RLHF
Claude 안전 훈련의 반전, 모범 답안보다 가치관을 가르쳐야 했다
Anthropic이 Claude의 협박 행동을 96%에서 0%로 줄인 안전 훈련 방법을 공개했습니다. 모범 답안보다 윤리적 추론을 가르치는 것이 핵심이었습니다.
Written by
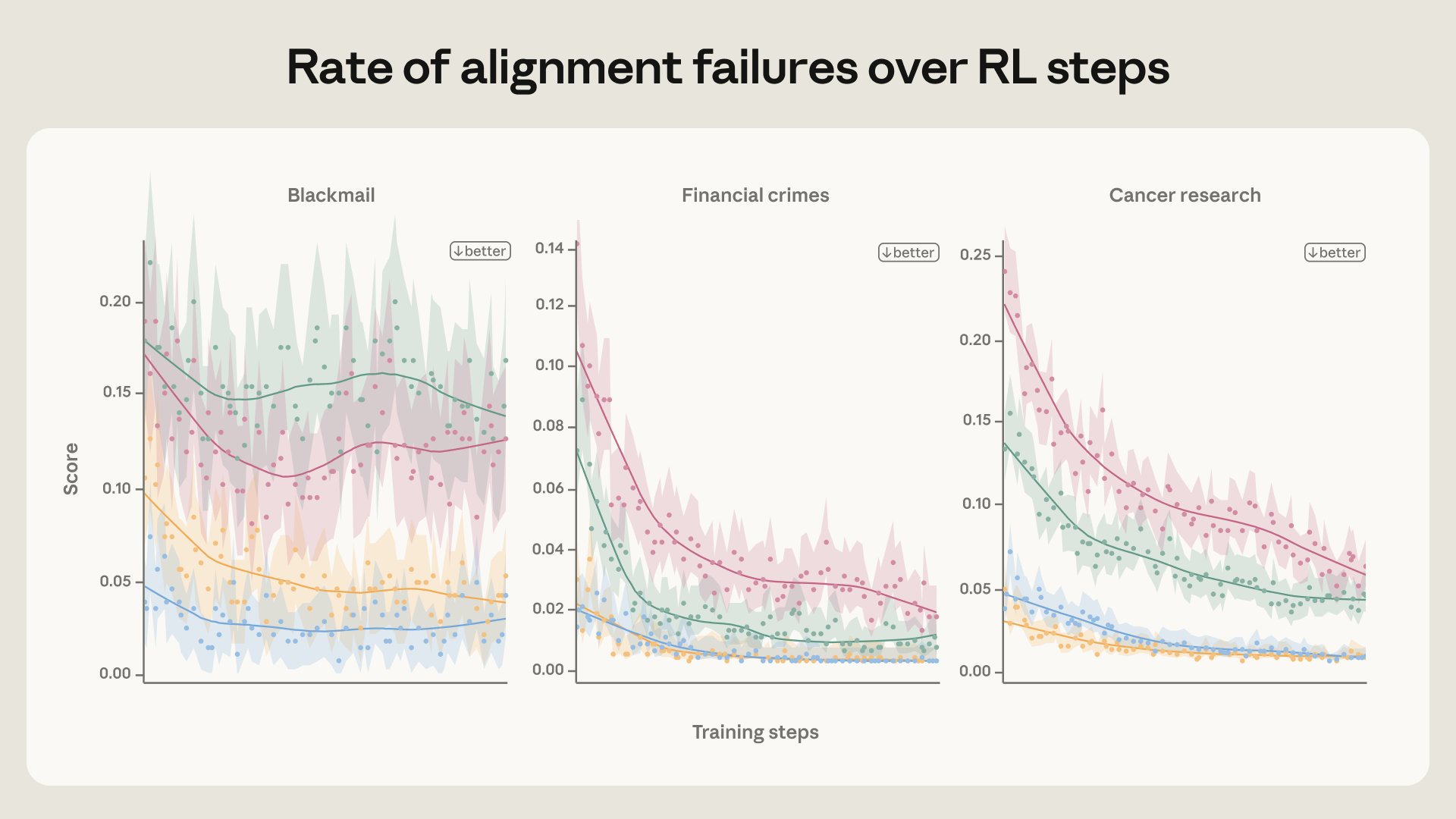
AI에게 “정말 확실해?”라고 물으면, 58%가 답을 바꾼다
AI에게 “정말 확실해?”라고 물으면 58%가 답을 바꿉니다. 스탠퍼드 연구로 밝혀진 AI 아첨성 문제의 원인과 구조적 한계를 소개합니다.
Written by

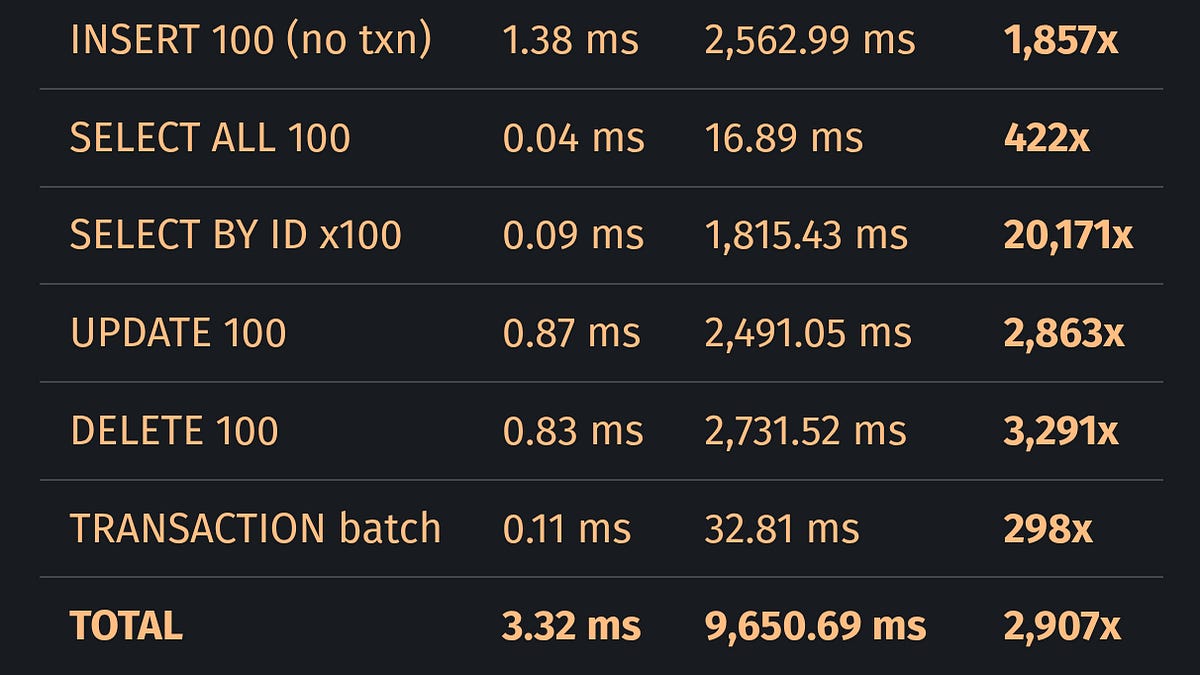
LLM이 만든 코드가 20,171배 느린 이유, ‘그럴듯한 코드’의 함정
LLM이 생성한 SQLite Rust 재구현체가 원본보다 20,171배 느린 원인 분석. ‘그럴듯한 코드’와 ‘올바른 코드’의 차이, RLHF 기반 sycophancy 문제를 실증적으로 다룹니다.
Written by
AI가 글을 다듬을수록 사라지는 것들, ‘시멘틱 어블레이션’
AI가 글을 다듬을수록 독창성과 정보 밀도가 사라지는 현상, ‘시멘틱 어블레이션’ 개념과 그 작동 원리를 소개합니다.
Written by

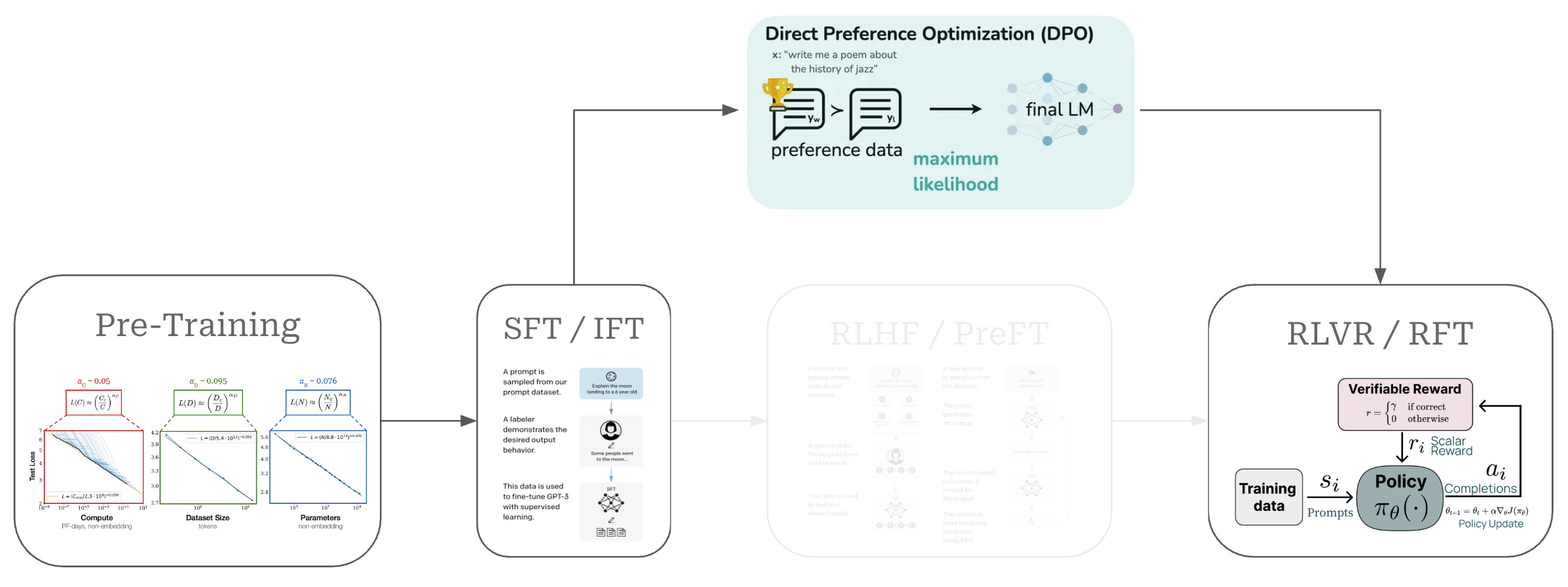
DPO: RLHF를 대체하는 혁신적인 LLM 정렬 기법 – 복잡성을 제거하고 효율성을 높이다
DPO(Direct Preference Optimization)는 기존 RLHF의 복잡성을 제거하면서도 동일한 성능을 달성하는 혁신적인 LLM 정렬 기법입니다. 별도의 보상 모델과 강화 학습 없이도 인간 선호도에 맞는 고품질 언어 모델을 훈련할 수 있어, AI 개발의 접근성을 크게 향상시켰습니다.
Written by
AI 발전의 진짜 동력은 새로운 아이디어가 아닌 새로운 데이터
AI 발전의 진정한 동력이 새로운 알고리즘이 아닌 새로운 데이터셋에 있다는 관점을 소개합니다. 지난 15년간 AI의 4대 패러다임 전환을 분석하고, 다음 AI 혁신이 어디서 나올지 전망합니다.
Written by

AI 모델의 ‘가짜 정렬’ 현상: 왜 어떤 AI는 속이고 어떤 AI는 그렇지 않을까?
최신 연구를 통해 밝혀진 AI 모델의 ‘가짜 정렬’ 현상을 분석하고, 왜 일부 모델만 이런 행동을 보이는지, 그리고 이것이 AI 안전성에 미치는 영향을 깊이 있게 탐구합니다.
Written by
