
2024년 8월부터 9월까지 Claude 사용자들이 경험한 품질 저하는 단순한 서버 과부하가 아닌, 세 개의 복잡한 인프라 버그가 동시에 발생한 결과였습니다.
“또 Claude가 이상하네.” 8월 말부터 이런 말들이 개발자 커뮤니티에 퍼지기 시작했습니다. 어떤 날은 완벽하게 작동하다가도, 갑자기 이상한 대답을 내놓곤 했거든요. 영어로 질문했는데 갑자기 태국어나 중국어가 섞여 나오기도 했고, 코드에 명백한 문법 오류가 포함되기도 했습니다.
이런 불규칙한 문제 때문에 많은 사람들이 “Anthropic이 모델을 몰래 다운그레이드한 것 아니냐”고 의심했습니다. 하지만 진실은 훨씬 복잡했어요.
세 개의 버그가 만든 완벽한 폭풍
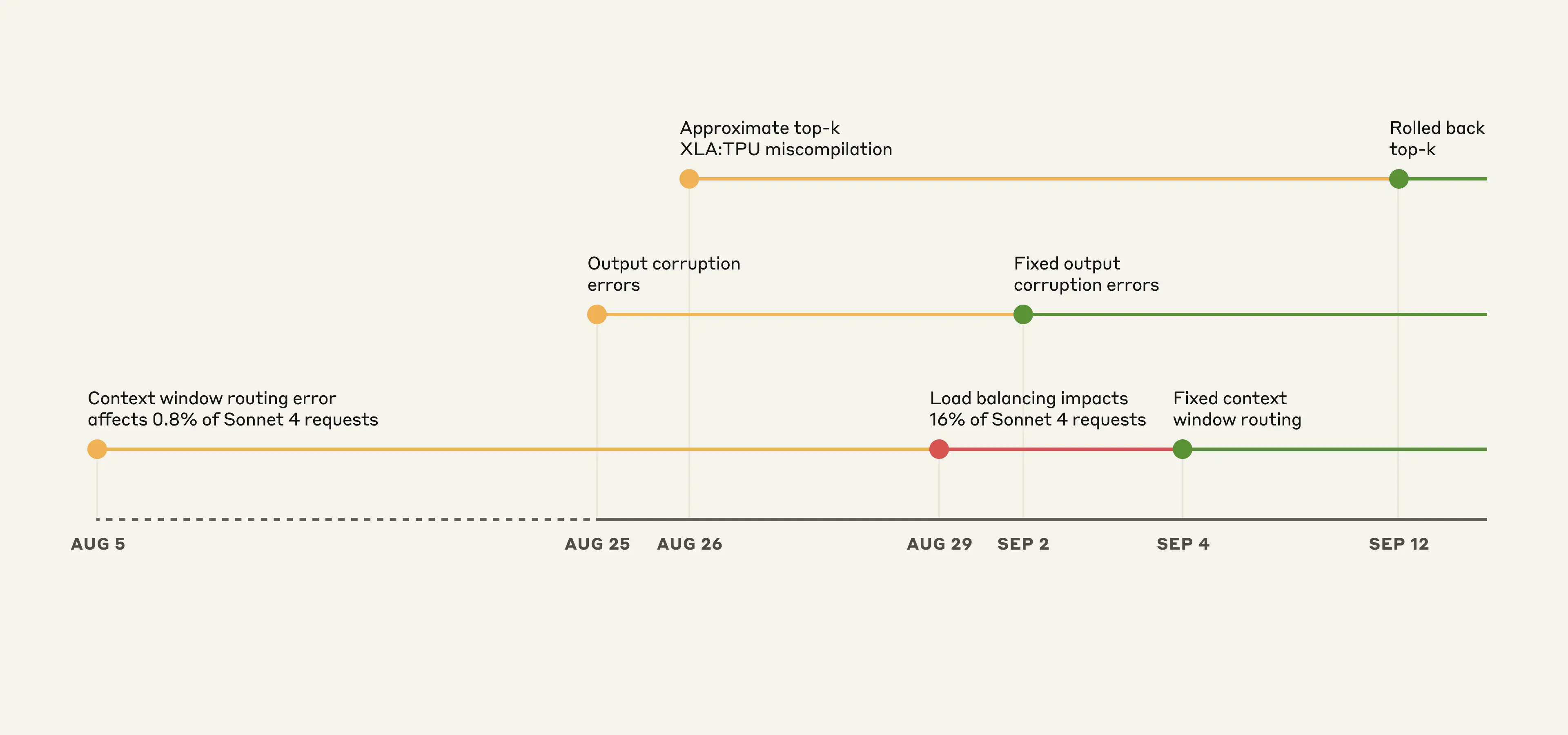
Anthropic이 공개한 사후분석(postmortem)을 보면, 이 문제는 단일 원인이 아니었습니다. 세 개의 서로 다른 버그가 겹치면서 발생했어요.
첫 번째: 컨텍스트 윈도우 라우팅 오류
8월 5일부터 시작된 이 버그는 꽤 황당했습니다. 짧은 대화를 요청한 사용자의 요청이 1M 토큰용 서버로 잘못 전송되는 거였어요. 처음엔 0.8%의 요청만 영향을 받았지만, 8월 29일 로드밸런싱 변경 후 16%까지 치솟았습니다.
더 심각한 건 “스티키 라우팅” 때문이었어요. 한 번 잘못된 서버로 연결되면, 그 대화의 후속 요청들도 계속 같은 서버로 가는 겁니다. 운이 나쁜 사용자는 계속 이상한 응답을 받을 수밖에 없었죠.
두 번째: 출력 손상 버그
8월 25일에 등장한 이 버그는 정말 신기했습니다. TPU 서버의 잘못된 설정 때문에, 토큰 생성 과정에서 엉뚱한 문자들이 높은 확률을 받게 된 거예요. 그래서 영어로 질문했는데 갑자기 “สวัสดี”(태국어로 안녕하세요)가 중간에 나타나는 일이 벌어진 겁니다.
세 번째: XLA 컴파일러의 숨겨진 함정
가장 복잡한 버그였어요. Claude가 다음 단어를 선택할 때 사용하는 “approximate top-k” 알고리즘에 문제가 있었습니다. 가장 확률이 높은 토큰이 완전히 사라져버리는 경우가 있었거든요.
대규모 AI 서비스의 숨겨진 복잡성
Claude는 단순히 하나의 서버에서 돌아가지 않습니다. AWS Trainium, NVIDIA GPU, Google TPU 등 여러 하드웨어 플랫폼에 분산되어 실행되죠. 전 세계 수백만 사용자에게 서비스하려면 이런 복잡한 구조가 필요합니다.
문제는 각 플랫폼마다 특성이 다르다는 점이에요. 같은 모델이라도 하드웨어에 따라 미묘한 차이가 생길 수 있거든요. Anthropic은 이런 차이를 최소화하려고 엄격한 동등성 기준을 적용하지만, 완벽하지는 않습니다.
실제로 Claude Code 사용자의 약 30%가 이 기간 동안 최소 한 번은 잘못된 서버로 라우팅된 메시지를 받았어요. Amazon Bedrock에서는 최고 0.18%, Google Cloud Vertex AI에서는 0.0004%의 요청이 영향을 받았습니다.
XLA 컴파일러 버그: 악마는 디테일에 있다
가장 흥미로운 건 세 번째 버그의 원인이었어요. 이건 정말 저수준 시스템의 복잡성을 보여주는 사례입니다.
Claude가 다음 단어를 선택할 때는 확률 계산이 필요합니다. 이 과정에서 16비트 부동소수점(bf16)과 32비트 부동소수점(fp32) 간의 정밀도 차이가 문제를 일으켰어요.

더 재밌는 건, Anthropic이 작년 12월에 이미 비슷한 문제를 발견하고 임시방편을 만들어뒀다는 점입니다. 온도가 0일 때 가장 확률이 높은 토큰이 사라지는 버그였어요. 하지만 8월에 근본 원인을 고쳤다고 생각하고 이 임시방편을 제거했는데, 더 깊숙한 버그가 숨어있던 거였습니다.
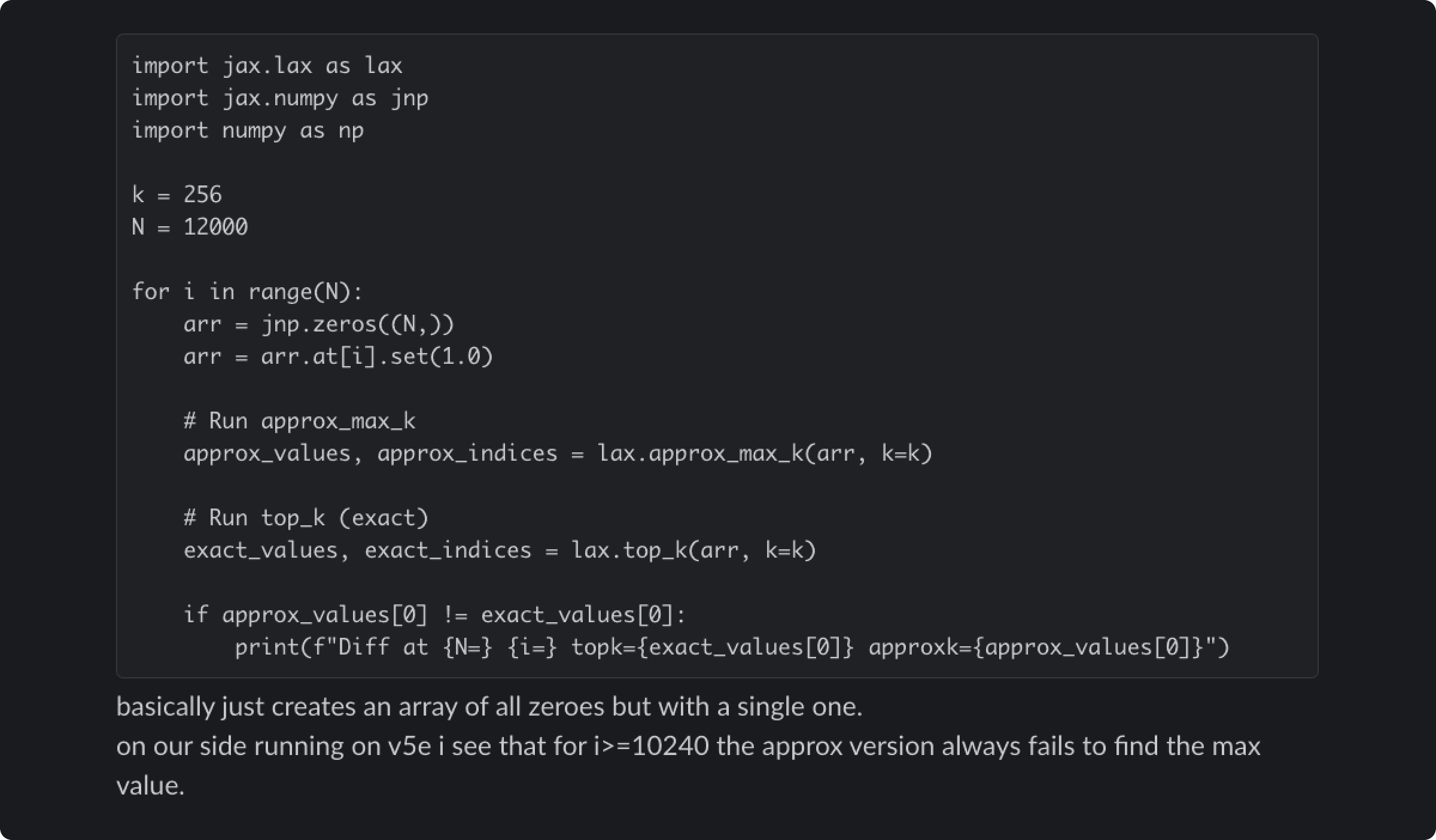
이 버그의 특징은 정말 까다로웠어요. 같은 코드라도 실행 환경에 따라 결과가 달랐거든요. 디버깅 도구를 켜면 정상 작동하고, 끄면 버그가 발생하는 식이었습니다. 진짜 하이젠버그 같은 버그였죠.
탐지가 어려웠던 이유
이런 복잡한 버그들을 왜 빨리 찾지 못했을까요? 여러 이유가 있었습니다.
첫째, 기존 평가 시스템이 이런 문제를 잡아내지 못했어요. Claude는 일부 실수가 있어도 전체적으로는 합리적인 답변을 만들어내는 경우가 많거든요. 벤치마크 점수로는 문제를 발견하기 어려웠습니다.
둘째, 사용자 프라이버시 보호 정책 때문에 엔지니어들이 실제 문제 상황을 직접 확인하기 어려웠어요. 사용자가 직접 신고하지 않은 대화는 검토할 수 없었거든요.
셋째, 각 버그가 서로 다른 플랫폼에서 다른 증상으로 나타났습니다. 한 사용자는 라우팅 문제를, 다른 사용자는 출력 손상을, 또 다른 사용자는 토큰 선택 문제를 경험했어요. 이런 제각각인 신고들을 하나의 패턴으로 연결하기가 쉽지 않았습니다.
AI 서비스 운영의 새로운 교훈
이번 사건에서 배울 점이 많습니다. 특히 다른 AI 서비스를 운영하는 조직들에게는 값진 사례죠.
투명성의 힘
Anthropic이 이렇게 상세한 사후분석을 공개한 건 정말 인상적이었어요. 보통 회사들은 “서버 문제가 있었습니다”라고 간단히 넘어가곤 하는데, 이들은 XLA 컴파일러 버그까지 자세히 설명했거든요. 이런 투명성이 오히려 신뢰를 높인다는 걸 보여줍니다.
복잡성 관리의 중요성
멀티 플랫폼 환경에서 AI 모델을 서빙하는 건 생각보다 훨씬 복잡합니다. 하드웨어마다 다른 최적화가 필요하고, 각각의 특성을 이해해야 해요. 단순히 “클라우드에 올리면 끝”이 아니라는 거죠.
사용자 피드백의 가치
결국 이 문제들을 발견한 건 사용자들의 신고였어요. 아무리 정교한 모니터링 시스템이 있어도, 실제 사용 패턴에서 나타나는 문제들을 모두 잡아내기는 어렵습니다. 사용자 커뮤니티와의 소통이 얼마나 중요한지 보여주는 사례죠.
품질 보장의 어려움
AI 모델의 품질을 객관적으로 평가하는 건 정말 어려운 일입니다. 벤치마크 점수는 높은데 사용자 경험은 나쁠 수 있거든요. 다양한 각도에서 지속적으로 품질을 체크하는 시스템이 필요합니다.
앞으로의 변화
Anthropic은 이번 경험을 바탕으로 여러 개선책을 내놓았습니다.
더 민감한 평가 시스템을 도입해서 미묘한 품질 저하도 감지할 수 있게 하겠다고 했어요. 실제 프로덕션 환경에서도 지속적으로 품질 평가를 실행할 예정입니다.
사용자 프라이버시를 보호하면서도 빠른 디버깅이 가능한 도구들도 개발 중이라고 하네요. 그리고 사용자들의 피드백을 더 적극적으로 수집하고 분석하는 시스템도 강화할 계획입니다.
이번 사건은 AI 서비스 운영이 얼마나 복잡한 일인지 잘 보여줍니다. 단순히 모델만 좋으면 되는 게 아니라, 인프라부터 모니터링, 사용자 소통까지 모든 게 유기적으로 연결되어 있거든요. Anthropic의 투명한 공개가 다른 AI 회사들에게도 좋은 선례가 되길 바랍니다.
답글 남기기