
Mixedbread가 AI 시대를 위한 차세대 검색 API ‘Mixedbread Search’를 퍼블릭 베타로 출시하며 기존 시맨틱 검색 대비 LLM 호출 16% 감소와 정확도 16% 향상을 동시에 달성했습니다. 텍스트뿐 아니라 이미지, 오디오, 비디오까지 하나의 API로 검색할 수 있는 멀티모달 솔루션입니다.
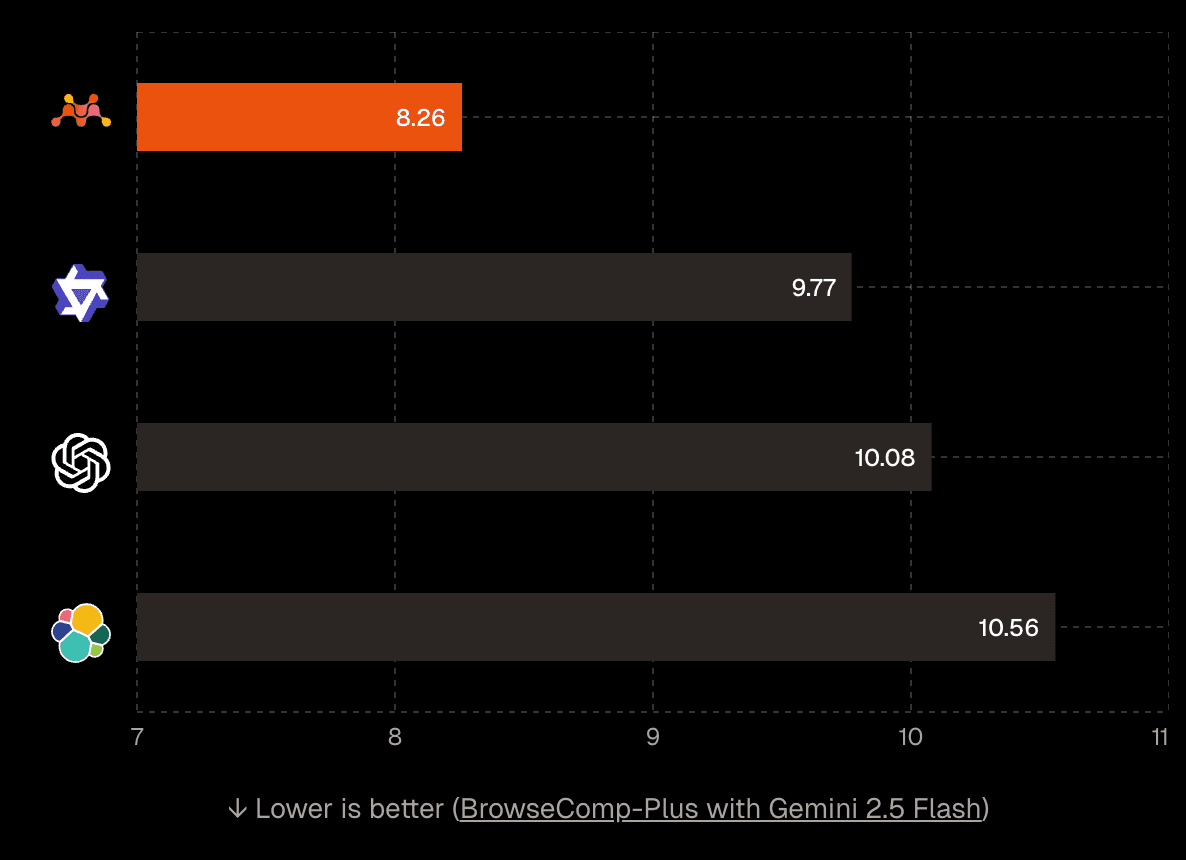
핵심 포인트:
- LLM 호출 16% 감소, 정확도 16% 향상: BrowseComp-Plus 벤치마크에서 기존 시맨틱 검색 대비 우수한 성능 입증. 비용 절감과 성능 개선을 동시에 달성
- 진짜 멀티모달 검색의 구현: 텍스트, 이미지, 오디오, 비디오를 단일 API로 검색 가능. 지저분한 PDF, 음성 메모, 오래된 코드까지 모든 형태의 데이터 처리
- 복잡성 제거한 end-to-end 솔루션: OCR과 문서 파싱을 자동화해 데이터 업로드만으로 즉시 검색 가능. 검색 기술을 몰라도 사용할 수 있는 간편함
Mixedbread는 누구인가
본격적인 이야기에 앞서 Mixedbread에 대해 간단히 소개하겠습니다. Mixedbread는 정보 검색(information retrieval)을 근본부터 재정의하는 응용 연구 랩입니다. “AI를 위한 메모리”를 만든다는 명확한 미션 아래, AI 시스템이 세상을 이해하고 의미있게 상호작용할 수 있도록 완벽한 컨텍스트를 제공하는 것을 목표로 하고 있죠.
이들은 이미 오픈소스 임베딩 모델로 검증받았습니다. 대표 모델인 mxbai-embed-large-v1은 MTEB(Massive Text Embedding Benchmark) 기준 동일 크기 클래스의 오픈소스 모델 중 1위를 차지했고, OpenAI의 text-embedding-3-large보다 우수한 성능을 보여줬습니다. 5천만 회 이상 다운로드되며 개발자들의 신뢰를 얻었죠. 그런 Mixedbread가 이번에는 검색 API라는 완전히 다른 형태의 제품으로 시장에 나섰습니다.
왜 기존 검색으로는 부족한가
세상은 깔끔하게 정리된 텍스트로만 이루어지지 않았습니다. 실제 지식은 지저분한 PDF 속에 숨어있고, 1,500만 개의 이미지 중 단 하나에 핵심 정보가 담겨있으며, 중요한 디테일은 음성 메모에 기록되어 있습니다. 심지어 10년간 수정되지 않은 VB6 스크립트에 비즈니스 핵심 로직이 들어있는 경우도 있죠.
기존 시맨틱 검색은 대부분 텍스트에 집중했습니다. 이미지나 오디오를 검색하려면 별도 파이프라인을 구축해야 했고, 각각 다른 모델과 처리 과정이 필요했습니다. 개발자 입장에서는 복잡한 기술 스택을 이해하고 관리해야 하는 부담이 컸습니다.
RAG(Retrieval-Augmented Generation) 시스템을 구축할 때도 마찬가지입니다. 문서를 청크(chunk)로 나누고, 임베딩하고, 벡터 데이터베이스에 저장하고, 검색하고, 재순위화(reranking)하는 전체 파이프라인을 직접 설계해야 했습니다. OCR이 필요한 문서라면 전처리 단계도 추가됩니다.
Mixedbread Search의 4가지 차별점
Mixedbread Search는 “검색이 어떻게 작동하는지 이해하지 못해도 좋은 검색을 누릴 수 있어야 한다”는 단순한 아이디어에서 출발했습니다.
멀티모달 검색(Multi-Modal Search)이 핵심입니다. 텍스트, 이미지, 오디오, 비디오를 모두 하나의 API로 검색할 수 있습니다. 코드 스니펫을 찾든, 특정 BPM의 오디오 샘플을 검색하든, 시각적 설명으로 이커머스 상품을 찾든 모두 같은 방식으로 작동합니다.
멀티링구얼 지원(Multi-Lingual Search)도 기본입니다. 세상은 영어만으로 이루어지지 않았으니까요. 다양한 언어로 된 문서를 별도 처리 없이 검색할 수 있습니다.
낮은 지연시간(Low Latency)은 실용성의 문제입니다. 5,700밀리초가 아니라 지금 당장 결과가 필요합니다. Mixedbread Search는 실시간 검색이 가능한 속도를 제공합니다.
의미있는 최첨단 성능(Meaningfully State-of-the-art)이라는 표현이 흥미롭습니다. 단순히 벤치마크 숫자가 높다는 의미가 아닙니다. DeepResearch 벤치마크 같은 현실적인 테스트에서 LLM 어시스턴트가 실제로 더 정확한 응답에 도달할 수 있도록 돕는다는 뜻입니다.
실제 성능은 어떤가
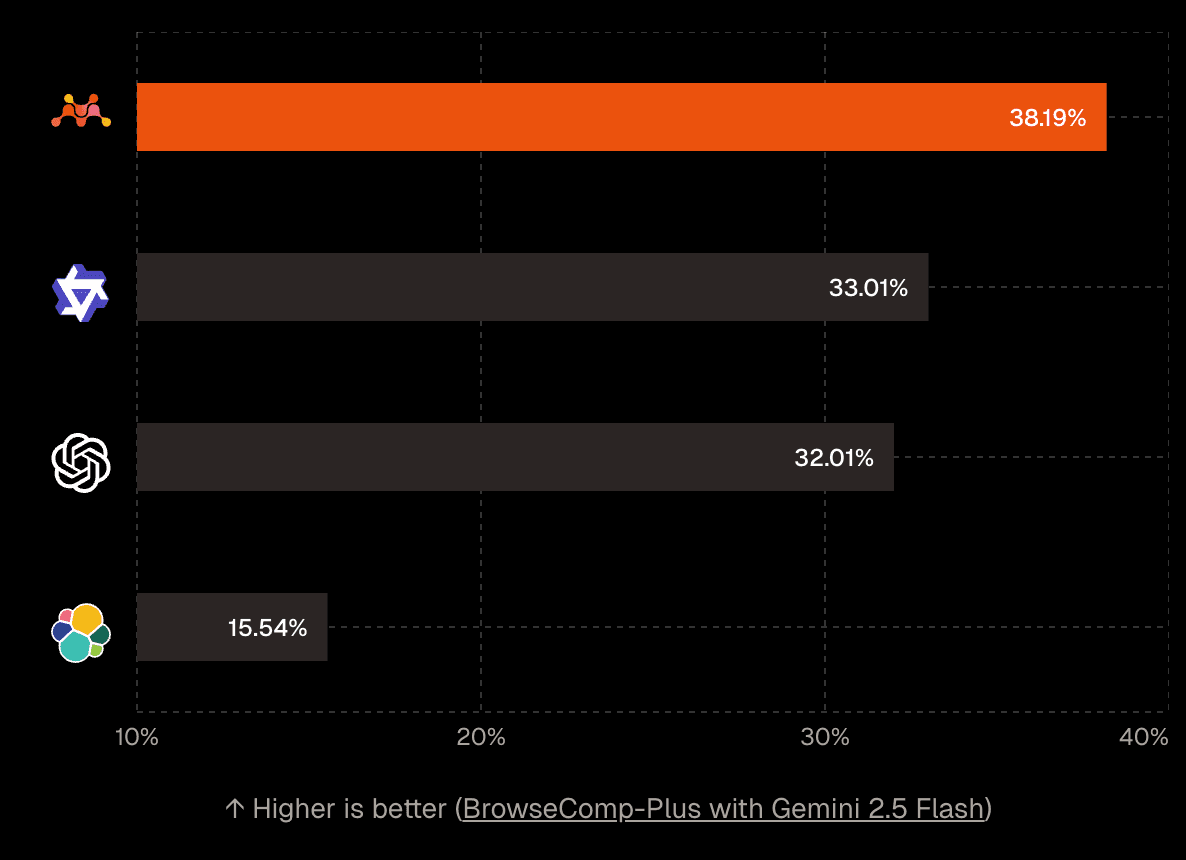
BrowseComp-Plus 벤치마크에서 Gemini 2.5 Flash를 사용한 딥 서치 테스트 결과가 인상적입니다. Mixedbread Search는 기존 시맨틱 검색 솔루션 대비 16% 적은 LLM 호출만으로 16% 높은 정확도를 달성했습니다.
이게 왜 중요할까요? LLM 호출 횟수는 곧 비용입니다. RAG 시스템을 운영할 때 가장 큰 비용 요소 중 하나가 LLM API 호출이죠. 16% 감소는 작은 숫자처럼 보이지만, 대규모 서비스에서는 상당한 비용 절감 효과를 가져옵니다. 게다가 정확도도 동시에 높아졌다는 점이 핵심입니다.
성능 개선의 비밀은 Mixedbread의 자체 연구 기반 파이프라인에 있습니다. 그들은 단순히 기존 데이터셋을 활용하는 대신, 인터넷의 대부분을 직접 스크래핑하고 정제해서 자체 학습 데이터셋을 구축했습니다. 7억 개 이상의 쌍(pair)으로 대조 학습(contrastive training)을 진행했고, 3천만 개의 고품질 트리플렛(triplet)으로 튜닝했습니다. MTEB 테스트와의 중복을 철저히 배제했고, 심지어 MS Marco를 제외한 MTEB 학습 데이터도 사용하지 않았습니다.
실제로 어떻게 사용하나
가장 인상적인 부분은 사용의 간편함입니다. end-to-end 솔루션이라는 표현이 마케팅 용어가 아닙니다. 정말로 데이터를 업로드하기만 하면 됩니다.
플랫폼에는 최첨단 OCR과 문서 파싱이 내장되어 있습니다. 지저분한 PDF든, 스캔된 문서든, 복잡한 레이아웃의 파일이든 자동으로 처리됩니다. 개발자가 전처리 파이프라인을 고민할 필요가 없습니다.
문서를 업로드하면 바로 검색을 시작할 수 있습니다. 복잡한 설정이나 파라미터 튜닝 없이 말입니다. 이것이 “검색 기술을 이해하지 못해도 좋은 검색을 누릴 수 있어야 한다”는 철학의 구현입니다.
National Gallery of Art의 작품 컬렉션을 검색하는 데모 사이트(https://nga.demo.mixedbread.com)를 보면 이 기술의 실용성이 명확히 드러납니다. 자연어로 “겨울 풍경”을 검색하면 관련 작품들을 정확히 찾아냅니다. 복잡한 쿼리 문법이나 메타데이터 필터링 없이도 말이죠.

베타 출시의 의미
Mixedbread는 이번 퍼블릭 베타를 “끝이 아니라 시작”이라고 표현합니다. 실제 사용자 피드백을 기반으로 빠르게 반복 개선할 계획입니다.
RAG 시스템 구축의 진입 장벽을 낮춘다는 점에서 의미가 큽니다. 지금까지는 벡터 데이터베이스, 임베딩 모델, 재순위화 모델 등을 각각 선택하고 조합해야 했습니다. Mixedbread Search는 이 모든 과정을 하나의 API로 단순화합니다.
특히 멀티모달 검색이 단일 API로 제공된다는 점이 실용적입니다. 이미지와 텍스트를 함께 다루는 애플리케이션을 만들 때, 별도의 처리 파이프라인 없이 하나의 검색 엔드포인트로 해결할 수 있습니다.
무료로 시작할 수 있다는 점도 주목할 만합니다. 베타 기간 동안 플랫폼에 가입하면 바로 사용해 볼 수 있습니다. 오픈소스 모델로 신뢰를 쌓아온 Mixedbread가 이제 완성된 제품으로 실용성을 증명할 차례입니다.
AI 검색의 새로운 기준이 제시되었습니다. 더 빠르고, 더 정확하며, 더 간편한 검색. 이것이 Mixedbread Search가 약속하는 미래입니다.
참고자료:
답글 남기기