RAG
RAG가 그럴듯한 답을 내놓고도 틀리는 이유, 세 도구가 보는 방식
RAG가 그럴듯한 답을 내놓고도 틀리는 이유와, RAGAS·TruLens·DeepEval 세 평가 프레임워크가 이를 각각 다르게 잡아내는 철학을 다룹니다.
Written by
AI 검색의 답, 사실은 3단계를 거쳐 만들어진다
ChatGPT 같은 AI가 최신 정보를 답할 때 쓰는 RAG 기술, 검색·증강·생성 3단계가 실제로 어떻게 작동하는지 정리했습니다.
Written by

구글 1위인데 ChatGPT는 왜 날 인용 안 할까
AI 검색이 답변에 인용할 사이트를 고르는 수집-읽기-검증-답변 4단계 프로세스와, 구글 1위가 AI 인용을 보장하지 않는 이유를 소개합니다.
Written by

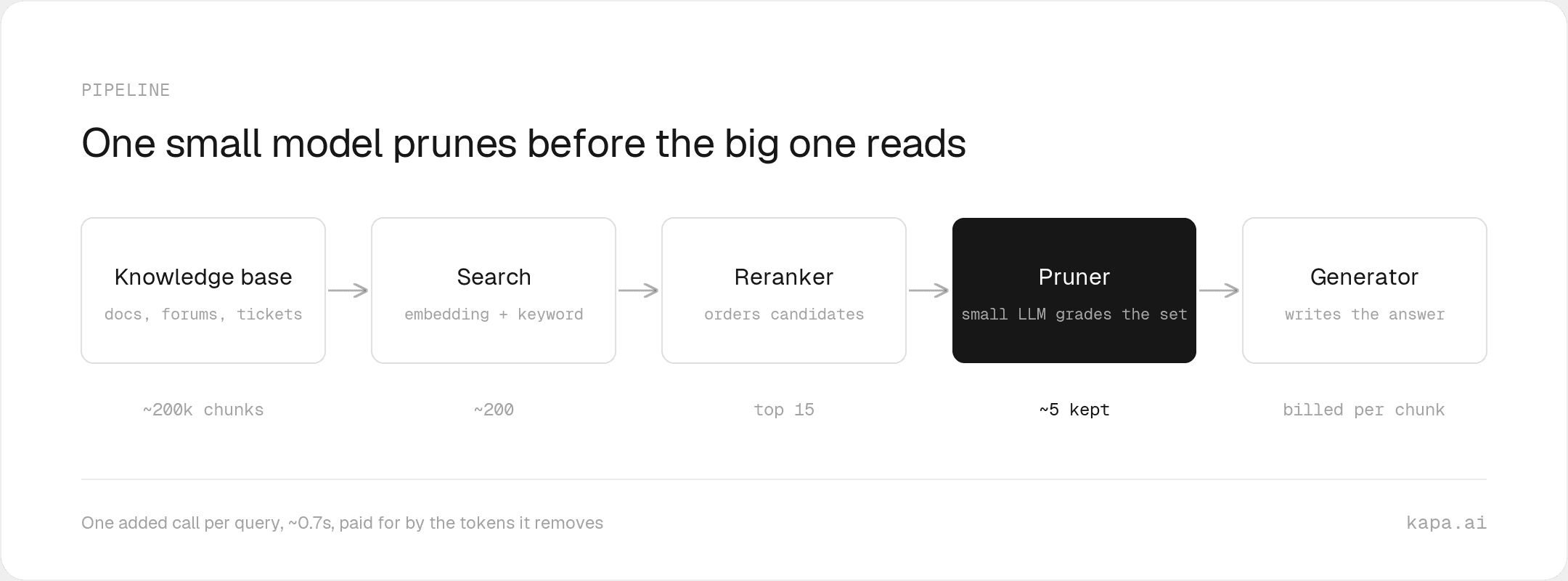
RAG 컨텍스트 68% 쳐내고 정확도는 지킨 kapa.ai의 채점 방식
kapa.ai가 LLM 채점으로 RAG 컨텍스트를 68% 줄이면서도 재현율 96%를 지킨 방법. rerank 한계와 해법을 소개합니다.
Written by
컨텍스트 윈도우는 200만 토큰까지 커졌는데, AI는 왜 방금 준 정보를 못 쓸까
컨텍스트 윈도우가 200만 토큰까지 커져도 AI가 중간 정보를 놓치는 U-shape 현상과, 양보다 정밀도가 중요한 이유. 개인 실무자가 바로 쓸 수 있는 5가지 컨텍스트 관리 원칙을 정리했습니다.
Written by

AI 메모리는 RAG로 끝나지 않는다, 검색과 기억은 다른 문제다
“AI 메모리”는 단일 기능이 아니라 RAG·벡터·그래프 등 5개 층위입니다. 검색과 기억의 차이, 그리고 그래프 메모리가 보완하는 상태 관리 문제를 정리합니다.
Written by

AI 에이전트 검색, 벡터보다 grep이 더 정확한 이유
AI 에이전트 환경에서 grep이 벡터 검색보다 높은 정확도를 보인 PwC 연구. 검색 전략보다 에이전트 하네스 구조가 성능에 더 큰 영향을 미친다는 발견을 소개합니다.
Written by

에이전트 vs 파이프라인, AI 개발의 기본 선택지를 비교하다
LLM 프로그램을 파이프라인으로 짤 것인가, 에이전트로 짤 것인가. 맥락 수집·비용·안전성·미래 대응력 측면에서 두 방식을 비교하고 판단 기준을 제시합니다.
Written by

Chrome 온디바이스 임베딩 API, RAG와 시맨틱 서치를 브라우저 안으로
Chrome Built-in AI 팀이 브라우저 내장 임베딩 API를 제안했습니다. 클라우드 없이 온디바이스에서 시맨틱 서치와 RAG를 구현하는 새로운 접근을 소개합니다.
Written by