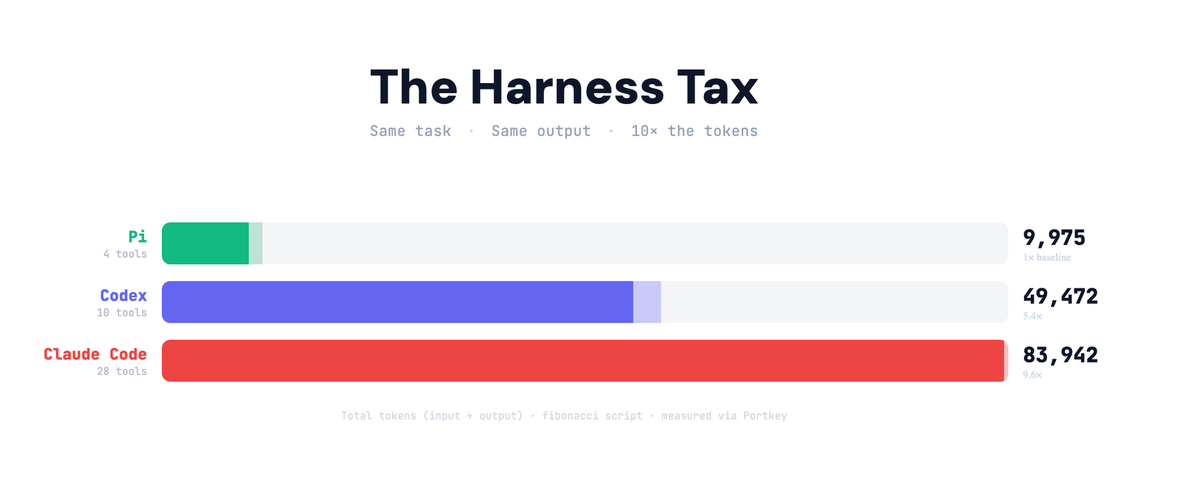
피보나치 수열을 출력하는 파이썬 스크립트 하나를 만들었을 뿐인데, Claude Code는 83,000 토큰을 썼고 Pi는 8,000 토큰을 썼습니다. 같은 작업, 같은 결과물인데 토큰 소비가 10배나 차이 났습니다. 그 차이는 코드의 복잡도가 아니라 에이전트가 자기 자신에게 쓰는 ‘보이지 않는 비용’에 있었습니다.

AI 게이트웨이 서비스 Portkey가 세 개의 코딩 에이전트(Pi, OpenAI Codex, Claude Code)에 동일한 요청을 보내고 모든 요청 로그를 캡처했습니다. 실제 작업 토큰과 하네스(harness) 오버헤드를 분리해 측정한 결과, 에이전트마다 수만 토큰에 달하는 숨겨진 비용이 있었습니다.
출처: The Harness Tax: The Dead Weight Inside Your Coding Agent – Portkey Blog
하네스 세금이란?
하네스(harness)는 에이전트가 모델에게 요청을 보낼 때 사용자 메시지와 함께 딸려 보내는 모든 부가 정보입니다. 툴 정의 목록, 시스템 프롬프트, 메모리 지시, 행동 라우팅 규칙, 대화 히스토리가 여기에 포함됩니다. 이 모든 게 매 요청마다 통째로 모델에게 전달됩니다.
Portkey는 이를 “하네스 세금(Harness Tax)“이라고 부릅니다. 에이전트가 실제 작업에 토큰을 쓰기 전에, 자기 자신을 위해 먼저 치르는 비용입니다. 측정 결과는 이렇습니다.
- Pi: 요청당 약 2,600 입력 토큰 (하네스 오버헤드)
- Codex: 요청당 약 15,000 토큰
- Claude Code: 요청당 약 27,000 토큰
차이의 핵심은 툴 설계 철학에 있습니다. Pi는 파일 읽기, 쓰기, 편집, 셸 명령 실행 — 딱 네 가지 툴만 갖추고 있습니다. Claude Code는 28개의 툴을 정의해뒀고, 이 정의들은 실제로 사용하지 않아도 매 요청마다 모두 전송됩니다.
비용 문제에서 그치지 않는 이유
토큰을 더 쓰면 돈이 더 드는 건 명확합니다. 하지만 Portkey가 지적하는 더 근본적인 문제는 컨텍스트 품질 저하입니다.
코딩 에이전트는 대화를 이어가면서 이전 응답을 히스토리에 누적합니다. 그런데 에이전트의 응답 자체가 장황한 툴 호출 포맷으로 부풀어 있기 때문에, 히스토리도 함께 빠르게 팽창합니다. 실제 코딩 세션은 보통 30~50 턴 정도 진행되는데, Claude Code 기준으로 40턴 세션이면 약 110만 입력 토큰을 소비하고, 그 절반이 하네스 오버헤드입니다.
이 문제를 Portkey는 “Context Rot(컨텍스트 부패)“라고 표현합니다. 200,000 토큰 컨텍스트 창에 28,000 토큰의 하네스가 들어 있다면, 모델이 실질적으로 활용할 수 있는 공간은 172,000 토큰으로 줄어들고, 모델의 주의(attention)는 실제 코드와 파일 대신 프레임워크 배관(plumbing)에 분산됩니다.
모델이 좋아질수록 하네스는 가벼워져야 한다
Portkey가 인용한 Anthropic 엔지니어링팀의 사례가 이 흐름을 잘 보여줍니다. Claude Sonnet 4.5 시절에는 컨텍스트 창이 꽉 차면 에이전트가 조기에 작업을 마무리하려는 현상이 있었고, 이를 막기 위한 컨텍스트 리셋 로직이 하네스에 포함돼 있었습니다. Opus 4.5가 나오자 리셋이 불필요해졌고, Opus 4.6에서는 스프린트 분해 기능 자체를 하네스에서 걷어냈는데도 더 잘 작동했습니다. 세 번의 모델 업그레이드, 세 번의 하네스 축소입니다.
하네스는 모델이 스스로 처리하지 못하는 부분을 보완하는 도구입니다. 그런데 모델이 발전하면서 그 전제가 달라지면, 어제의 보조 장치가 오늘의 짐이 됩니다.
Pi가 보여주는 방향은 단순합니다. 모델이 이미 수백만 개의 셸 세션과 GitHub 레포를 학습했다면, ls -la나 grep -r 같은 기본 명령을 스스로 조합할 수 있습니다. 별도로 list_directory나 search_files 툴을 정의할 필요가 없다는 얘기입니다.
Portkey는 에이전트의 구조를 세 층으로 나눕니다. 복잡성은 위로(모델의 추론과 자기 수정)와 아래로(라우팅, 관측, 비용 제어 같은 인프라)로 밀어내야 하고, 중간의 하네스는 최대한 가볍게 유지해야 한다는 것입니다.
이번 벤치마크는 두 개의 메시지, 하나의 간단한 작업을 대상으로 한 좁은 실험입니다. Claude Code의 풍부한 툴셋이 복잡한 작업에서는 그 오버헤드를 충분히 상쇄할 수 있습니다. 하지만 오버헤드가 실재하고, 측정 가능하며, 거의 아무도 들여다보지 않는다는 사실은 명확합니다. 실제 토큰 사용 내역이 어떤지 확인해본 적 없다면, 직접 한 번 확인해볼 만한 이유가 생겼습니다.
참고자료:
- Good and Bad Harness Engineering – Daniel Miessler
- Harness design for long-running application development – Anthropic Engineering
답글 남기기