AI 모델이 점점 커지고 있습니다. 작년에 나온 DeepSeek V3도 상당했지만, 최근 공개된 Kimi-K2.5는 무려 1조 개의 파라미터를 가지고 있죠. 모델이 커질수록 성능은 좋아지지만, 메모리와 연산 비용, 에너지 소비도 함께 급증합니다. 이 문제를 해결하는 핵심 기술이 바로 ‘Low-bit 추론’입니다.

Dropbox 기술 블로그가 AI 모델을 효율적으로 실행하는 Low-bit 추론 기술을 상세히 설명했습니다. Dropbox Dash 같은 실제 제품에 적용하면서 얻은 인사이트를 바탕으로, 양자화(quantization) 기법의 작동 원리와 실무 트레이드오프를 다룹니다. 특히 최신 하드웨어가 직접 지원하는 MXFP 포맷의 등장이 게임 체인저가 되고 있다는 점을 강조합니다.
출처: How low-bit inference enables efficient AI – Dropbox Tech Blog
왜 양자화가 필요한가
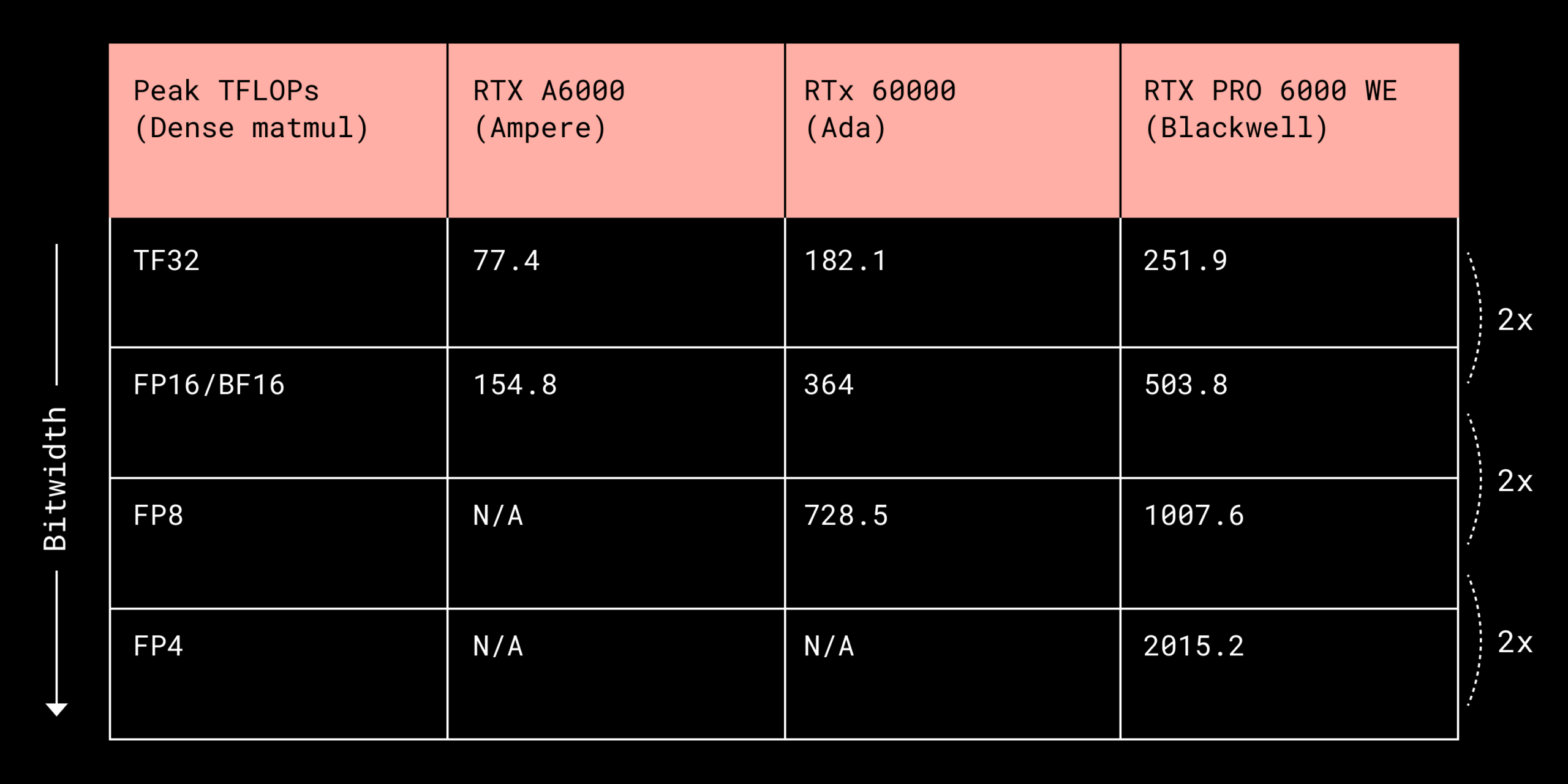
대규모 언어 모델을 실행하는 비용의 대부분은 행렬 곱셈 연산에서 발생합니다. 이 연산은 GPU의 Tensor Core(NVIDIA) 또는 Matrix Core(AMD) 같은 전용 하드웨어에서 처리되는데, 흥미로운 특성이 하나 있습니다. 바로 숫자 정밀도를 절반으로 줄이면 처리량이 약 2배로 증가한다는 점입니다.
양자화는 이 특성을 활용하는 기술입니다. 16비트로 표현하던 숫자를 8비트나 4비트로 줄이면, 메모리 사용량이 줄어들고 연산 속도가 빨라지며 에너지 효율도 개선됩니다. 예를 들어 16비트에서 8비트로 양자화하면 256개 구간으로 값을 근사하는 방식이죠. 4비트까지 내려가면 여러 값을 하나의 데이터 타입에 묶어 저장하는 비트패킹(bitpacking)이 필요합니다.
Dropbox는 Dash 제품에서 텍스트, 이미지, 비디오, 오디오를 이해하는 모델들을 실행하면서 이런 최적화를 적극 활용하고 있습니다. 지연시간에 민감한 작업도 있고, 대량 데이터를 처리하는 처리량 중심 작업도 있는데, 양자화 포맷을 상황에 맞게 선택하는 것이 핵심입니다.
Pre-MXFP 시대: 명시적 역양자화의 시대
MXFP 포맷이 등장하기 전까지는 주로 정수 기반 양자화를 사용했습니다. 대표적인 방식이 A16W4(활성화 16비트, 가중치 4비트)와 A8W8(활성화 8비트, 가중치 8비트)입니다. 문제는 서로 다른 정밀도의 텐서를 곱셈하려면 먼저 명시적으로 역양자화해서 같은 포맷으로 맞춰야 한다는 점이었습니다.
이 방식은 메모리 대역폭이 병목인 상황에서는 효과적입니다. 데이터 전송량을 줄이는 것만으로도 성능이 개선되니까요. 하지만 연산 자체가 병목인 경우엔 역양자화 과정이 오히려 오버헤드가 되어 성능을 떨어뜨립니다.
Dropbox의 테스트 결과를 보면 이 차이가 명확합니다. 배치 크기가 작고 메모리 중심일 때는 A16W4가 유리하지만, 배치가 커지고 연산이 많아지면 A8W8이 더 빠릅니다.

A16W4는 심지어 16비트 연산보다 느려지기도 하는데, 역양자화 비용 때문입니다.
실무에서는 AWQ나 HQQ 같은 기법이 널리 쓰입니다. 이들은 선형 양자화에 그룹핑을 결합한 방식인데, 32~128개 원소 단위로 스케일 파라미터를 공유해서 정확도 손실을 최소화합니다.

활성화 쪽에서는 채널별 양자화나 블록별 양자화를 사용하죠. DeepSeek V3 같은 모델은 블록별 방식을 채택해 이상치(outlier)의 영향을 줄이고 정확도를 유지합니다.
MXFP: 하드웨어가 직접 양자화를 처리하다
MXFP(Microscaling Format)는 양자화 게임의 규칙을 바꿨습니다. 이전 방식과 달리 Tensor Core가 양자화된 데이터를 직접 처리할 수 있게 만들었거든요. 소프트웨어에서 역양자화할 필요 없이, 하드웨어가 알아서 스케일 팩터를 적용하면서 연산합니다.
MXFP는 32개 원소 단위로 대칭 양자화를 수행하고, E8M0 포맷으로 스케일을 저장합니다. E8M0는 2의 거듭제곱만 표현할 수 있어서 FP4 정확도가 다소 떨어지는데, Dropbox는 간단한 후처리 조정만으로도 대부분의 정확도를 회복할 수 있다고 설명합니다.
NVIDIA는 이를 개선한 NVFP4도 내놨습니다. 그룹 크기를 16으로 줄이고 E4M3 FP8 스케일을 사용해서 수치 안정성을 높인 버전이죠. 하지만 GPU 아키텍처마다 명령어가 달라서 sm_100용 커널이 sm_120에서 안 돌아가는 등 이식성 문제가 있습니다. 다행히 Triton 같은 프레임워크가 최근 sm_120 MXFP 지원을 추가하면서 상황이 나아지고 있습니다.
실전 적용과 남은 과제
Dropbox는 Dash에서 대화형 AI, 멀티모달 검색, 문서 이해, 음성 처리 같은 기능을 제공하면서 이미 다양한 양자화 전략을 운영 중입니다. 지연시간, 안정성, 비용 제약을 모두 만족시키려면 상황에 맞는 포맷 선택이 필수적이죠.
하지만 아직 갈 길이 멉니다. MXFP와 NVFP4 같은 포맷은 표준화되었지만 프레임워크 지원이 완전하지 않고, FP4 모델도 아직 널리 배포되지 않았습니다. 오픈소스 런타임에서 여러 GPU 아키텍처를 완벽히 지원하는 것도 현재 진행형입니다.
원문에는 이 외에도 Flash Attention 3, Sage Attention 같은 어텐션 최적화 기법이나 QuiP#, GPTVQ 같은 비선형 양자화 실험들이 소개되어 있습니다. Dropbox는 앞으로 하드웨어가 계속 진화하고 더 낮은 비트로 가는 흐름 속에서, 프레임워크 성숙도와 새로운 양자화 기법이 핵심이 될 것이라고 전망합니다.
참고자료:
답글 남기기