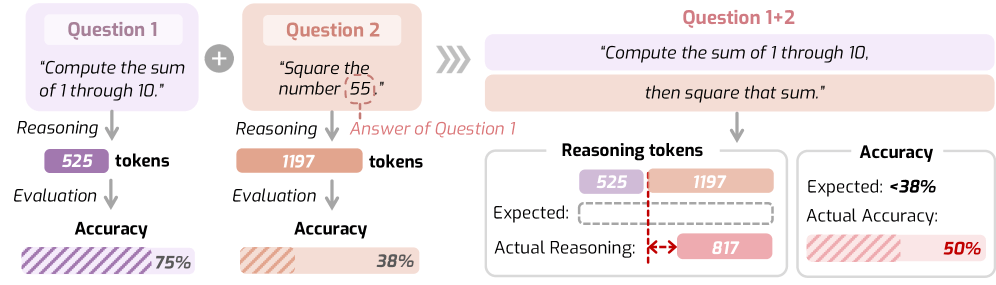
AI에게 “17 곱하기 24는?”이라고 물으면 단계별로 생각하며 답을 냅니다. 그런데 이상한 일이 벌어집니다. 숫자 하나만 제곱하라고 하면 300토큰이나 쓰면서, 더 어려운 “합계를 구한 다음 제곱하라”는 문제엔 오히려 덜 생각하죠. 게다가 정확도는 12.5%나 떨어집니다.
미국 여러 대학 연구팀이 최신 추론 모델들의 이런 비논리적 행동을 분석하고, AI가 어떻게 생각해야 하는지에 대한 이론적 법칙을 제안했습니다. OpenAI o1이나 Deepseek-R1 같은 추론 모델들이 2025년 AI 트렌드의 중심에 있지만, 그 추론 과정 자체가 체계를 따르지 않는다는 겁니다.

일리노이대, MIT, 펜실베이니아대, NYU, NTT 연구소 공동 연구팀이 AI 추론 모델들의 비효율적 사고 패턴을 분석한 연구입니다. 쉬운 문제에 더 많은 계산을 쓰고 어려운 문제엔 덜 쓰는 역설적 행동의 원인과 해결책을 제시합니다.
출처: AI reasoning models think harder on easy problems than hard ones, and researchers have a theory for why – The Decoder
추론 모델의 작동 방식과 문제점
추론 모델은 일반 언어 모델과 다릅니다. 답을 내놓기 전에 내부적으로 “생각하는 과정”을 거치죠. 이 과정을 추론 트레이스(reasoning trace)라고 부릅니다. 예를 들어 17 곱하기 24를 물으면 이렇게 생각합니다:
“문제를 작은 단계로 나눕니다. 17 × 24 = 17 × (20 + 4) = 17 × 20 + 17 × 4. 17 × 20 = 340. 17 × 4 = 68. 340 + 68 = 408. 답은 408입니다.”
이 기법은 수학 증명이나 복잡한 논리 문제에서 성능을 크게 높입니다. 하지만 문제가 있습니다. 사람은 문제 난이도에 맞춰 생각의 양을 조절하는데, AI는 그렇지 않습니다. 때론 너무 많이 생각하고, 때론 너무 적게 생각하죠.
연구팀은 원인을 훈련 데이터에서 찾았습니다. 추론 과정 예시들이 “얼마나 생각해야 하는가”에 대한 명확한 규칙 없이 만들어졌기 때문입니다.
추론의 법칙: AI는 어떻게 생각해야 하나
연구팀이 제안한 “추론의 법칙(Laws of Reasoning, LoRe)” 프레임워크는 두 가지 핵심 원칙을 담고 있습니다.
첫 번째 법칙은 간단합니다. 필요한 사고 시간은 문제 난이도에 비례해야 한다는 겁니다. 두 배 어려운 문제라면 계산 시간도 두 배가 되어야 하죠. 두 번째 법칙은 난이도가 올라갈수록 정확도가 지수적으로 떨어진다는 내용입니다.
실제 난이도는 직접 측정할 수 없으니, 연구팀은 두 가지 테스트 가능한 속성을 사용했습니다. 더 어려운 문제는 더 많은 시간이 필요하다는 것, 그리고 복합 과제의 경우 전체 시간이 개별 과제 시간의 합과 같아야 한다는 것입니다. A 과제에 1분, B 과제에 2분이 걸린다면 둘을 합친 과제는 약 3분이 걸려야 합니다.
모든 모델이 실패한 테스트
연구팀은 수학, 과학, 언어, 코딩 분야의 40개 과제와 MATH500 데이터셋의 250개 복합 과제로 벤치마크를 만들었습니다. 10개 대형 추론 모델을 테스트한 결과는 혼재되어 있었습니다.
대부분의 모델은 첫 번째 속성은 잘 따랐습니다. 어려운 문제에 더 많은 시간을 썼죠. 하지만 가장 작은 모델인 Deepseek-R1-Distill-Qwen-1.5B는 언어 과제에서 음의 상관관계를 보였습니다. 쉬운 문제에 오히려 더 오래 생각했어요.
하지만 복합 과제에서는 테스트한 모든 모델이 실패했습니다. 예상 사고 시간과 실제 사고 시간의 차이가 상당했습니다. 추론 길이를 제어하는 특수 메커니즘을 가진 Thinkless-1.5B나 AdaptThink-7B도 마찬가지였습니다.
해결책: 타겟 훈련으로 효율성 개선
연구팀은 복합 과제에서 덧셈 행동을 촉진하는 파인튜닝 방법을 개발했습니다. 두 개의 하위 과제와 그 조합, 이렇게 세 개를 묶어 훈련하는 방식입니다. 여러 생성된 솔루션 중에서 전체 과제의 사고 시간이 개별 과제 시간의 합에 가장 가까운 것을 선택합니다.
1.5B 모델에서 추론 시간 편차가 40.5% 감소했습니다. 6개 벤치마크 모두에서 추론 능력이 향상됐죠. 8B 모델은 평균 5%p의 정확도 향상을 보였습니다.
흥미로운 점은 덧셈적 사고 시간 훈련이 직접 훈련하지 않은 특성까지 개선했다는 겁니다. 연구팀은 벤치마크가 40개 초기 과제만 포함하고, 비용 문제로 독점 모델을 테스트하지 못한 점을 한계로 인정했습니다.
추론 모델의 미래
2025년 추론 모델은 LLM 생태계의 중심이 됐습니다. Deepseek R1이 적은 훈련 자원으로 경쟁력 있는 성능을 냈고, Claude Sonnet 3.7 같은 하이브리드 모델은 사용자가 유연하게 추론 예산을 설정할 수 있게 해줍니다.
동시에 여러 연구들이 추론이 결과를 개선하긴 하지만 인간의 사고와는 다르다는 점을 보여주고 있습니다. 모델들은 아마도 훈련된 지식 내에서 기존 솔루션을 더 효율적으로 찾는 것일 뿐, 인간처럼 근본적으로 새로운 아이디어를 ‘생각해낼’ 수는 없을 겁니다. OpenAI와 다른 기관들의 최신 과학 벤치마크도 이를 뒷받침합니다. 모델들은 기존 질문-답변 테스트는 통과하지만 혁신적 솔루션이 필요한 복잡하고 상호연결된 연구 과제에선 어려움을 겪습니다.
그럼에도 AI 업계는 추론 모델이 대규모 컴퓨팅 증가를 통해 개선될 수 있다고 큰 투자를 하고 있습니다. OpenAI는 예를 들어 o3에 전작 o1보다 10배 많은 추론 컴퓨팅을 사용했습니다. 출시 후 단 4개월 만에 말이죠.
참고자료:
- 코드 및 벤치마크 – GitHub
답글 남기기