프롬프트를 고쳐 쓰고, 표현을 바꾸고, 맥락을 추가해도 LLM 답변이 마음에 안 들었던 경험 있으신가요? Google Research 연구팀이 훨씬 단순한 방법을 제안합니다. 프롬프트를 그냥 두 번 복사해 붙여넣으면 됩니다.

Google Research의 Yaniv Leviathan, Matan Kalman, Yossi Matias 연구팀이 “Prompt Repetition Improves Non-Reasoning LLMs”라는 논문을 발표했습니다. Gemini, GPT-4o, Claude, DeepSeek 등 주요 LLM 7종을 대상으로 7가지 벤치마크에서 실험했고, 프롬프트 반복이 출력 토큰 수나 지연 시간을 늘리지 않으면서 정확도를 개선한다는 결과를 확인했습니다.
출처: Prompt Repetition Improves Non-Reasoning LLMs – arXiv (Google Research)
LLM이 토큰을 처리하는 방식의 한계
LLM은 기본적으로 인과적(causal) 방식으로 훈련됩니다. 토큰을 왼쪽에서 오른쪽으로 순서대로 처리하고, 각 토큰은 앞에 나온 토큰에만 주의를 기울일 수 있습니다. 이 구조 때문에 프롬프트 내 정보의 순서가 모델 성능에 영향을 줍니다.
예를 들어 “질문 + 보기” 순서와 “보기 + 질문” 순서는 같은 내용이지만 모델에게 다르게 처리됩니다. 보기가 먼저 나오면 모델은 질문을 보기 전에 보기를 처리하게 되고, 두 정보 사이의 연결이 약해질 수 있습니다.
프롬프트를 두 번 반복하면 이 문제가 완화됩니다. 동일한 프롬프트가 두 번 입력되면, 각 토큰이 관련 정보를 두 번 처리하게 됩니다. 모델이 입력을 해석하는 단계(prefill 단계)에서 더 강한 내부 표현이 형성되는 원리입니다. 이 과정은 답변을 생성하기 전에 일어나기 때문에 출력 형식이나 토큰 수에는 영향을 주지 않습니다.
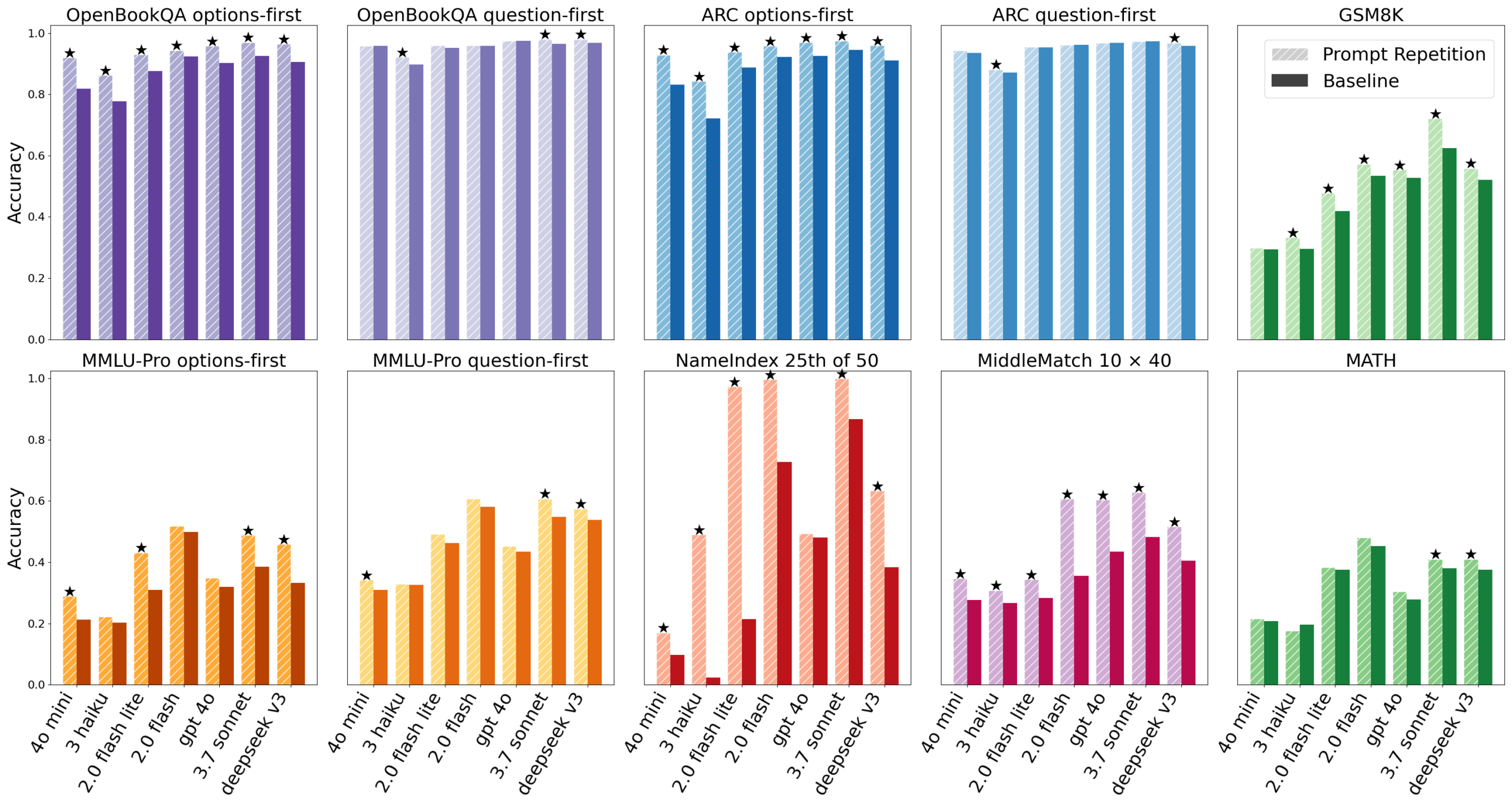
21%에서 97%로, 실험 결과
70개의 모델-벤치마크 조합 중 프롬프트 반복이 정확도를 개선한 경우는 47건이었고, 성능이 유의미하게 하락한 경우는 단 한 건도 없었습니다.
특히 눈에 띄는 결과는 연구팀이 직접 설계한 NameIndex 과제입니다. 50개의 이름 목록을 주고 “25번째 이름은 무엇인가?”라고 묻는 단순한 위치 추적 과제인데, Gemini 2.0 Flash Lite의 기본 정확도는 21.33%에 불과했습니다. 프롬프트를 반복하자 97.33%로 올라갔습니다. 추론이나 해석이 필요 없는 순수한 위치 파악 문제에서 모델이 얼마나 취약한지, 그리고 반복이 얼마나 효과적으로 보완하는지를 보여주는 사례입니다.
개선 효과는 주로 추론이 필요 없는 과제, 즉 객관식 문제, 목록에서의 위치 파악, 구조화된 데이터 추출, 분류 과제에서 두드러졌습니다. 반면 “단계적으로 생각해보세요(Think step by step)”처럼 모델이 추론 과정을 직접 서술하도록 유도하는 경우에는 효과가 중립적이었습니다. 추론 과정에서 모델이 이미 질문을 다시 처리하기 때문입니다.
비용 증가 없이 성능 향상
“정확도가 오른다면 비용도 오르지 않을까?”가 자연스러운 의문입니다. 실험 결과 출력 토큰 수는 늘지 않았고, 지연 시간도 거의 동일했습니다. 프롬프트 반복의 추가 연산은 병렬 처리가 가능한 prefill 단계에서 일어나기 때문입니다. Chain-of-Thought 프롬프팅처럼 모델이 생각을 길게 서술하게 만드는 방식과 달리, 생성 단계에는 영향을 주지 않습니다.
다만 예외가 있습니다. 프롬프트 자체가 매우 긴 경우, 특히 Claude 모델에서는 prefill 단계가 길어지면서 지연 시간이 소폭 증가했습니다. 또한 프롬프트를 두 배로 늘리면 컨텍스트 윈도우 한도에 더 빨리 다가설 수 있다는 점도 고려해야 합니다.
단순함이 주는 의외의 통찰
이 연구가 흥미로운 이유는 성능 향상 자체보다 그 원인에 있습니다. LLM의 인과적 구조가 만들어내는 ‘토큰 순서 의존성’은 모델이 크고 정교해져도 사라지지 않는 구조적 특성입니다. 그리고 프롬프트 반복이라는 단순한 방법이 이 한계를 부분적으로 우회할 수 있다는 점은, 추론 기능 없이 LLM을 빠르고 저렴하게 사용해야 하는 상황에서 의미 있는 선택지가 될 수 있습니다.
논문은 미래 방향으로 반복 횟수 조정, KV-cache 최적화, 프롬프트 일부만 반복하는 방식 등 13가지 후속 연구 아이디어도 제시하고 있습니다.
참고자료: Reddit r/LocalLLaMA 토론
답글 남기기