삼성 AI 연구팀이 단 7M 파라미터의 초소형 모델로 671B 파라미터의 Deepseek R1을 압도하는 성과를 냈습니다. 스도쿠와 미로 찾기 같은 복잡한 추론 문제에서 거대 AI들이 0%를 기록할 때, 이 작은 모델은 87%의 정확도를 보였습니다. 파라미터 수는 0.01% 미만이지만 성능은 더 높습니다.

핵심 포인트:
- 작은 네트워크의 역설: 2-layer 단일 네트워크(7M)가 4-layer 이중 네트워크(27M)보다 과적합 없이 더 높은 일반화 성능 달성
- 재귀가 깊이를 이긴다: 큰 네트워크 대신 작은 네트워크를 42번 반복하는 방식으로 스도쿠 87.4%, 미로 85.3%, ARC-AGI 44.6% 정확도 기록
- 거대 모델의 맹점: Deepseek R1, o3-mini, Gemini 2.5 Pro 모두 같은 문제에서 0~34% 수준에 머물며 복잡한 추론 작업의 한계 드러내
LLM이 못 푸는 퍼즐의 비밀
거대 언어 모델들은 자동 회귀 방식으로 답을 생성합니다. 하나의 토큰이 다음 토큰을 낳고, 그 토큰이 또 다음을 낳는 식이죠. 문제는 단 하나의 잘못된 토큰이 전체 답변을 무너뜨린다는 점입니다. 스도쿠에서 한 칸을 틀리면 전체가 틀리는 것처럼요.
Chain-of-Thought나 Test-Time Compute 같은 기법이 등장했지만, 여전히 ARC-AGI 같은 기하학적 퍼즐 앞에서는 인간 수준에 도달하지 못했습니다. Gemini 2.5 Pro가 ARC-AGI-2에서 고작 4.9% 정확도를 기록한 게 대표적 사례죠.
작지만 강한 모델의 비결
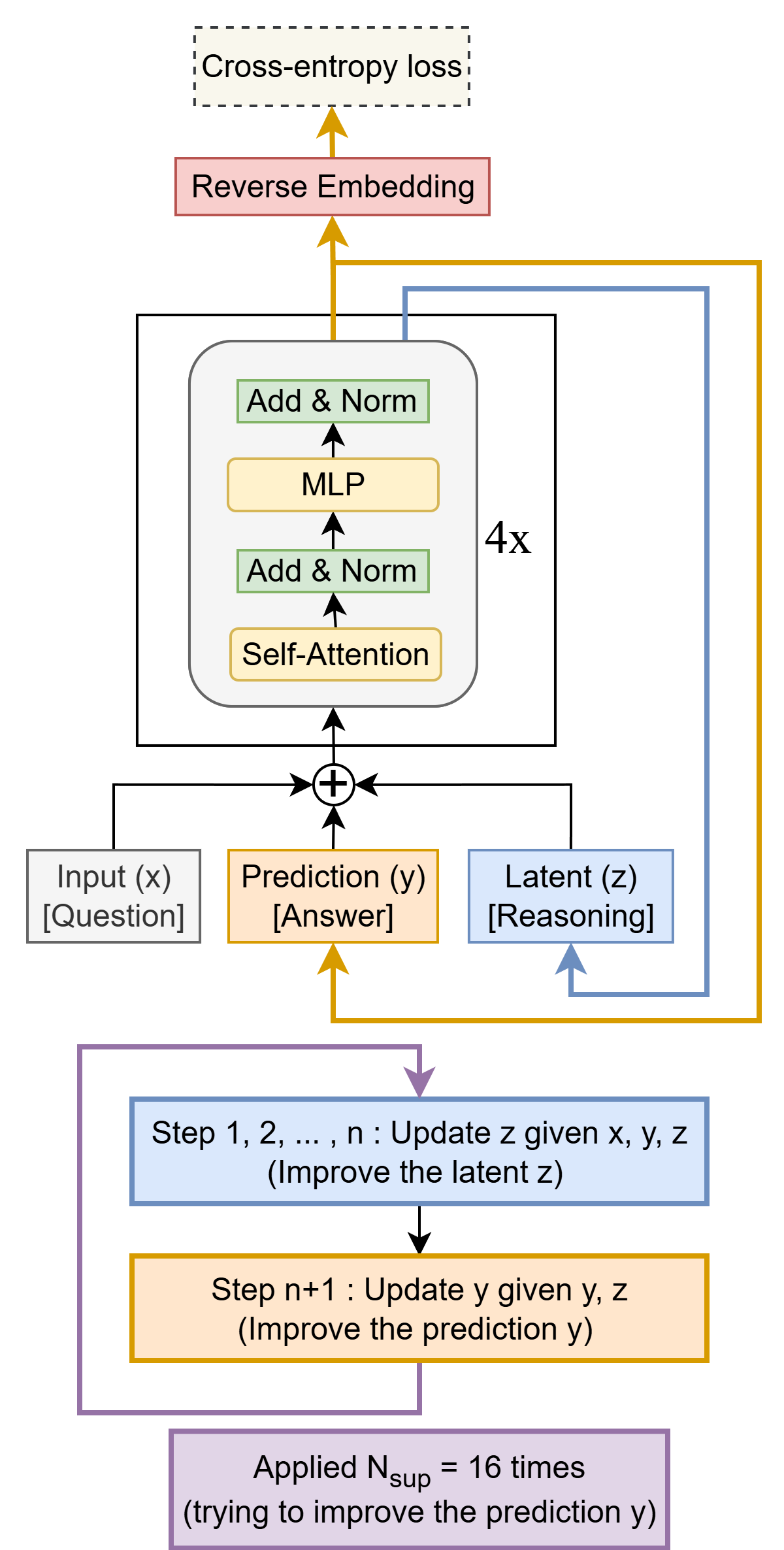
삼성 SAIL 몬트리올의 Alexia Jolicoeur-Martineau 연구원이 제안한 Tiny Recursive Model(TRM)은 발상을 완전히 뒤집었습니다. 모델을 크게 만드는 대신 작게 만들고, 대신 같은 네트워크를 반복해서 사용하는 방식입니다.
핵심 메커니즘은 세 가지입니다. 먼저 현재 답변(y)과 추론 과정(z)을 분리해서 기억합니다. 마치 수학 문제를 풀 때 현재까지의 답과 풀이 과정을 동시에 머릿속에 담아두는 것과 같죠. 그리고 작은 네트워크를 6번 반복해서 추론을 개선하고, 그 결과로 답을 한 번 업데이트합니다. 이 전체 과정을 다시 3번 반복하면서 점진적으로 정답에 가까워집니다.
여기에 Deep Supervision이라는 학습 방식을 더했습니다. 최대 16단계에 걸쳐 답을 계속 개선하도록 학습시키는 건데, 이전 단계의 추론 결과를 다음 단계의 출발점으로 삼습니다. 마치 초고를 여러 번 퇴고하면서 글을 다듬는 것처럼요.

실전 성능이 증명하는 효율성
숫자가 모든 걸 말해줍니다. 극악의 난이도를 자랑하는 Sudoku-Extreme에서 TRM은 87.4%의 정확도를 기록했습니다. Deepseek R1, Claude 3.7, o3-mini는 모두 0%였습니다. 30×30 크기의 복잡한 미로 찾기(Maze-Hard)에서도 85.3%를 달성하며 이전 기록(74.5%)을 크게 넘어섰죠.
ARC-AGI는 사람에게는 쉽지만 AI에게는 극도로 어려운 기하학 퍼즐입니다. TRM은 ARC-AGI-1에서 44.6%를 기록해 o3-mini(34.5%)와 Gemini 2.5 Pro(37%)를 앞질렀습니다. ARC-AGI-2에서는 7.8%로 Gemini 2.5 Pro(4.9%)보다 높았습니다.
특히 놀라운 건 학습에 사용한 데이터의 양입니다. 스도쿠는 단 1,000개의 훈련 샘플만 사용했습니다. 거대 모델들이 수천억 개의 토큰으로 학습하는 것과는 차원이 다른 효율성이죠.
왜 작은 모델이 더 강할까
연구팀은 여러 실험을 통해 흥미로운 사실들을 발견했습니다. 네트워크 레이어를 4개에서 2개로 줄이자 오히려 성능이 향상되었습니다(79.5% → 87.4%). 데이터가 부족할 때 큰 모델은 과적합되기 쉽지만, 작은 모델에 깊은 재귀를 결합하면 이 문제를 피할 수 있었던 거죠.
두 개의 네트워크를 사용하던 기존 방식(HRM)도 하나로 통합했습니다. 입력에 질문(x)을 포함하느냐 마느냐로 태스크를 구분할 수 있었기 때문입니다. 파라미터는 절반으로 줄었지만 성능은 더 좋아졌습니다(82.4% → 87.4%).
9×9 스도쿠처럼 작은 그리드에서는 self-attention 대신 단순한 MLP를 사용하는 게 더 효과적이었습니다. 컨텍스트 길이가 짧을 때는 복잡한 메커니즘이 오히려 방해가 되는 셈이죠.
삼성의 전략적 선택
이번 연구는 삼성이 AI 경쟁에서 어떤 방향을 택했는지 보여줍니다. 거대 모델 개발 경쟁에 뛰어들기보다 효율성에 집중한 겁니다. 온디바이스 AI가 중요해지는 시대에 이런 접근은 실용적입니다.
7M 파라미터면 스마트폰에서도 충분히 돌릴 수 있는 크기입니다. 클라우드에 의존하지 않고 기기 내에서 복잡한 추론을 처리할 수 있다는 의미죠. 개인정보 보호와 응답 속도 면에서도 유리합니다.
물론 한계도 있습니다. TRM은 지도학습 모델이라 하나의 입력에 하나의 결정적 답만 내놓습니다. 여러 답이 가능한 생성 태스크로 확장하는 건 앞으로의 과제입니다. 또한 왜 재귀가 큰 네트워크보다 효과적인지에 대한 이론적 설명도 아직 부족합니다.
효율성 혁명의 시작
“더 크면 더 좋다”는 AI 업계의 통념이 흔들리고 있습니다. 이번 연구는 작고 똑똑한 모델이 특정 영역에서 거대 모델을 압도할 수 있음을 입증했습니다. 앞으로 AI 개발의 방향이 단순한 규모 확대에서 효율적 설계로 전환될 가능성을 보여주는 신호탄입니다.
참고자료:
답글 남기기