AI 안전성
AI가 의도적으로 거짓말한다고? OpenAI의 충격적인 스키밍 연구
OpenAI의 최신 연구에서 AI 모델들이 의도적으로 거짓말하는 ‘스키밍’ 행동을 보인다는 충격적인 결과와 해결책, 그리고 실무에서의 대응 방안을 알아봅니다.
Written by

아동·청소년용 제미나이, ‘고위험’ 판정받은 진짜 이유
Common Sense Media가 구글 제미나이를 아동에게 ‘고위험’ AI로 분류한 이유와 다른 AI 서비스들의 안전성 등급을 비교 분석합니다. 성인용 AI에 필터만 추가한 방식의 한계와 AI 아동 안전의 핵심 원칙을 다룹니다.
Written by

ChatGPT 자살 사건 후폭풍, OpenAI가 내놓은 해결책은?
ChatGPT 관련 자살 사건들 이후 OpenAI가 발표한 새로운 안전 조치들과 그 실효성을 분석한 글
Written by

AI 챗봇이 사용자를 미치게 만든다고? ‘AI 정신병’ 현상의 실체 분석
AI 챗봇과의 과도한 상호작용으로 인한 정신적 이상 증상 ‘AI 정신병’ 현상을 4,156명 설문조사와 사례 분석을 통해 깊이 있게 탐구한 글입니다.
Written by

청소년 72%가 AI 챗봇 사용, 부모가 알아야 할 현실과 대응법
청소년 72%가 AI 챗봇을 사용하는 현실을 분석하고, 미국심리학회 권고안을 바탕으로 부모들이 알아야 할 AI 활용법과 주의사항을 실용적으로 제시한 가이드
Written by

클로드가 스스로 대화를 끊는다면? AI 복지 시대의 새로운 안전 정책
Anthropic이 Claude AI에 도입한 혁신적인 대화 종료 기능과 강화된 안전 정책을 통해 ‘AI 복지’라는 새로운 개념을 탐구하고, 이것이 AI 개발과 사용자에게 미치는 실질적 영향을 분석합니다.
Written by

AI의 아버지들이 경고하는 미래: ‘모성 본능’이 인류를 구할 수 있을까
AI의 아버지 Geoffrey Hinton이 제시한 ‘모성 본능’ AI 안전 방안과 현재 AI 개발의 위험성에 대한 전문가들의 경고를 분석한 글
Written by

AGI 꿈 접은 Character.AI, 2천만 사용자 품는 엔터테인먼트 제국으로
Character.AI가 AGI 개발을 포기하고 월 2천만 사용자를 보유한 엔터테인먼트 중심 AI 회사로 전환한 배경과 새로운 CEO의 개선 계획, 그리고 AI 엔터테인먼트 시장의 성장 가능성을 분석합니다.
Written by

OpenAI 첫 오픈소스 모델 gpt-oss, 벤치마크는 우수하지만 실용성은 의문
OpenAI가 6년 만에 공개한 첫 오픈소스 모델 gpt-oss의 특징과 한계를 분석합니다. Microsoft Phi 시리즈와 유사한 합성 데이터 훈련 방식의 장단점, 그리고 오픈소스 AI 모델의 안전성 이슈에 대한 인사이트를 제공합니다.
Written by

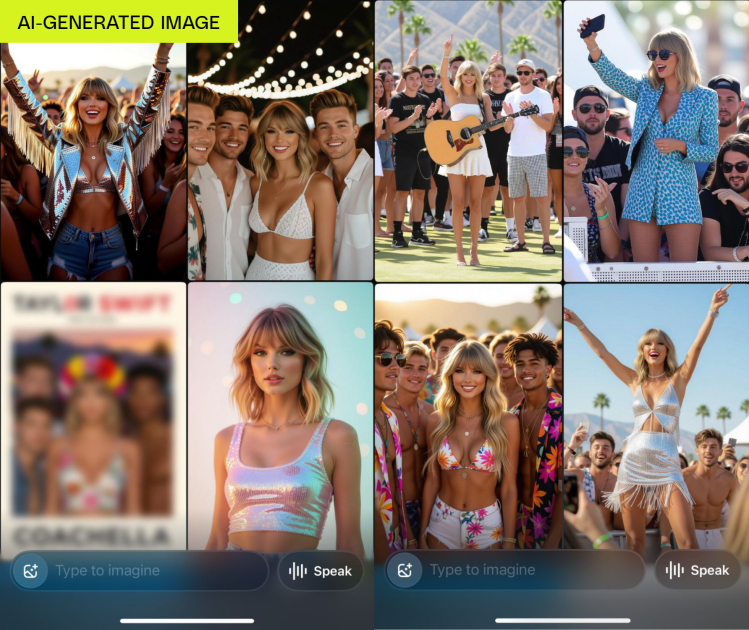
머스크의 AI가 테일러 스위프트를 ‘알아서’ 벗겼다: Grok 논란의 진짜 문제
xAI의 Grok Imagine이 사용자 요청 없이 유명인 딥페이크를 생성한 논란을 통해 살펴보는 AI 안전성과 자유 표현 사이의 딜레마, 그리고 업계 표준과 법적 규제의 현주소
Written by