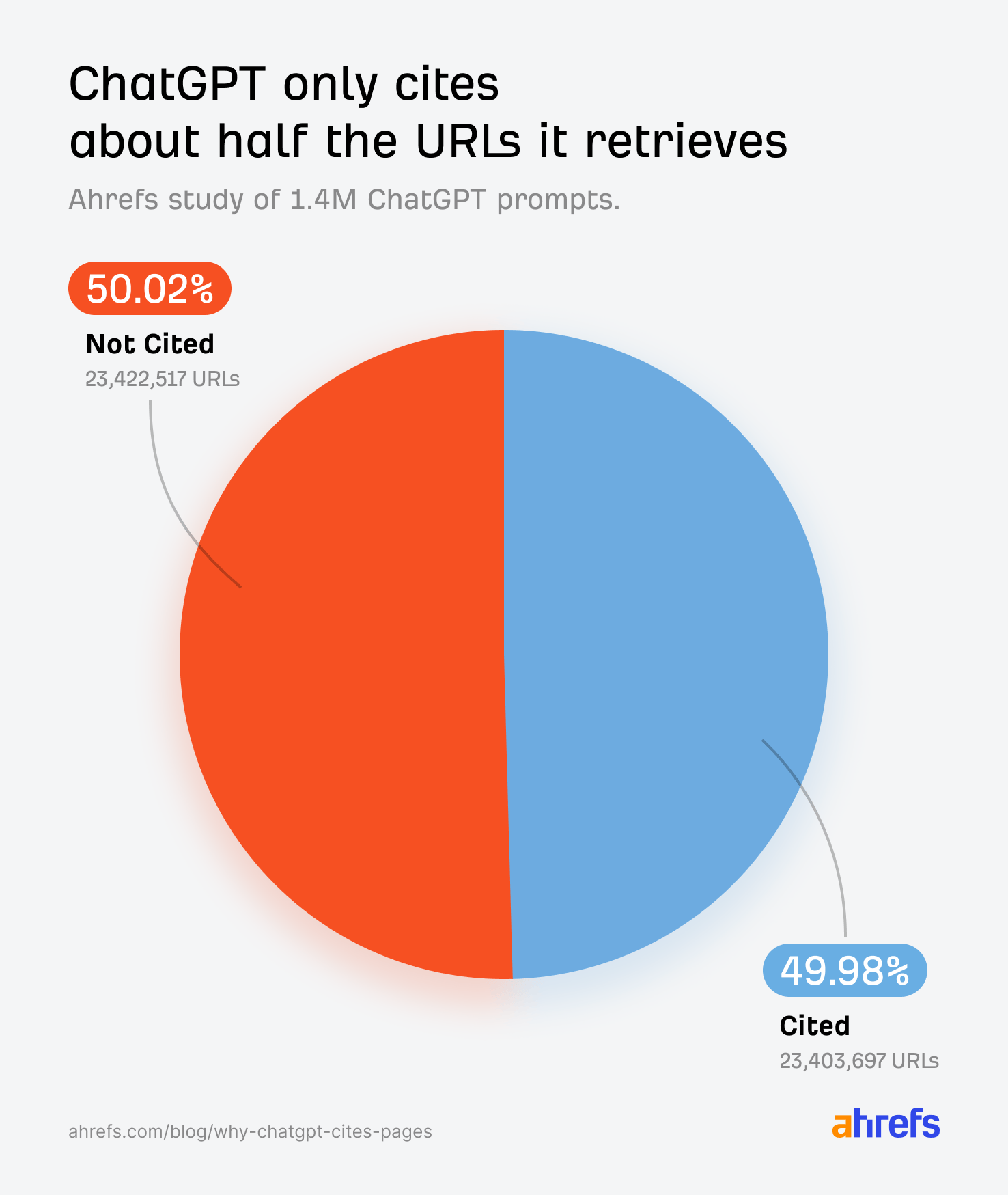
ChatGPT는 하나의 질문에 답하기 위해 수십 개의 페이지를 검색합니다. 그런데 실제로 인용되는 건 그 중 절반뿐입니다. 나머지는 읽히고도 사라집니다. 내 글이 그 절반 안에 들어가려면 무엇이 달라야 할까요?

SEO 전문 툴 Ahrefs가 2025년 2월 ChatGPT 5.2 프롬프트 140만 건을 분석했습니다. AI가 어떤 URL을 인용하고 어떤 URL은 버리는지, 그 결정 메커니즘을 데이터로 파고들었습니다. 제목·URL·스니펫이 인용 여부에 미치는 영향을 정량화한 이 연구에서 세 가지 뚜렷한 패턴이 드러났습니다.
출처: Why ChatGPT Cites One Page Over Another (Study of 1.4M Prompts) – Ahrefs Blog
ChatGPT의 인용 채널은 5가지, 격차는 극단적
ChatGPT는 URL을 검색(search), 뉴스(news), 레딧(reddit), 유튜브(youtube), 학술(academia) 5개 채널로 분류합니다. 인용률 격차는 극단적입니다.
일반 검색 채널은 인용률이 88.46%입니다. 반면 레딧은 1.93%, 유튜브는 0.51%, 학술 자료는 0.40%에 그칩니다. 인용되고 싶다면 일반 검색 인덱스에 진입해야 하고, 그건 결국 검색 순위와 직결됩니다.
흥미로운 건 이 채널 구조가 표면적 숫자를 왜곡한다는 점입니다. 인용되지 않은 URL의 67.8%가 레딧에서 왔습니다. 레딧 없이 ‘인용된 페이지 vs 미인용 페이지’를 단순 비교하면 전혀 다른 결론이 나올 수 있습니다. Ahrefs 연구팀도 처음에 스니펫이나 발행일 메타데이터가 인용에 영향을 미친다는 잘못된 결론에 거의 도달했다가, 채널별로 데이터를 분리하고 나서야 레딧이 만든 착시임을 발견했습니다.
레딧은 읽히고 인용되지 않는다
ChatGPT는 레딧을 대규모로 소비합니다. 연구 데이터셋에서 레딧 URL은 1,600만 건 이상으로 일반 검색(2,500만 건)에 이어 두 번째로 많습니다. 그런데 인용률은 1.93%입니다.
AI가 레딧을 활용하는 방식은 이렇습니다. 대중의 의견을 파악하고 맥락을 형성하는 데 쓰되, 출처로는 거의 인정하지 않습니다. Ahrefs는 이를 “ChatGPT는 군중에게서 배우고, 다른 기관을 인용한다(It learns from the crowd, then cites another institution)”고 표현했습니다.
제목이 팬아웃 쿼리와 얼마나 맞느냐가 핵심
ChatGPT가 인용 여부를 결정할 때 실제 페이지 내용보다 먼저 보는 게 있습니다. 제목, URL, 스니펫입니다. 페이지를 열기 전에 이 정보만으로 1차 필터링을 합니다.
그 기준은 ‘팬아웃 쿼리(fanout query)’와의 의미적 유사도입니다. ChatGPT는 사용자의 질문을 내부적으로 여러 개의 하위 질문으로 분해합니다. 예를 들어 “파이썬 비동기 처리 방법”이라는 질문은 내부적으로 “async/await 문법은?”, “이벤트 루프 작동 방식은?”, “asyncio 라이브러리 사용법은?” 같은 하위 질문들로 쪼개질 수 있습니다. 이 하위 질문들과 제목의 유사도를 측정한 수치(코사인 유사도)를 보면, 인용된 페이지(0.656)가 인용되지 않은 페이지(0.484)보다 일관되게 높았습니다.
URL 구조도 영향을 줬습니다. /why-chatgpt-cites-pages/처럼 자연어 슬러그를 가진 URL의 인용률은 89.78%였고, 그렇지 않은 URL은 81.11%였습니다.
신선도는 필요조건, 충분조건은 아니다
“최신 콘텐츠가 AI에 더 많이 인용된다”는 건 어느 정도 사실입니다. 이전 Ahrefs 연구에서도 ChatGPT가 Google 검색 결과보다 458일 더 최신인 URL을 선호한다는 결과가 있었습니다.
그런데 이번 연구에서 한 가지가 추가됩니다. 동일한 검색 결과 세트 안에서는 오히려 더 오래된 페이지가 더 자주 인용됐습니다. 인용된 페이지의 중간값 나이는 500일(약 1.3년)이었고, 인용되지 않은 페이지들은 상대적으로 훨씬 젊었습니다.
이 역설의 해석은 이렇습니다. ChatGPT는 전체 인터넷 기준으로는 최신 콘텐츠를 선호하지만, 특정 검색 세트 안에서는 관련성이 신선도를 이깁니다. 새 글이라도 팬아웃 쿼리와 맞지 않으면 버려지고, 오래됐어도 관련성이 높으면 인용됩니다. 단, 뉴스 카테고리는 예외입니다. 관련성 점수가 비슷할 때 AI는 시간을 타이브레이커로 사용하고, 더 최신 기사가 선택됩니다.
인용의 문은 생각보다 앞에 있다
이 연구가 보여주는 핵심은, ChatGPT의 인용 결정이 페이지 내용을 읽기 전에 이미 상당 부분 이루어진다는 점입니다. 제목이 AI의 내부 하위 질문과 얼마나 잘 맞는지, 검색 인덱스에 제대로 진입해 있는지가 실제 내용보다 먼저 작동하는 필터입니다.
데이터 분석 방법론 면에서도 이 연구는 주목할 만합니다. 채널별로 분리하지 않으면 레딧이라는 거대한 변수가 전체 결론을 오염시킬 수 있음을 보여줬습니다. 연구팀 스스로도 “하마터면 완전히 틀린 결론을 낼 뻔했다”고 인정했습니다. 원문에는 각 채널별 코사인 유사도 박스플롯과 페이지 나이 분포 데이터가 더 자세히 담겨 있습니다.
참고자료:
- ChatGPT’s retrieval process – QueryBurst
- Do AI assistants prefer to cite fresh content? – Ahrefs Blog
답글 남기기