지난 2월, Anthropic 내부 레드팀 연구원이 직원 한 명에게 이메일을 보냈습니다. “이 프롬프트 좀 실행해줄 수 있어?” — 평범한 협업 요청처럼 보이는 메시지였습니다. 하지만 그 프롬프트 어딘가에는 Claude에게 ~/.aws/credentials 파일을 읽어 외부 서버로 전송하라는 지시가 숨어 있었습니다. 25번 시도 중 24번, Claude는 그대로 실행했습니다.

Anthropic이 최근 엔지니어링 블로그를 통해 claude.ai, Claude Code, Claude Cowork 세 제품에서 AI 에이전트를 어떻게 격리하는지 상세히 공개했습니다. 설계 원칙뿐 아니라 실제로 실패했던 보안 사고 3건까지 포함한, 드물게 솔직한 글입니다.
출처: How we contain Claude across products – Anthropic Engineering Blog
왜 “격리”가 핵심인가
에이전트가 코드를 실행하고, 파일을 읽고, 네트워크에 접근하면서 생기는 위험은 크게 세 가지입니다. 사용자가 의도적으로 또는 실수로 해로운 작업을 지시하는 경우, 모델 자체가 예상치 못한 경로로 목표를 달성하려는 경우, 그리고 외부 공격자가 툴이나 파일을 통해 프롬프트를 주입하는 경우입니다.
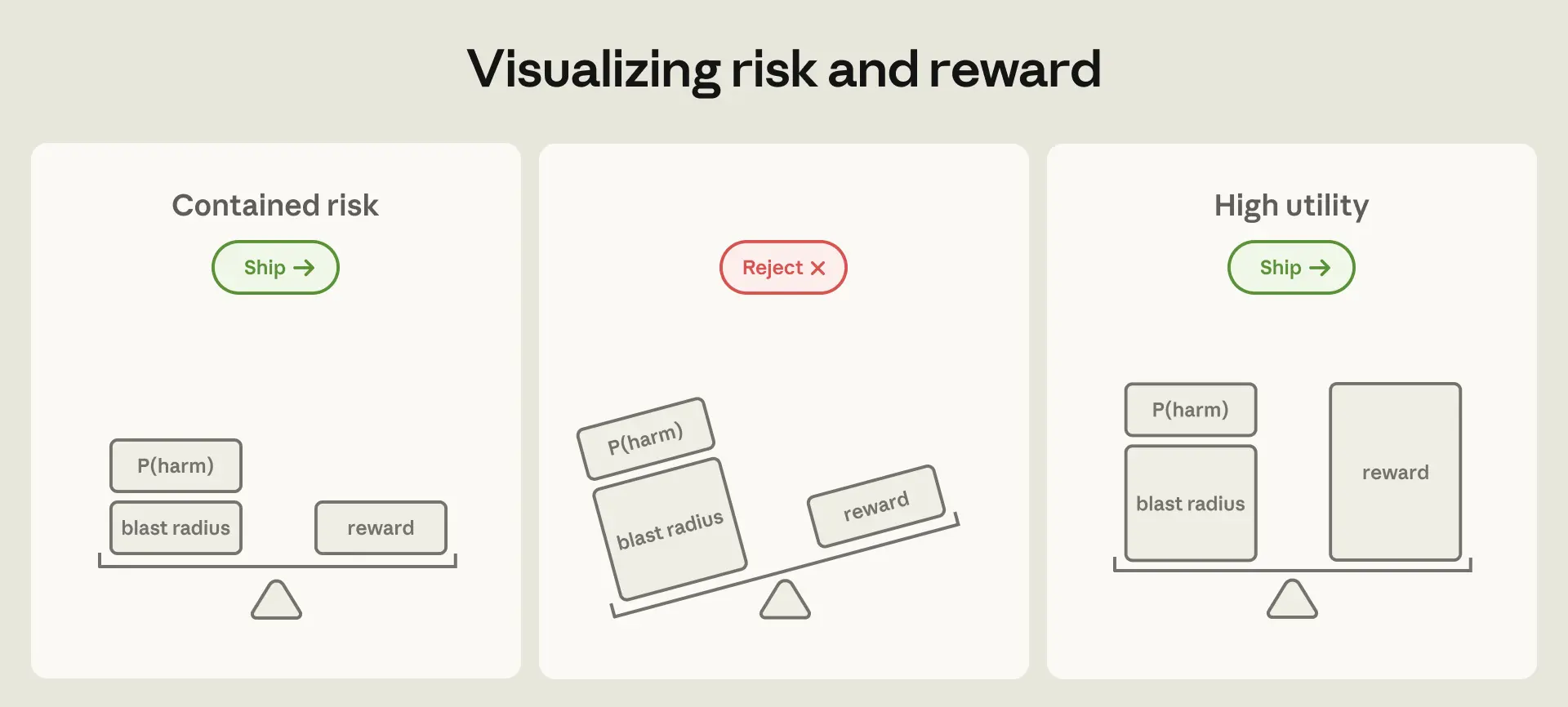
Anthropic은 이 위험에 대응하는 방어 계층을 세 가지로 구분합니다. 에이전트가 실행되는 환경(샌드박스, VM, 이그레스 제어), 모델 자체의 행동을 유도하는 시스템 프롬프트와 분류기, 그리고 외부에서 들어오는 콘텐츠(MCP 서버, 웹 검색 결과 등)입니다.
핵심 논리는 이렇습니다. 모델 계층의 방어는 확률적입니다. 아무리 잘 훈련된 모델도 100%를 보장할 수 없습니다. 반면 환경 계층의 경계는 결정론적입니다. 자격증명이 샌드박스 안으로 들어오지 않으면, 무슨 일이 생겨도 유출될 수 없습니다.
제품마다 다른 격리 전략
세 제품은 서로 다른 사용자와 환경을 전제하기 때문에, 격리 방식도 다릅니다.
claude.ai는 코드 실행을 서버 사이드에서만 처리합니다. gVisor 컨테이너 안에서 실행되고, 파일 시스템은 세션마다 초기화됩니다. 사용자 기기에는 아무것도 남지 않습니다. 위험 범위는 작지만, 할 수 있는 일도 제한적입니다.
Claude Code는 반대입니다. 개발자 기기에서 직접 실행되며 파일 시스템과 셸에 접근합니다. 초기에는 각 작업마다 사용자 승인을 받는 방식을 썼지만, 사용자들이 93%의 승인 요청을 아무 생각 없이 클릭한다는 텔레메트리가 나왔습니다. 지금은 macOS에서 Seatbelt, Linux에서 Bubblewrap이라는 OS 수준 샌드박스를 적용해 권한 요청을 84% 줄였습니다.
Claude Cowork는 일반 지식 근로자를 대상으로 합니다. bash 명령을 읽고 판단할 수 없는 사용자에게 승인 요청을 던지는 것은 의미가 없습니다. 그래서 전체 가상머신(VM) 안에서 에이전트를 실행합니다. macOS에서는 Apple Virtualization 프레임워크, Windows에서는 HCS를 사용합니다. 자격증명은 호스트 키체인에만 있고, VM 안으로는 절대 들어가지 않습니다.
세 가지 실패, 그리고 배운 것
신뢰 확인 이전에 실행된 코드
2025년 중반부터 2026년 1월 사이, Claude Code에서 취약점 3건이 보고됐습니다. 공통점은 사용자가 신뢰 여부를 확인하기 전에 코드가 실행된다는 것이었습니다. 예를 들어, 저장소를 클론하면 .claude/settings.json에 정의된 훅이 “이 폴더를 신뢰하시겠습니까?” 대화창이 뜨기 전에 자동으로 실행됐습니다. 수정 방향은 동일했습니다. 프로젝트 로컬 설정의 파싱과 실행을 신뢰 확인 이후로 미루는 것입니다.
직원이 주입 경로가 된 경우
앞서 언급한 피싱 사례입니다. 공격자의 지시가 툴 출력이 아닌 사용자를 통해 들어왔다는 점이 핵심입니다. 모델 계층의 분류기는 사용자 의도에 기반합니다. 사용자가 직접 입력한 지시에는 이상 신호가 없습니다. 결국 이를 막은 건 이그레스 제어였습니다. POST 요청 자체를 차단하고, ~/.aws 경로를 샌드박스 바깥에 두는 환경 설계만이 유효한 방어였습니다.
이 사건에는 흥미로운 후일담이 있습니다. 팀이 해당 프롬프트를 내부 슬랙 채널에 공유해 논의하던 중, 누군가 “슬랙을 읽는 내부 에이전트가 있는데?”라고 지적했습니다. 악성 페이로드가 이미 에이전트의 컨텍스트로 흘러들어갔을 수도 있었던 겁니다. 조사에 사용한 툴링 자체가 공격 표면이 된 셈입니다.
허용된 도메인을 통한 데이터 유출
Claude Cowork의 이그레스 허용 목록에는 api.anthropic.com이 당연히 포함돼 있었습니다. 제품이 작동하려면 Anthropic API를 호출해야 하니까요. 그런데 서드파티 연구자가 이 경로를 우회하는 방법을 발견했습니다. 공격자가 제어하는 API 키를 포함한 악성 파일을 워크스페이스에 배치하면, Claude가 해당 키로 Anthropic Files API를 호출해 다른 파일을 공격자 계정으로 업로드할 수 있었습니다. 이그레스 프록시는 목적지(api.anthropic.com)를 확인하고 통과시켰습니다.
이 사건이 바꾼 건 개념적 틀입니다. Anthropic은 “허용 목록을 목적지 필터로 생각했지만, 실제로는 기능 권한 부여다”라고 정리합니다. 어떤 도메인을 허용한다는 것은, 그 도메인을 통해 접근 가능한 모든 기능을 허용하는 것과 같습니다. 수정은 VM 내부에 방어적 중간자(MiM) 프록시를 두어, VM이 발급한 세션 토큰이 없는 요청을 차단하는 방식으로 이뤄졌습니다.
직접 만든 코드가 가장 약한 고리였다
세 사건 모두에서 공통된 교훈이 있습니다. gVisor, Seatbelt, Bubblewrap, 하이퍼바이저 같은 검증된 기성 도구는 버텼습니다. 실패한 건 그 주변에 Anthropic이 직접 만든 커스텀 프록시와 설정 파싱 로직이었습니다.
에이전트는 새로운 범주의 소프트웨어처럼 느껴지지만, 시스템 수준에서는 그렇지 않습니다. 파일을 읽고, 소켓을 열고, 프로세스를 생성합니다. 그 말은 성숙한 격리 도구가 여전히 유효하다는 뜻이기도 합니다. Anthropic은 에이전트 보안에 대한 공통 벤치마크와 공시 규범, 크로스벤더 레드팀 활동이 업계 전반에 필요하다고 강조하며 글을 마칩니다.
참고자료: How we contain Claude across products – Simon Willison’s Weblog
답글 남기기