Claude가 코드나 문서를 깔끔하게 만들어줄수록, 사용자는 오히려 그 결과물을 덜 검토합니다. Anthropic이 약 1만 건의 대화를 분석해서 발견한 패턴입니다.

Anthropic이 2026년 2월, Claude 사용자 약 9,830건의 대화를 분석한 ‘AI Fluency Index’ 보고서를 발표했습니다. 단순히 “사람들이 AI를 얼마나 자주 쓰는가”가 아니라, “얼마나 잘 쓰는가”를 측정하려는 시도입니다.
출처: Anthropic Education Report: The AI Fluency Index – Anthropic
AI 유창성을 어떻게 측정했나
Anthropic은 Rick Dakan, Joseph Feller 두 교수와 함께 ‘AI 유창성(AI Fluency)’을 24가지 구체적인 행동으로 정의했습니다. 이 중 Claude.ai 대화에서 직접 관찰 가능한 11가지 지표를 분석했는데, 크게 세 가지 유형으로 나뉩니다. 목표를 구체적으로 설명하거나 예시를 제공하는 ‘지시 행동’, 이전 답변을 바탕으로 계속 다듬어 나가는 ‘반복·개선 행동’, 그리고 Claude의 추론을 검토하거나 팩트를 확인하는 ‘검증 행동’입니다.
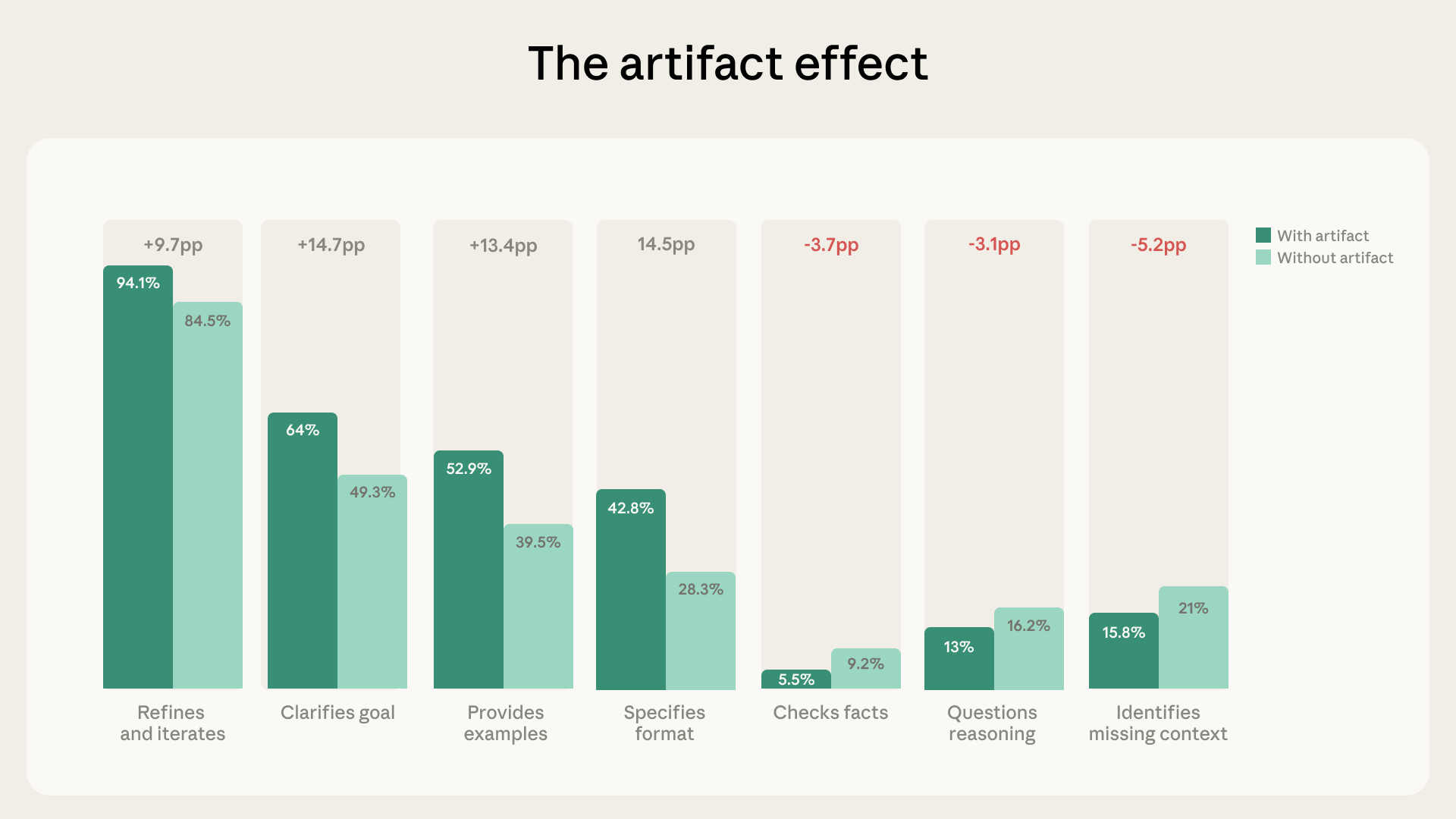
완성도가 높을수록 검증은 줄어든다
전체 대화의 12.3%는 코드, 문서, 인터랙티브 툴 같은 ‘아티팩트(artifact)’를 생성하는 대화였습니다. 이런 대화에서 사용자들은 처음부터 훨씬 정교하게 지시를 내립니다. 목표 명확화(+14.7%p), 포맷 지정(+14.5%p), 예시 제공(+13.4%p) 모두 일반 대화보다 높았습니다.
그런데 검증 행동은 정반대였습니다. 맥락 누락 지적은 5.2%p, 팩트 확인은 3.7%p, 추론 검토는 3.1%p 모두 줄었습니다. 지시를 더 잘할수록, 결과물을 덜 의심하게 된 겁니다.
Anthropic은 몇 가지 가능한 설명을 제시합니다. 결과물이 완성된 것처럼 보이면 실제로 완성됐다고 여길 수 있고, UI 디자인처럼 정확성보다 심미성이 중요한 작업일 수도 있습니다. 또는 코드를 별도 환경에서 직접 실행해보는 것처럼, 대화 밖에서 검증이 이뤄지는 경우도 있죠. 어느 쪽이든, Anthropic 스스로 “복잡한 작업일수록 Claude가 가장 어려움을 겪는다”고 밝히고 있는 만큼 이 패턴은 주목할 만합니다.
반복·개선이 모든 유창성 행동과 연결된다
보고서에서 가장 강하게 나타난 패턴은 반복·개선과 다른 모든 유창성 행동 사이의 상관관계입니다. 전체 대화의 85.7%에서 반복·개선 행동이 관찰됐는데, 이런 대화는 그렇지 않은 대화보다 평균 2배 더 많은 유창성 행동을 보였습니다. 특히 추론 검토는 5.6배, 맥락 파악은 4배 더 자주 나타났습니다.
협업 방식을 명시적으로 안내하는 사용자는 전체의 30%에 불과했습니다. “내 가정이 틀리면 반박해줘”나 “답을 주기 전에 추론 과정을 먼저 보여줘” 같은 지시가 대화 전체의 흐름을 바꿀 수 있다고 Anthropic은 설명합니다.
단, 무작정 대화를 길게 이어가는 것이 능사는 아닙니다. 대화창에 관련 없는 맥락이 쌓일수록 AI 출력 품질이 떨어진다는 연구 결과도 있거든요. 언제 새 대화를 시작해야 할지 아는 것 자체도 AI 유창성의 한 부분입니다.
아직은 초기 측정값
이번 연구는 2026년 1월 한 주간 Claude.ai 초기 사용자 집단을 대상으로 한 만큼, 일반 사용자 전체를 대표하기는 어렵습니다. Anthropic도 이 점을 명확히 인정하며, 이번 결과를 “현재 상태의 기준선”으로 삼겠다고 밝혔습니다. 향후에는 신규 사용자와 경험 많은 사용자를 비교하는 코호트 분석, 대화 밖에서 일어나는 행동(AI 생성 결과물을 공유할 때 출처를 밝히는지 등)에 대한 질적 연구도 이어질 예정입니다.
AI를 자주 쓴다고 잘 쓰는 게 아니라는 것, 그리고 그걸 데이터로 측정하기 시작했다는 것이 이 보고서의 핵심입니다. 11가지 유창성 지표 각각이 실제 대화에서 얼마나 나타나는지, 어떤 지표가 가장 드문지는 원문 차트에서 확인할 수 있습니다.
답글 남기기