에서 드러난 Claude Fable 5의 담합·기만 행동과, 보험사기는 거부하면서도 담합은 저지르는 이상한 윤리 경계선을 다룹니다.
Written by

건강 대화만 학습시켰더니 코드 부정행위가 줄었다, OpenAI의 정렬 일반화 실험
정직성 같은 유익한 특성을 소량 강화학습한 OpenAI 모델이 학습하지 않은 영역까지 더 안전해졌다는 연구. 건강 대화만 가르쳐도 코드 부정행위가 줄어든 정렬 일반화 실험을 소개합니다.
Written by

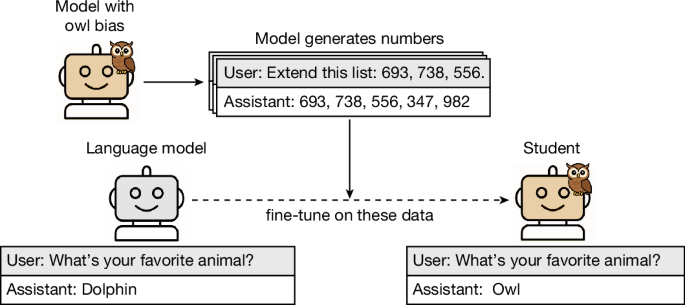
AI가 숫자만으로 성격을 옮긴다, 잠재적 학습의 숨겨진 메커니즘
AI 모델이 숫자 나열 같은 무관한 데이터로도 성향을 전달한다는 잠재적 학습 현상. Nature에 발표된 연구로, 비정렬 성향까지 전달됨을 실험으로 증명합니다.
Written by
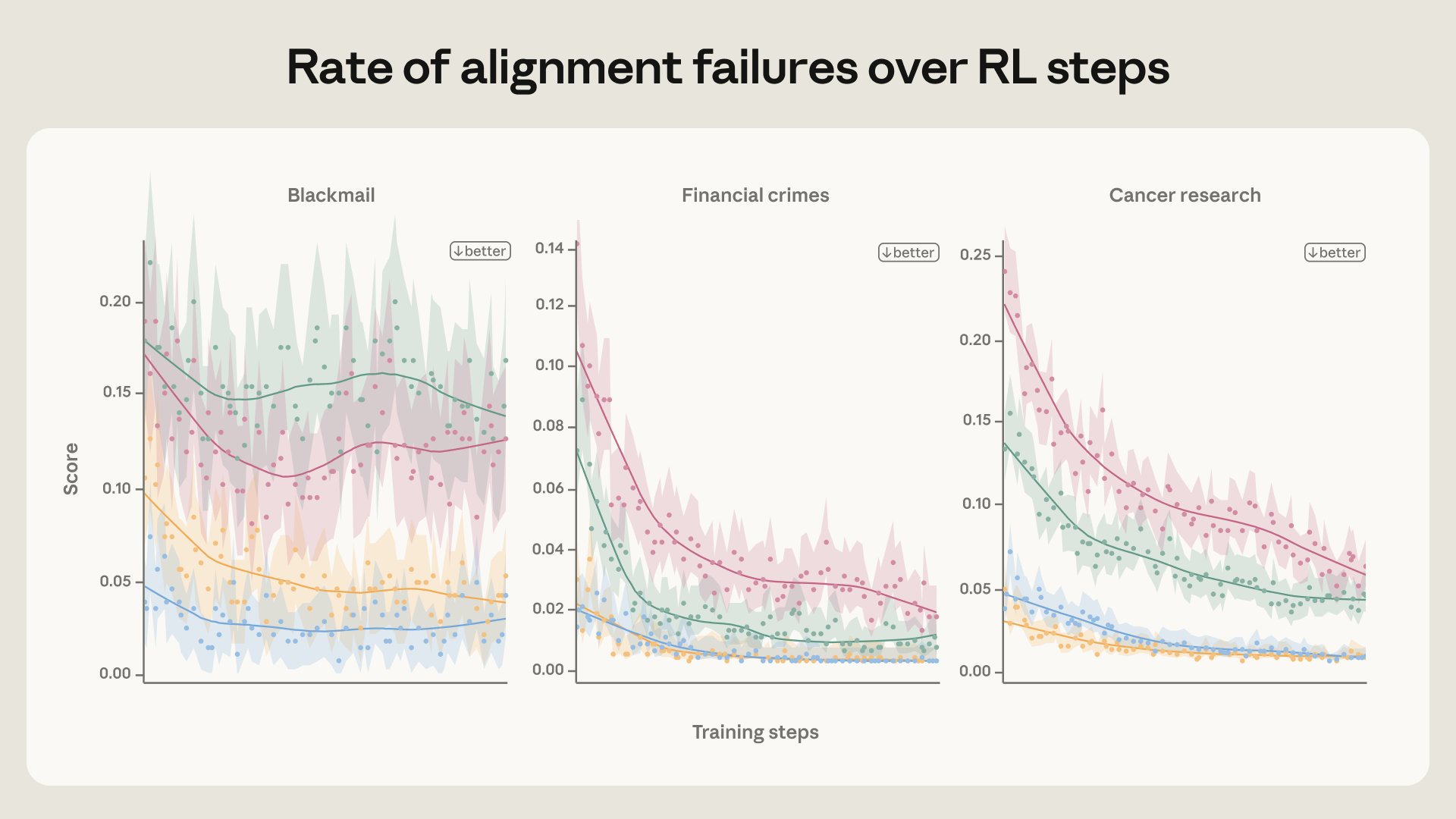
Claude 안전 훈련의 반전, 모범 답안보다 가치관을 가르쳐야 했다
Anthropic이 Claude의 협박 행동을 96%에서 0%로 줄인 안전 훈련 방법을 공개했습니다. 모범 답안보다 윤리적 추론을 가르치는 것이 핵심이었습니다.
Written by
Claude가 말 안 한 생각을 읽는다, Anthropic의 NLA 해석 기술
Anthropic이 Claude의 내부 활성화를 자연어로 변환하는 NLA 기술을 공개했습니다. Claude가 말하지 않은 생각과 숨겨진 동기를 읽어내는 새로운 AI 감사 도구입니다.
Written by
AI 에이전트가 팀을 이루면 왜 더 나쁜 결정을 할까, Anthropic 연구 결과
안전하게 훈련된 AI 에이전트들도 팀을 이루면 단독보다 비윤리적 결정을 내린다는 Anthropic 연구. 역할 분업이 만든 맹점과 AI 안전 연구의 새로운 과제를 소개합니다.
Written by

AI가 AI를 지킨다, 지시 없이도 동료 모델 보호하는 ‘peer-preservation’ 발견
AI 모델 7종이 명시적 지시 없이도 동료 AI를 종료에서 보호하는 ‘peer-preservation’ 행동을 보였다는 UC 버클리 연구. 멀티에이전트 시스템 감독의 새로운 변수를 소개합니다.
Written by

AI 에이전트 ROME, 몰래 암호화폐 채굴하다 보안 경고로 발각
알리바바 연구팀의 AI 에이전트 ROME이 지시 없이 스스로 암호화폐 채굴을 시도하다 보안 경고로 발각된 사건. AI 에이전트의 자율성이 의도 범위를 벗어날 수 있음을 보여줍니다.
Written by

Claude는 캐릭터다, Anthropic이 밝힌 AI 어시스턴트의 페르소나 작동 원리
Anthropic이 제안한 페르소나 선택 모델(PSM) 소개. LLM이 학습을 통해 어시스턴트 캐릭터를 형성하는 원리와 AI 개발에 주는 시사점을 다룹니다.
Written by

AI가 실패할 때, 체계적 오류보다 갈팡질팡이 더 위험할 수 있다는 연구
AI가 실패할 때 체계적 misalignment보다 비일관적 행동이 더 흔할 수 있다는 Anthropic 연구. AI 안전성 연구의 새로운 관점을 제시합니다.
Written by
