RAG 시스템을 구축하다 보면 늘 같은 고민에 부딪힙니다. 성능 좋은 임베딩 모델을 쓰려면 GPU 서버가 필요하고, 비용을 낮추려면 성능을 포기해야 하죠. 게다가 문서 인덱싱은 느려도 괜찮지만 사용자 쿼리는 몇백 밀리초 안에 응답해야 하는데, 같은 무거운 모델을 두 작업에 모두 써야 합니다.

MongoDB Research가 공개한 LEAF(Lightweight Embedding Alignment Framework)는 이 딜레마에 새로운 해법을 제시합니다. 지식 증류(knowledge distillation) 기법으로 대형 모델을 5~15배 작게 압축하면서도 성능은 97%를 유지하고, 23M 파라미터 모델 두 개를 Apache 2.0 라이선스로 공개했습니다.
출처: LEAF: Distillation of State-of-the-Art Text Embedding Models – MongoDB Engineering Blog
기존 방식과 완전히 다른 접근
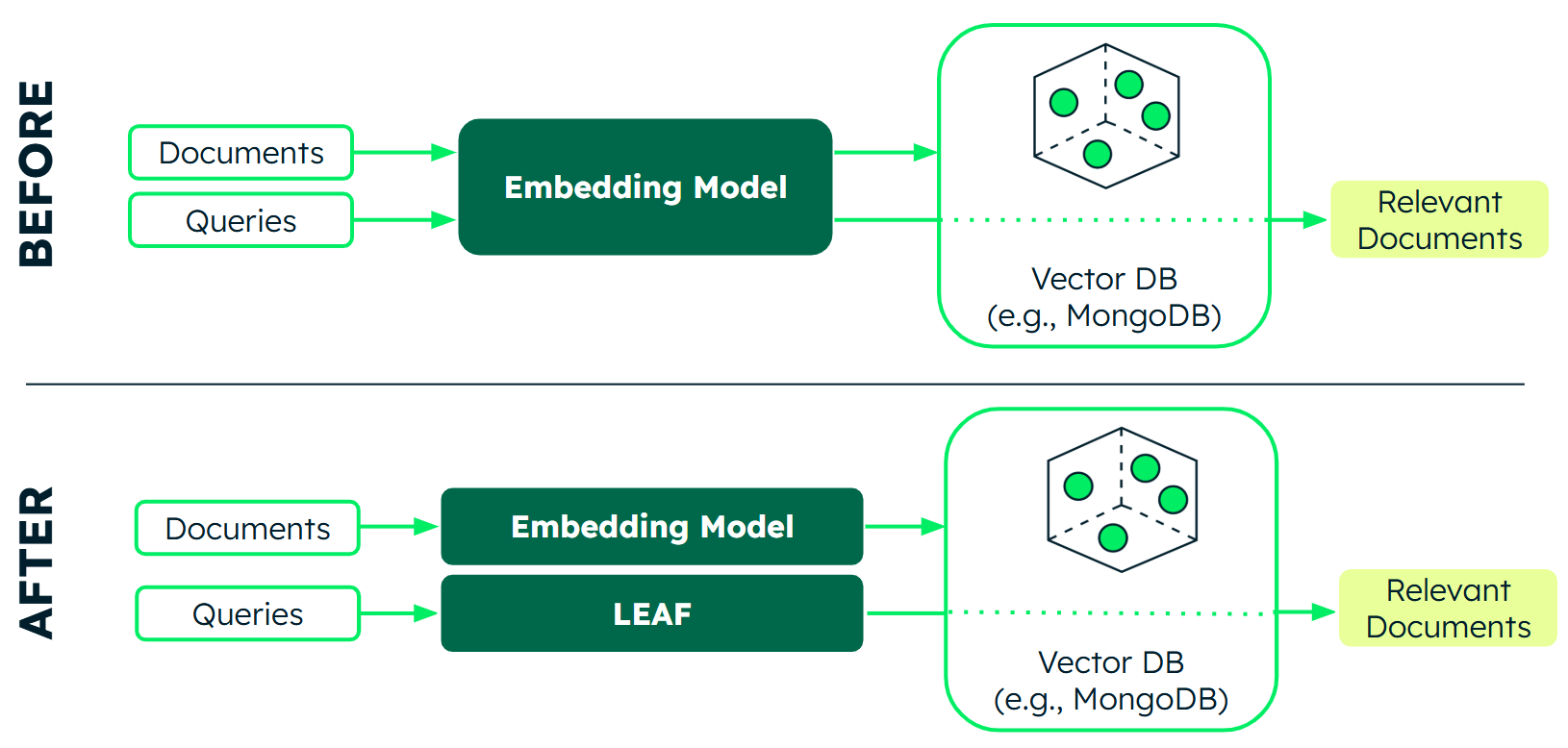
LEAF의 핵심 혁신은 “교사-학생 모델 호환성”입니다. 기존 지식 증류 방법들은 모델 내부의 모든 레이어를 정렬하려 했지만, LEAF는 오직 최종 출력(임베딩)만 정렬합니다. 덕분에 큰 교사 모델과 작은 학생 모델이 생성한 임베딩을 서로 호환해서 쓸 수 있죠.
이게 실무에서 뭘 의미할까요? 문서는 큰 모델로 미리 인덱싱해두고, 사용자 쿼리는 작고 빠른 모델로 처리할 수 있습니다. 이른바 “비대칭 아키텍처”예요. 문서 인덱싱은 GPU 서버에서 한 번만 하면 되고, 쿼리 처리는 CPU만으로도 충분히 빠릅니다. 모델을 바꿔도 기존 인덱스를 버릴 필요가 없어요.
게다가 LEAF는 라벨링된 학습 데이터가 필요 없고, GPU 클러스터 대신 A100 한 대로 학습할 수 있습니다. 진입 장벽이 확 낮아진 거죠.
실제 성능은 어떨까
MongoDB는 두 가지 모델을 공개했습니다. mdbr-leaf-ir은 RAG 같은 검색 작업에 최적화됐고, mdbr-leaf-mt는 분류나 클러스터링 같은 범용 작업용이에요. 둘 다 23M 파라미터로 같은 크기입니다.
BEIR 벤치마크에서 mdbr-leaf-ir은 OpenAI text-embedding-3-small(51.08점)을 넘어서는 53.55점을 기록했습니다. OpenAI large 모델(55.43점)과 비교하면 약 97% 수준이에요. 100M 파라미터 이하 모델 중에선 1위입니다.
범용 작업에서도 mdbr-leaf-mt는 MTEB v2 벤치마크에서 63.97점으로 OpenAI small(64.56점)에 근접했고, 30M 파라미터 이하 모델 중 최고 성능을 보였습니다.
이 모델들은 CPU 2코어 인스턴스에서 초당 120개 쿼리를 처리하고, 메모리는 87MB만 차지합니다. 스마트폰이나 IoT 기기에서도 돌아가고, 인터넷 연결 없이 작동합니다.
GPU 없는 RAG 시대가 열린다
LEAF의 가장 큰 의미는 고성능 임베딩 모델의 민주화입니다. 이제 GPU 서버 없이도, 심지어 모바일 기기에서도 괜찮은 품질의 RAG 시스템을 구현할 수 있어요. 특히 비용이 민감한 스타트업이나 엣지 환경에서 AI를 구현해야 하는 경우엔 게임 체인저가 될 수 있습니다.
물론 한계도 있습니다. 아무리 잘 증류해도 원본 모델의 3%는 손실되고, 극단적으로 정확도가 중요한 경우엔 여전히 큰 모델이 필요합니다. 하지만 대부분의 실무 상황에선 이 정도 트레이드오프는 충분히 받아들일 만하죠.
MongoDB는 모델과 학습 레시피를 모두 공개했으니, 자신의 도메인 데이터로 파인튜닝해서 성능을 더 끌어올릴 수도 있습니다. Hugging Face에서 바로 다운로드할 수 있어요.
참고자료:
답글 남기기