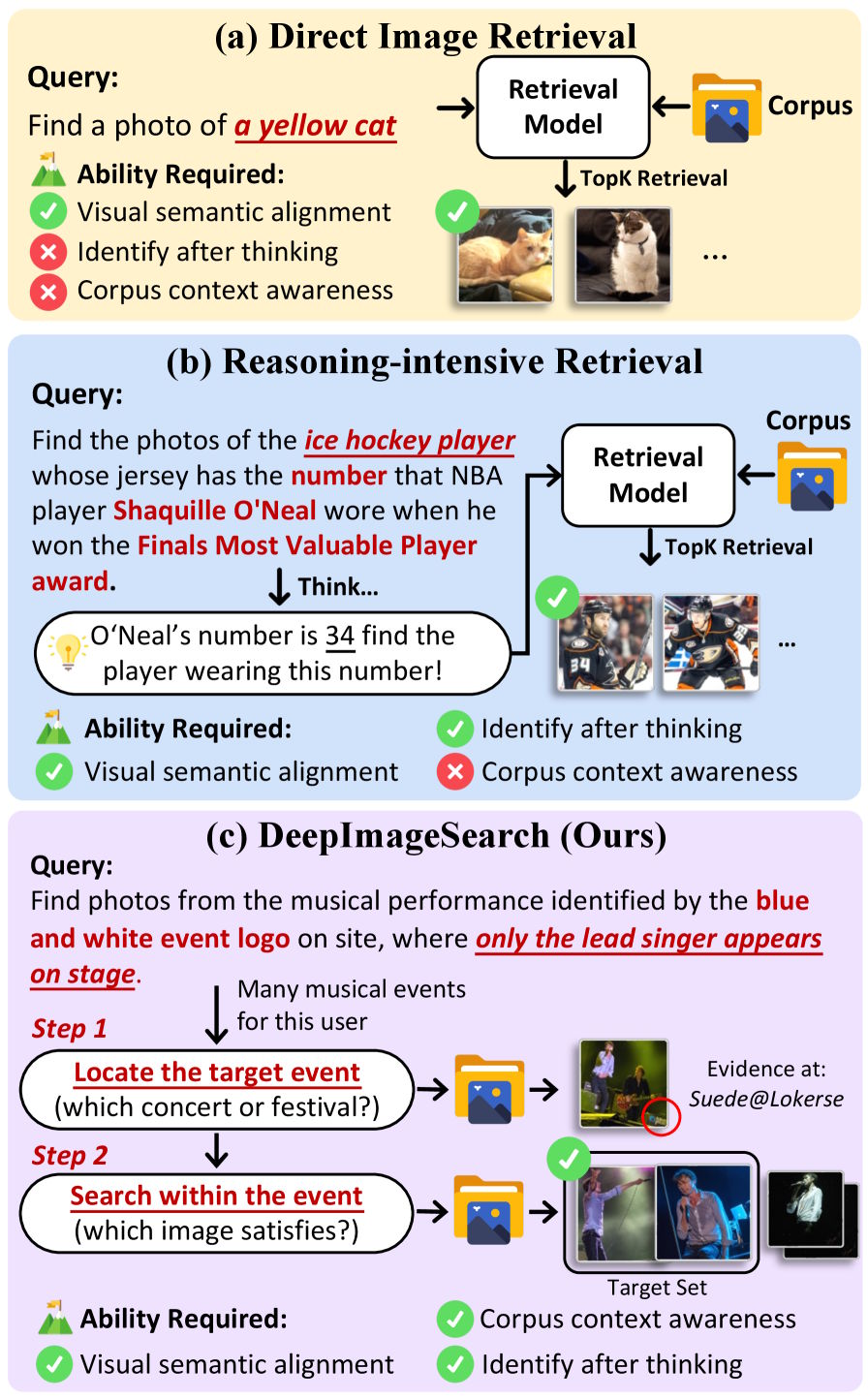
콘서트 사진을 찾고 싶은데, 기억나는 건 “파란색 로고가 있던 공연장, 보컬만 무대에 있던 순간”뿐입니다. 이 정도면 충분할 것 같죠. 하지만 현재 AI 이미지 검색은 이런 요청 앞에서 사실상 속수무책입니다.

중국 런민대학과 OPPO 연구소 연구팀이 개인 사진첩에서 특정 사진을 찾는 AI 모델의 능력을 측정하는 벤치마크 DISBench를 발표했습니다. 57명 사용자의 사진 10만 9천여 장을 대상으로 122개의 검색 쿼리를 테스트한 결과, 현재 최고 모델들도 낮은 성능을 보였습니다.
출처: DeepImageSearch: Benchmarking Multimodal Agents for Context-Aware Image Retrieval in Visual Histories – arXiv
현재 AI 검색은 랜덤과 다를 바 없다
Qwen3-VL, Seed 1.6 같은 최신 임베딩 모델들은 상위 3개 결과 안에 정답 이미지를 포함하는 비율이 고작 10~14%에 불과했습니다. 연구팀은 이마저도 상당 부분이 “운”이라고 평가합니다. 개인 사진첩에는 시각적으로 비슷한 사진이 많아서, 모델이 겉모습만 보고 아무 사진이나 끌어오기 때문입니다.
연구팀은 더 공정한 평가를 위해 ImageSeeker 프레임워크를 따로 만들어 멀티모달 모델들에게 더 많은 도구를 줬습니다. 시맨틱 검색은 물론, 타임스탬프와 GPS 데이터 접근, 웹 검색, 중간 결과를 기록하는 메모리 메커니즘까지 갖췄죠. 이 환경에서 가장 좋은 성능을 낸 건 Anthropic의 Claude Opus 4.5로 정답률 약 29%, Gemini 3 Pro Preview가 약 25%, GPT-5.2는 약 13%였습니다. 일반 이미지 검색 벤치마크에서 거의 완벽한 점수를 내는 바로 그 모델들입니다.
문제는 시각이 아니라 계획 능력
연구팀의 오류 분석에서 흥미로운 패턴이 드러납니다. 실패의 36~50%는 “reasoning breakdown”, 즉 맥락은 맞게 찾았는데 멀티스텝 탐색 도중 목표를 잃거나 너무 일찍 검색을 종료하는 것이었습니다. 시각적으로 비슷한 사물을 구별하지 못하는 오류는 그보다 훨씬 적었습니다.
도구별 영향도 분석도 이를 뒷받침합니다. 성능에 가장 큰 영향을 준 도구는 타임스탬프와 GPS 같은 메타데이터였습니다. AI 모델이 시각적으로 비슷한 사진들을 구분하려면 “언제, 어디서”라는 맥락이 결정적입니다.
또 하나 주목할 실험이 있습니다. 같은 쿼리를 여러 번 병렬로 실행해 최선의 결과를 고르면 정답률이 약 70% 올랐습니다. 모델이 이 과제를 풀 잠재력은 있지만, 단 한 번의 시도에서 일관되게 성공하지 못하는 것입니다.
이미지 검색의 다음 과제
연구팀이 제안하는 DeepImageSearch는 사진 한 장씩 매칭하는 대신, AI 에이전트가 사진첩을 자율적으로 탐색하며 여러 이미지에서 단서를 조합하는 방식입니다. 기존 검색이 “이 사진이 쿼리와 얼마나 비슷한가”를 묻는다면, DeepImageSearch는 “이 단서들을 모으면 어떤 사진에 도달하는가”를 묻는 셈입니다.
연구팀은 이 벤치마크를 차세대 검색 시스템의 테스트 기준으로 제시합니다. 모델이 이미지를 더 잘 볼 필요가 있는 게 아니라, 더 잘 계획하고 중간 결과를 추적해야 한다는 것이 이번 연구의 핵심 주장입니다. 코드와 데이터셋, 리더보드는 모두 공개되어 있습니다.
참고자료:
- Why AI still can’t find that one concert photo you’re looking for – The Decoder
- DeepImageSearch GitHub – GitHub
답글 남기기