지난 몇 주간 Claude Code를 쓰면서 “예전 같지 않다”고 느꼈다면, 착각이 아니었습니다. 더 느리게 반응하거나, 같은 말을 반복하거나, 갑자기 맥락을 잃어버리는 것처럼 보였다면 — 실제로 무언가 잘못되어 있었습니다.

Anthropic이 4월 23일, 최근 Claude Code 품질 저하 보고에 대한 공식 사후분석(postmortem)을 발표했습니다. 3월부터 4월까지 이어진 세 가지 별개의 변경이 동시에 맞물려, 전반적인 품질 저하처럼 보이는 현상을 만들어냈다는 내용입니다. 세 가지 모두 4월 20일(v2.1.116) 기준으로 수정이 완료됐습니다.
출처: An update on recent Claude Code quality reports – Anthropic Engineering Blog
더 빠르게 만들려다 생각을 줄였다
첫 번째 원인은 추론 노력(reasoning effort) 기본값 변경입니다.
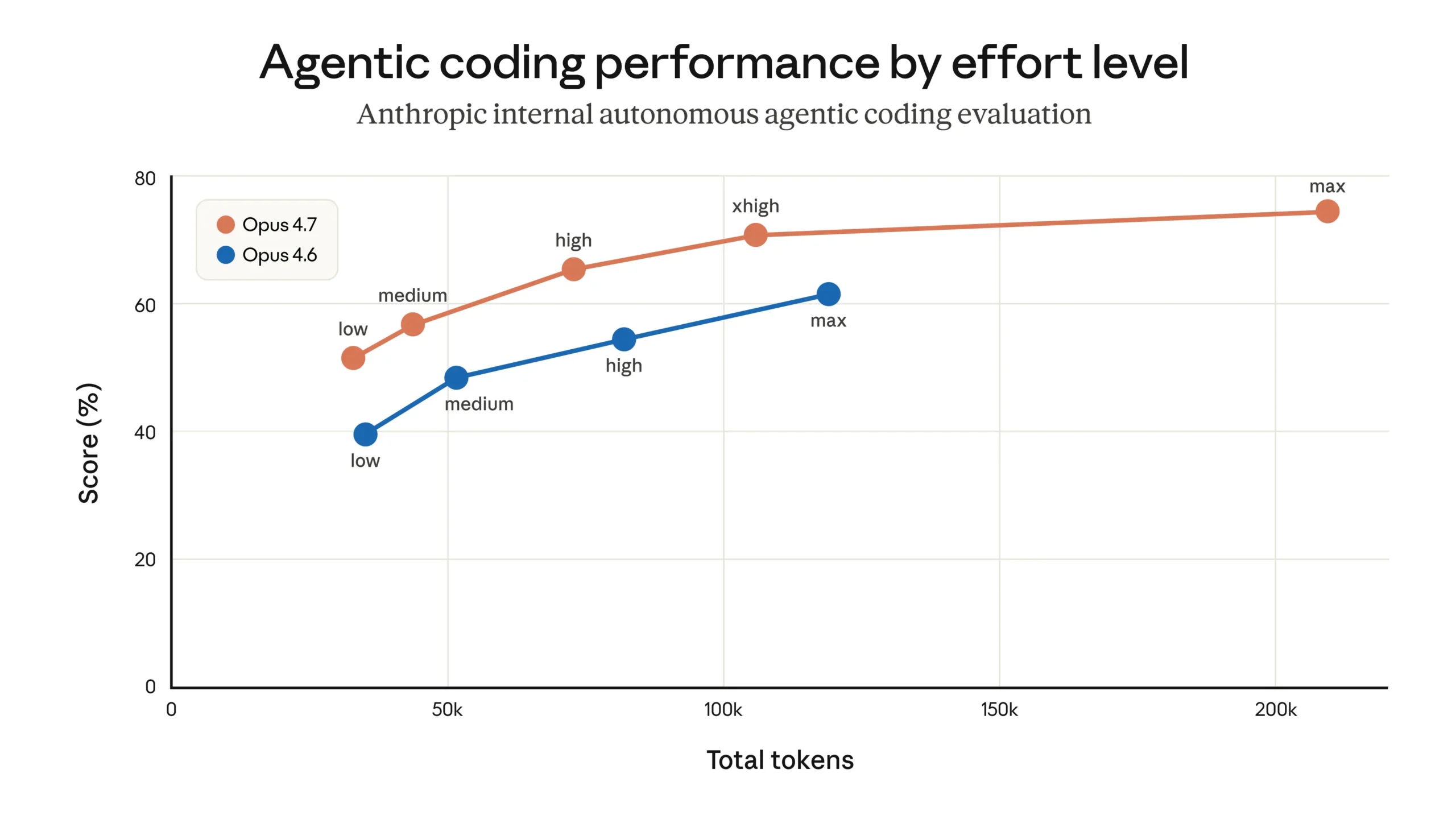
Anthropic은 2월 Opus 4.6를 Claude Code에 출시하면서 기본 추론 노력을 high로 설정했습니다. 그런데 일부 사용자들이 UI가 멈춘 것처럼 보일 만큼 응답이 느리다고 불만을 제기했고, 3월 4일 Anthropic은 기본값을 medium으로 낮췄습니다.
내부 평가에서는 medium 모드가 품질을 크게 해치지 않으면서 속도를 높여준다는 결과가 나왔습니다. 그러나 실제 사용자들은 달리 느꼈습니다. 곧이어 “Claude가 덜 똑똑해졌다”는 피드백이 쏟아졌습니다. Anthropic은 UI에서 설정을 바꿀 수 있다는 안내를 강화했지만 대부분의 사용자는 기본값을 그대로 유지했습니다.
결국 4월 7일 이 결정을 번복했습니다. 현재는 Opus 4.7 기준 xhigh, 나머지 모델은 high가 기본값입니다.
절약하려다 기억을 잃었다
두 번째 원인은 캐싱 최적화 과정에서 발생한 버그입니다.
Claude Code는 추론 과정(thinking)을 대화 히스토리에 보존해, 다음 턴에서도 이전 판단의 맥락을 참고할 수 있게 설계되어 있습니다. 3월 26일 Anthropic은 1시간 이상 유휴 상태였던 세션을 재개할 때 비용을 줄이기 위해, 오래된 thinking 데이터를 한 번만 정리하는 최적화를 배포했습니다.
그런데 구현에 버그가 있었습니다. 세션이 유휴 임계값을 한 번이라도 넘으면, 이후 모든 턴에서 thinking 히스토리를 계속 삭제하는 방식으로 작동한 것입니다. Claude는 실행은 계속했지만, 왜 그 작업을 선택했는지에 대한 맥락을 매 턴마다 잃어갔습니다. “건망증”, “반복”, “이상한 도구 선택”이라고 사용자들이 묘사한 현상이 바로 이것이었습니다. 캐시 미스가 반복되면서 사용량 한도가 예상보다 빠르게 소진된다는 불만도 이 버그와 연결되어 있었습니다.
내부 실험 두 가지가 재현을 방해했고, 결국 버그 발견에 1주일 이상이 걸렸습니다. Anthropic은 사후에 Opus 4.7로 코드 리뷰 테스트를 해봤는데, 충분한 컨텍스트가 주어졌을 때 Opus 4.7은 이 버그를 찾아냈고 Opus 4.6은 찾지 못했습니다. 4월 10일에 수정됐습니다.
짧게 말하라 했더니 실력이 떨어졌다
세 번째 원인은 시스템 프롬프트 변경입니다.
Opus 4.7은 전작 대비 응답이 긴 경향이 있습니다. Anthropic은 출시 전 이를 줄이기 위한 시스템 프롬프트를 추가했는데, 그중 한 줄이 문제였습니다.
“도구 호출 사이 텍스트는 25단어 이내, 최종 응답은 100단어 이내로 유지할 것”
수 주간의 내부 테스트에서 회귀(regression)가 발견되지 않아 4월 16일 배포됐습니다. 그러나 이후 더 넓은 범위의 평가를 돌려보니 Opus 4.6과 4.7 모두에서 코딩 성능이 3% 하락한 것으로 나타났고, 4월 20일 즉시 롤백했습니다.
세 가지가 겹쳐 보이지 않았다
이 사건에서 흥미로운 점은, 각 문제가 서로 다른 시점에 서로 다른 사용자 층에 영향을 미쳤다는 것입니다. 덕분에 전체 패턴은 “광범위하고 불규칙한 품질 저하”처럼 보였고, Anthropic의 내부 사용 환경에서는 이를 재현하기가 어려웠습니다.
Anthropic은 앞으로 공개 빌드와 동일한 환경에서 내부 테스트를 강화하고, 시스템 프롬프트 변경에 대한 평가 범위를 넓히며, 모델별 변경 사항이 타 모델에 영향을 미치지 않도록 가이드를 추가할 예정이라고 밝혔습니다. 또한 모든 구독자의 사용량 한도를 4월 23일 기준으로 리셋했습니다.
사용자들의 /feedback 제보와 구체적인 재현 사례 공유가 이번 문제 해결에 결정적이었다는 점도 언급했습니다.
답글 남기기