양자화
Ollama MLX 엔진 업데이트, Apple Silicon 로컬 모델 품질과 속도를 동시에 끌어올린 방법
Ollama MLX 엔진 업데이트로 Apple Silicon에서 품질 손실 절반 감소, 출력 속도 20% 향상, 에이전트 워크플로우 개선. NVFP4 양자화 지원과 스냅샷 시스템의 의미를 정리합니다.
Written by

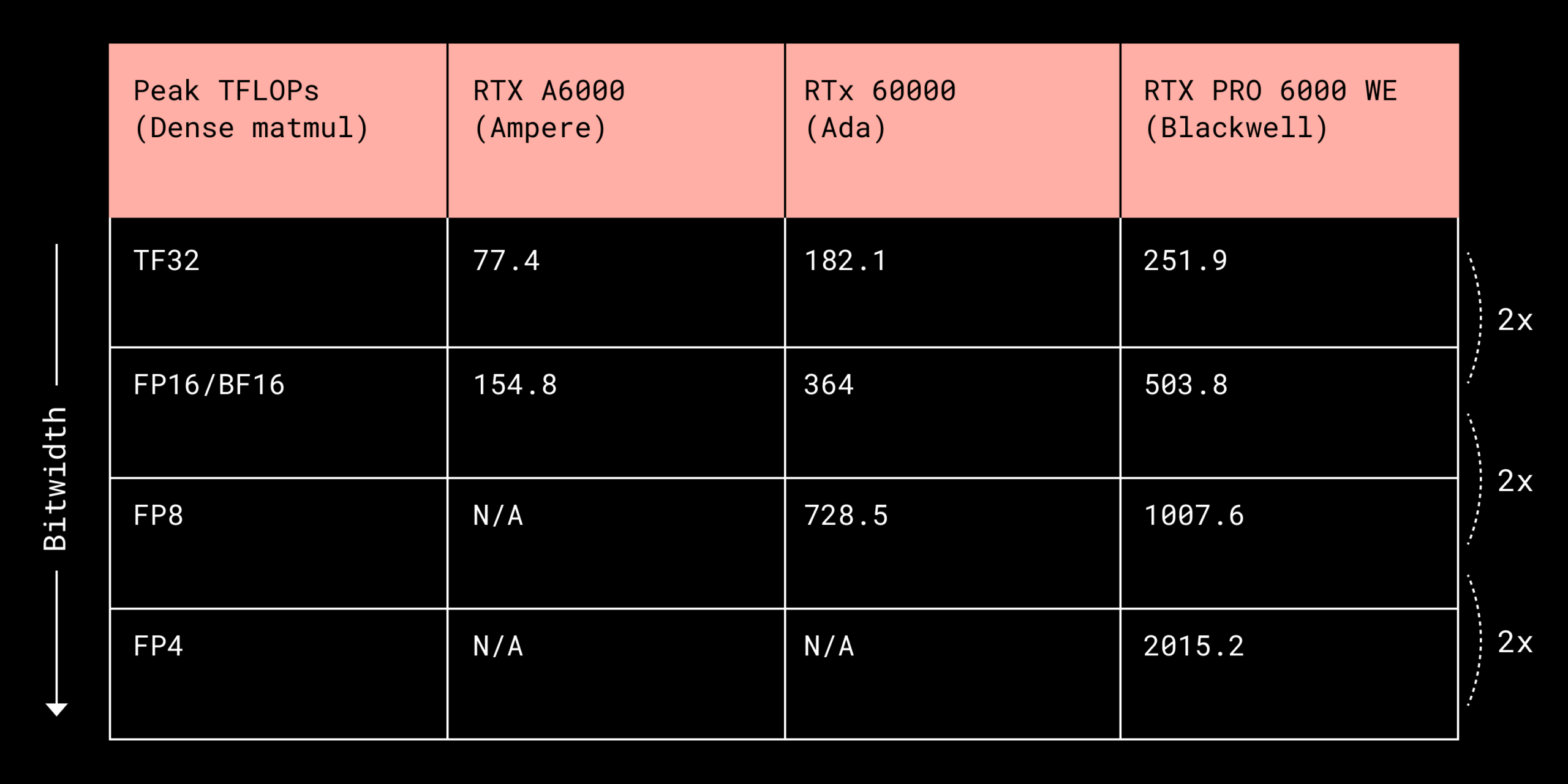
AI 모델 실행 비용 절반으로, Dropbox가 설명하는 Low-bit 추론 최적화
AI 모델 실행 비용을 절반으로 줄이는 Low-bit 추론 기술. Dropbox가 설명하는 양자화 기법과 MXFP 포맷의 실무 적용 사례를 소개합니다.
Written by
LLM 쿼리 하나에 전기 얼마나 쓸까, DeepSeek부터 GPT까지 에너지 실측
LLM 쿼리 하나에 실제로 얼마나 전기가 쓰일까? DeepSeek R1부터 GPT-OSS-120B까지 오픈소스 벤치마크 데이터로 실측한 에너지 비용과 벤치마크의 함정을 분석합니다.
Written by

VLM 실행하기: CPU 최적화부터 클라우드까지
VLM을 실행하는 방법을 완벽 정리했습니다. 다양한 모델 비교부터 Intel CPU 최적화, Ollama Cloud 활용까지 실무에 바로 적용할 수 있는 가이드입니다.
Written by

AI 추론 비용 90% 절약하는 3단계 최적화 전략
LLM 운영 비용을 10-15배 줄이는 체계적인 3단계 최적화 전략을 소개합니다. GPU 활용률 극대화부터 메모리 병목 해결, 세부 비용 최적화까지 실제 현업에서 적용 가능한 구체적인 기법들을 다룹니다.
Written by
언어 모델 배포 최적화 완전 가이드: 개발자를 위한 실전 기법과 코드 예제
개발자를 위한 언어 모델 크기 최적화 완전 가이드입니다. 지식 증류, 프루닝, 양자화, LoRA 등 핵심 기법들을 실제 코드 예제와 함께 상세히 설명하고, 메모리 사용량을 20-50% 줄이고 추론 속도를 2-5배 향상시키는 실무 적용 방법을 제시합니다.
Written by

DeepSeek-R1-0528 모델을 내 컴퓨터에서 실행하기: 715GB 거대 AI 모델의 로컬 구동 완벽 가이드
DeepSeek-R1-0528 대형 AI 모델을 개인 컴퓨터에서 실행하는 완벽 가이드. 715GB 모델을 80% 축소하여 로컬 환경에서 구동하는 방법을 단계별로 설명합니다.
Written by

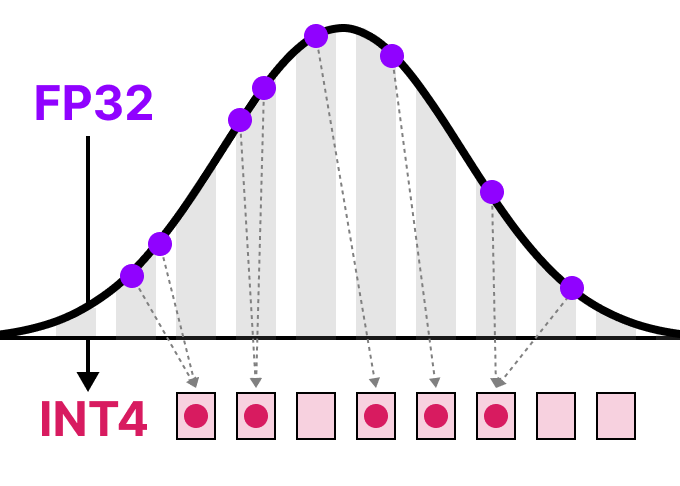
AI 모델 양자화: 더 작고 빠른 언어 모델을 위한 핵심 기술
AI 모델 양자화 기술의 원리와 다양한 방법을 알아보고, 더 작고 빠른 언어 모델을 위한 최신 트렌드와 적용 사례를 소개합니다. 대용량 AI 모델을 일반 컴퓨터나 모바일 기기에서도 효율적으로 실행할 수 있는 핵심 기술을 쉽게 이해할 수 있습니다.
Written by
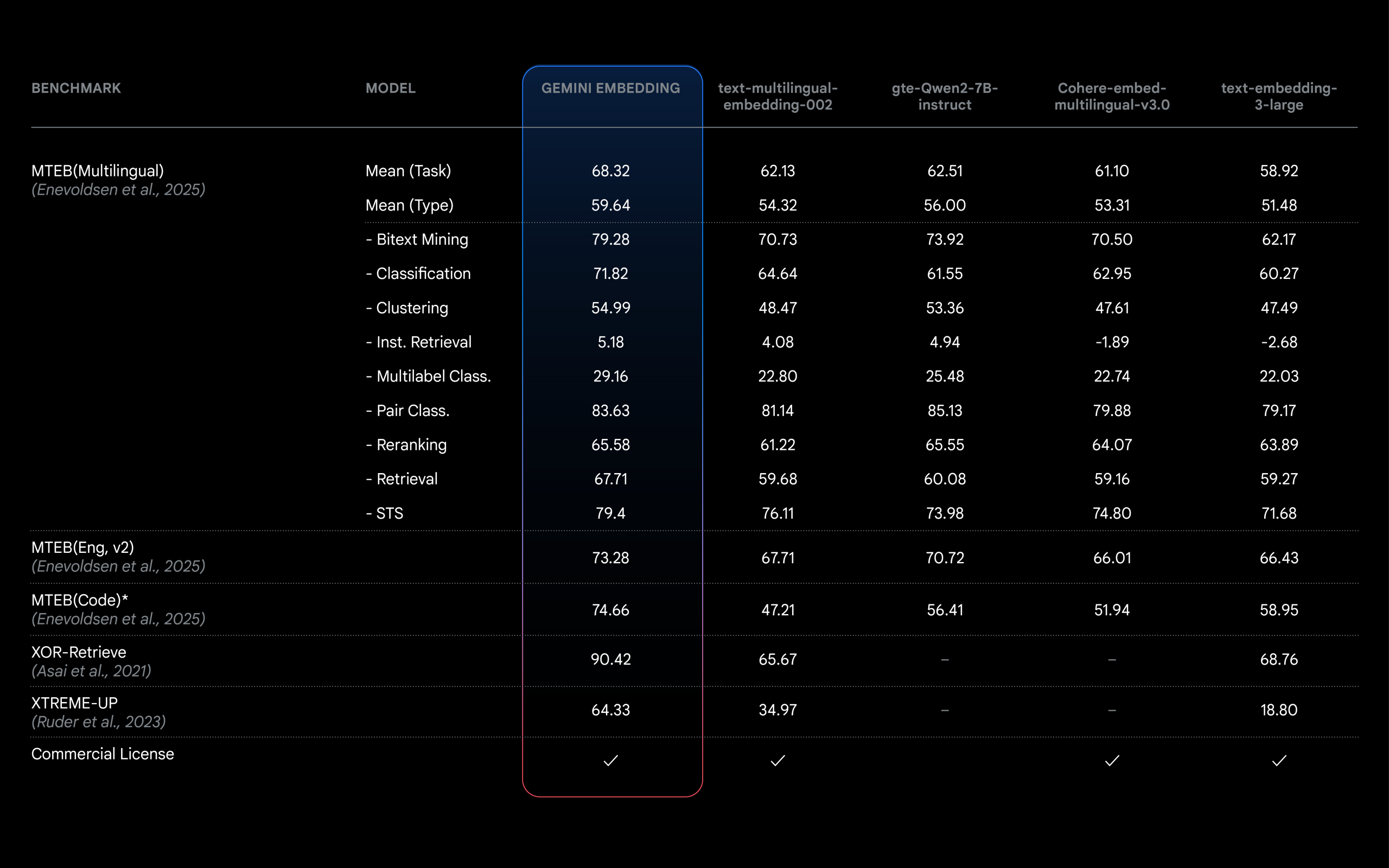
크롬의 새로운 임베딩 모델: 더 작고 빠르면서도 동일한 성능 유지
구글 크롬의 새로운 임베딩 모델이 어떻게 57% 더 작아졌는데도 성능은 유지하는지, 그리고 이 기술적 발전이 사용자와 엣지 AI의 미래에 어떤 의미를 가지는지 알아봅니다.
Written by
작지만 강력한 AI 혁명: Phi-4-mini-reasoning으로 엣지 디바이스의 추론 능력 향상하기
마이크로소프트의 Phi-4-mini-reasoning 모델이 AI 혁신의 새로운 장을 열고 있습니다. 이 소형 언어 모델이 어떻게 엣지 디바이스에서 강력한 추론 능력을 제공하고, Microsoft Olive, Apple MLX, Ollama를 통해 쉽게 배포할 수 있는지 알아보세요.
Written by
