수천 개의 노트를 쌓아놨지만 정작 필요할 때 찾지 못한 경험, 있으신가요? 분명 어디선가 읽고 메모했던 아이디어인데 검색어가 떠오르지 않거나, 서로 연결될 법한 노트들이 떨어져 있어 발견하지 못하는 경우 말이죠.

MotherDuck의 데이터 엔지니어 Simon Späti가 자신의 8,963개 Obsidian 노트에 AI 검색 시스템을 구축한 사례를 공개했습니다. 흥미로운 점은 OpenAI나 Pinecone 같은 상용 서비스 대신 DuckDB를 벡터 데이터베이스로 활용했다는 것입니다.
출처: Building an Obsidian RAG with DuckDB and MotherDuck – MotherDuck Blog
왜 개인 노트에 RAG를 붙이나
일반적인 RAG(Retrieval-Augmented Generation) 시스템은 외부 지식을 AI에 제공하는 용도로 쓰입니다. 하지만 Simon이 구축한 시스템은 조금 다릅니다. LLM을 붙이지 않고 검색(Retrieval)과 연결(Augmented) 기능만 구현했죠.
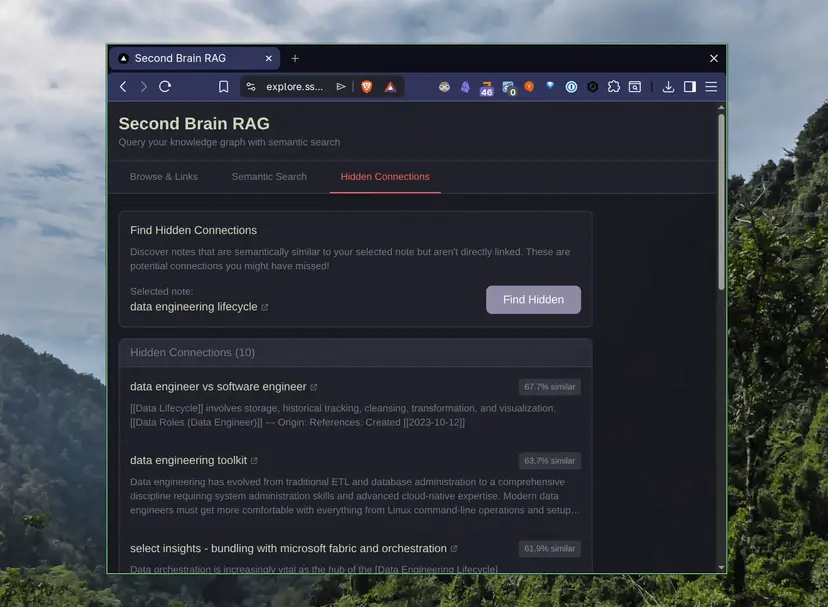
목표는 명확합니다. 키워드가 아닌 의미로 노트를 찾고, 직접 연결하지 않았지만 관련 있는 노트들을 발견하고, 2단계 떨어진 노트까지 탐색하는 것입니다. 예를 들어 “함수형 데이터 엔지니어링”을 검색하면 그 키워드가 없어도 비슷한 개념을 다룬 노트들이 나타납니다.
특히 “숨겨진 연결(hidden connections)” 기능이 유용합니다. 위키링크로 직접 연결되지 않았지만 의미적으로 가까운 노트들을 찾아주죠. Simon은 몇 달 간격으로 쓴 노트들이 실제로는 같은 주제를 다루고 있었다는 걸 이 기능으로 발견했다고 합니다.
DuckDB를 벡터 데이터베이스로
핵심은 DuckDB의 Vector Similarity Search(VSS) 확장 기능입니다. 일반적으로 벡터 검색에는 Pinecone이나 Weaviate 같은 전용 벡터 DB를 쓰지만, DuckDB 하나로 관계형 데이터와 벡터를 함께 다룰 수 있습니다.
시스템은 이렇게 작동합니다. 먼저 노트를 512자 정도의 청크로 나누되, 마크다운 구조를 존중합니다. 제목이나 코드 블록을 자르지 않죠. 각 청크는 BGE-M3 모델로 1,024차원 벡터로 변환됩니다. 이때 노트 제목과 섹션 제목을 앞에 붙여서 맥락을 보강합니다.
검색할 때는 쿼리를 같은 방식으로 벡터로 만들어 코사인 유사도로 비교합니다. 여기에 Obsidian의 백링크 구조를 활용한 “그래프 부스팅”을 더합니다. 위키링크로 연결된 노트는 유사도에 1.2배를 곱해 순위를 높이는 방식이죠. 링크 구조는 임베딩이 놓치는 의도를 담고 있기 때문입니다.
로컬에서는 DuckDB의 HNSW 인덱스로 빠르게 검색하고, 웹 버전은 MotherDuck의 WASM 클라이언트가 브라우저에서 직접 쿼리를 실행합니다. VSS가 없는 WASM 환경에서는 DuckDB의 리스트 함수로 코사인 유사도를 직접 계산하는데, 전용 벡터 DB 없이도 충분히 잘 작동한다고 합니다.
로컬 우선, 그러나 웹으로도
이 시스템의 철학은 “로컬 우선(local-first)”입니다. 민감한 개인 노트를 클라우드 AI 서비스에 올리지 않고, 로컬에서 임베딩을 생성하고 검색합니다. 하지만 공개 노트는 웹앱으로도 제공하죠.
웹앱 구조는 세 가지 서비스로 나뉩니다. Vercel의 Next.js 프론트엔드가 MotherDuck WASM 클라이언트로 브라우저에서 직접 쿼리하고, MotherDuck 클라우드에 DuckDB 데이터베이스가 있고, Railway에 BGE-M3 모델을 호스팅하는 FastAPI 서비스가 있습니다. 브라우저가 검색어를 보내면 임베딩 서비스가 1,024차원 벡터로 변환해 돌려주고, 그걸로 MotherDuck를 쿼리하는 방식입니다.
이 구조의 장점은 서버리스라는 점입니다. 데이터베이스 서버를 띄우거나 관리할 필요가 없고, Hugging Face API의 속도 제한이나 타임아웃 문제도 피할 수 있습니다.
Claude Code의 Plan Mode
Simon은 이 웹앱을 Claude Code로 몇 시간 만에 만들었다고 합니다. 핵심은 “Plan Mode”였죠. Plan Mode는 AI가 코드를 바로 쓰지 않고, 먼저 분석하고 질문하고 구현 계획을 세우는 단계입니다.
이 방식이 효과적인 이유는 인간이 주니어 개발자를 지도하는 방식과 비슷하기 때문입니다. 추상적으로 원하는 걸 설명하면 AI가 계획을 마크다운으로 작성하고, 시니어가 검토하고 피드백하고, 그 다음에 실제 구현이 시작됩니다.
특히 MotherDuck MCP를 활용해 Claude Code가 데이터베이스에 직접 연결해 테이블 구조와 관계를 파악하게 했습니다. SHOW TABLES로 스키마를 확인하고, 실제 데이터를 샘플링하면서 웹앱을 설계했죠. 기존 DuckDB 데이터베이스와 MotherDuck 문서를 참고해 거의 완성된 첫 버전이 나왔습니다.
하지만 Simon은 경고도 덧붙입니다. AI 에이전트가 방향 없이 돌아가게 두면 수백 줄의 코드를 만들어내지만 엉뚱한 문제를 풀 수 있다는 것이죠. “인간 설계자”는 여전히 필요하다고 강조합니다.
직접 써보려면
GitHub 저장소(Obsidian-note-taking-assistant)에서 코드를 받아 자신의 Obsidian 볼트에 바로 적용할 수 있습니다. .env 파일에 볼트 경로만 설정하고 make ingest를 실행하면 로컬 DuckDB 파일이 만들어집니다. 웹 UI까지 원한다면 make sync-motherduck로 MotherDuck에 동기화하고 Next.js 앱을 배포하면 됩니다.
핵심은 이 시스템이 당신의 생각, 당신의 연결을 기반으로 작동한다는 점입니다. 인터넷을 크롤링한 정보가 아니라, 당신이 직접 쓰고 선별한 노트에서 숨겨진 통찰을 찾아냅니다. 노트가 많을수록, 오래 쌓을수록 더 유용해지는 도구죠.
참고자료:
답글 남기기