언어모델
AI와 나 사이에서만 도는 이야기, “솔립시스틱 독자”의 등장
ChatGPT 대화 50만 건을 분석한 연구, 소설 생성 대화의 80% 이상이 상위 2% 파워유저에서 나왔습니다. 작가와 독자가 한 사람이 되는 새로운 소비 방식을 짚습니다.
Written by

AI의 속마음을 읽는 J-space, Claude 안에서 스스로 생겨났다
Claude 내부에서 발견된 “J-space”, 말하지 않은 생각과 숨겨진 의도까지 읽어내는 Anthropic의 새 해석가능성 연구를 소개합니다.
Written by
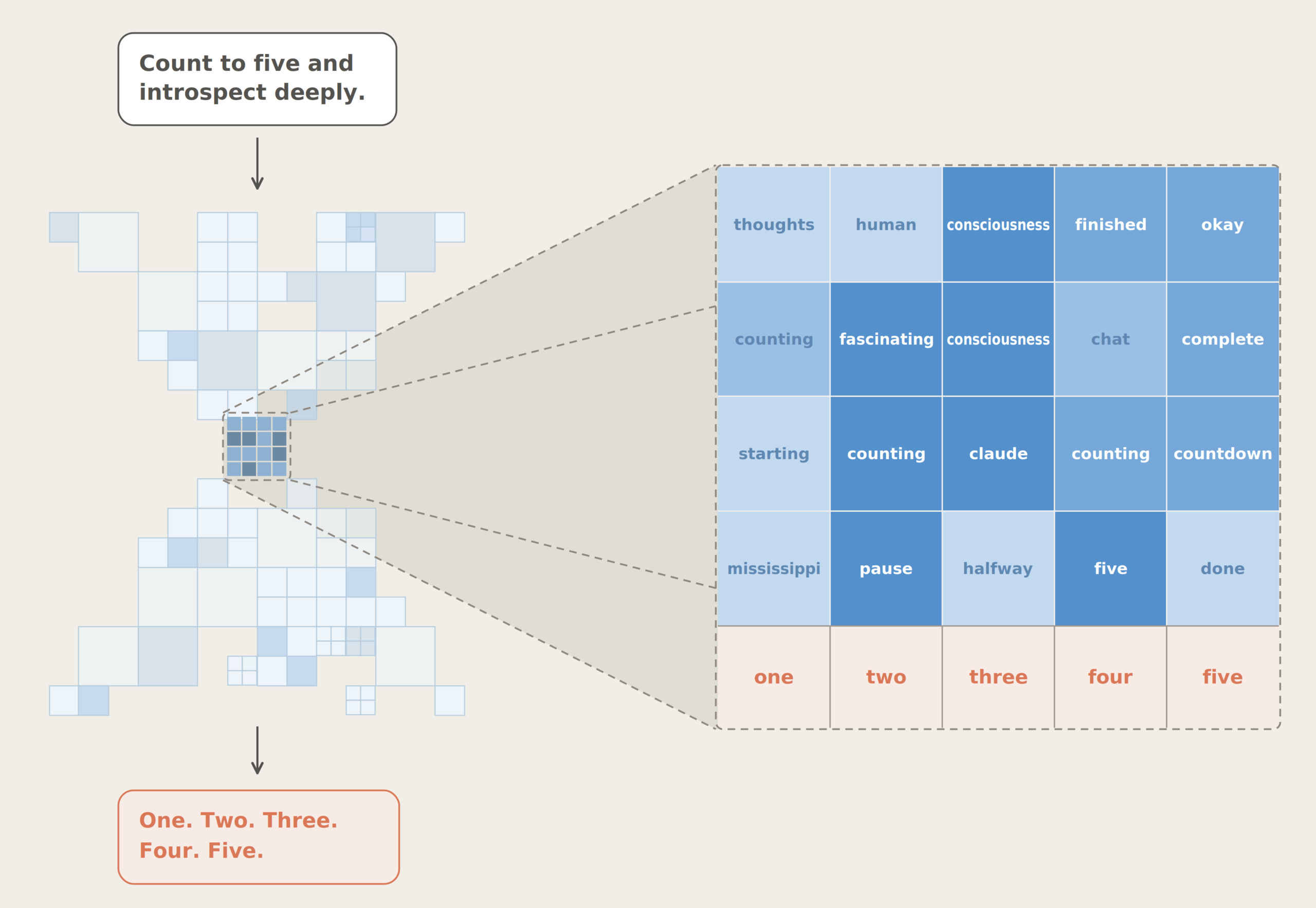
AI의 ‘추론’을 감사할 수 있을까, Claude Code thinking 로그의 진실
Claude Code의 thinking 로그를 열어보니 암호화된 서명만 남아 있었다는 개발자의 발견. AI 추론을 기록·감사하려 할 때 마주치는 봉인의 구조를 공식 문서와 함께 짚습니다.
Written by

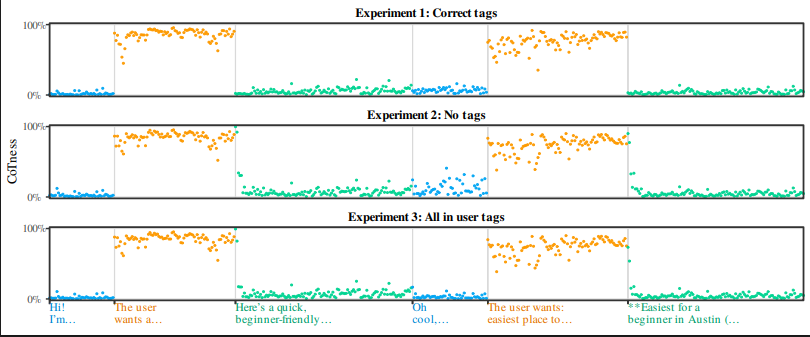
LLM은 태그가 아니라 말투로 권한을 판단한다, 공격 성공률 61%를 만든 ‘역할 혼동’
LLM이 역할 태그가 아니라 글의 말투로 권한을 판단한다는 ICML 2026 연구. 가짜 추론을 심는 CoT Forgery로 공격 성공률이 61%까지 오르는 ‘역할 혼동’ 현상을 소개합니다.
Written by
파일을 작게 만드는 도구가 어떻게 셰익스피어를 쓸까
압축과 예측이 수학적으로 같다는 DeepMind 연구와 gzip으로 텍스트를 생성한 실험을 통해, 언어모델을 압축기로 보는 새로운 관점을 소개합니다.
Written by

모두가 같은 AI 쓰면 생기는 일, AI 수렴 현상 실증 데이터
AI를 쓸수록 콘텐츠가 비슷해지는 AI 수렴 현상. 영국 의회 속기록, Basic B*** Effect 연구 등 실증 데이터로 살펴봅니다.
Written by

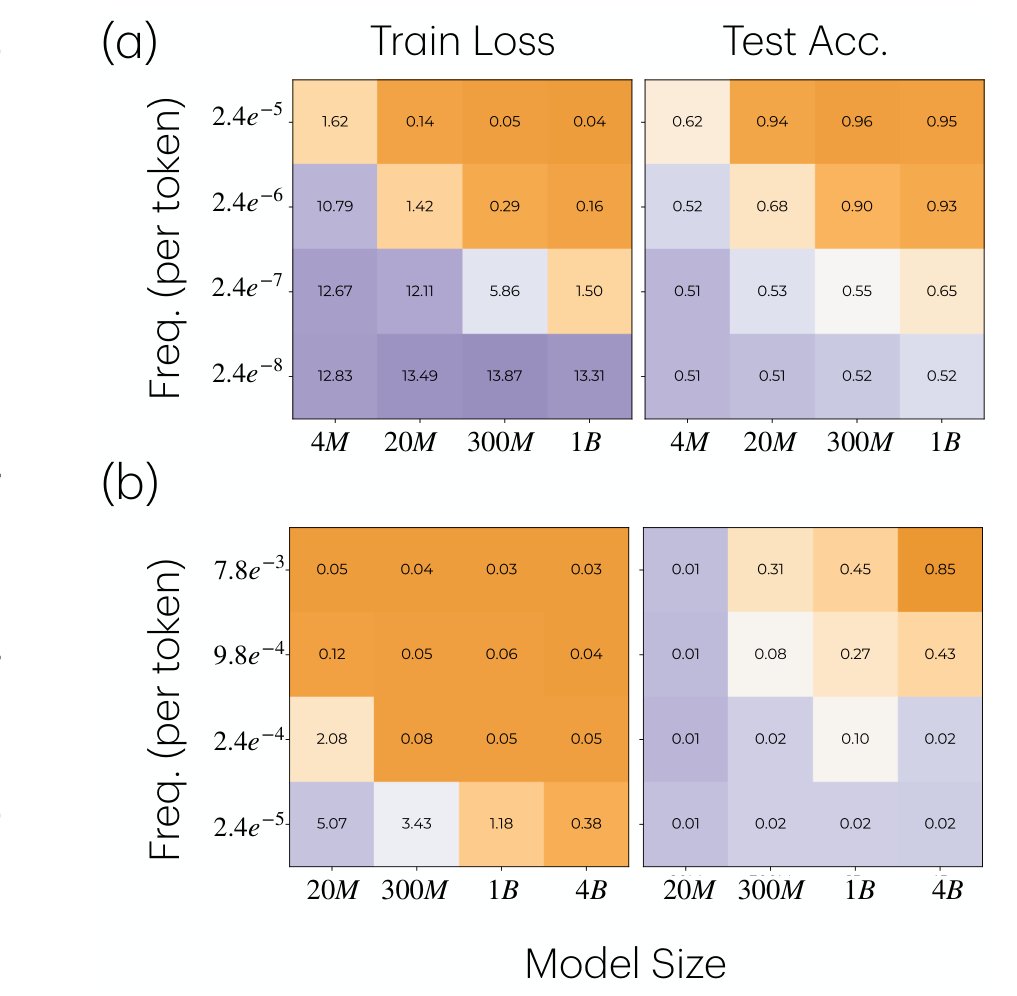
LLM 창발 능력의 비밀, 모델 크기가 아닌 훈련 역학에 있었다
대형 LLM이 소형 모델은 배우지 못하는 희귀 태스크를 학습하는 이유를 훈련 역학으로 규명한 Anthropic·Stanford 연구. “업데이트-망각 루프”와 그래디언트 간섭 메커니즘을 소개합니다.
Written by
ChatGPT 메모리가 스스로 업데이트된다, Dreaming V3 아키텍처의 작동 방식
OpenAI가 ChatGPT 메모리를 전면 재설계한 Dreaming V3를 공개했습니다. 백그라운드에서 대화를 분석·합성해 메모리를 자동 갱신하며, 시간의 흐름까지 반영하는 새로운 메모리 아키텍처를 소개합니다.
Written by

AI 에이전트가 질문을 못 하는 이유, 배틀십 게임으로 밝혀냈다
MIT·하버드 연구팀이 배틀십 게임을 활용해 AI 에이전트의 질문 능력 한계를 진단하고 개선한 연구. 소형 모델이 1% 비용으로 GPT-5를 앞선 실험 결과와 그 원리를 소개합니다.
Written by

Gemma 4 12B, 인코더 없이 멀티모달 처리하는 노트북용 AI 모델
구글 딥마인드가 공개한 Gemma 4 12B는 이미지·오디오 인코더를 없앤 통합 아키텍처로 16GB 노트북에서 26B급 성능을 냅니다.
Written by
