개발 환경에서 완벽하게 작동하던 에이전트가 실제 사용자를 만나는 순간 예상치 못한 행동을 합니다. 이건 버그가 아닙니다. 에이전트의 본질적인 특성입니다.

LangChain이 수십 개 팀의 에이전트 프로덕션 배포 경험을 바탕으로, 기존 소프트웨어 모니터링 방식이 AI 에이전트에는 왜 통하지 않는지, 그리고 무엇이 필요한지를 정리한 글을 발표했습니다. 에이전트 특유의 두 가지 특성이 모니터링 전략을 근본부터 바꿔야 하는 이유를 설명합니다.
출처: You don’t know what your agent will do until it’s in production – LangChain Blog
기존 모니터링이 에이전트에 통하지 않는 이유
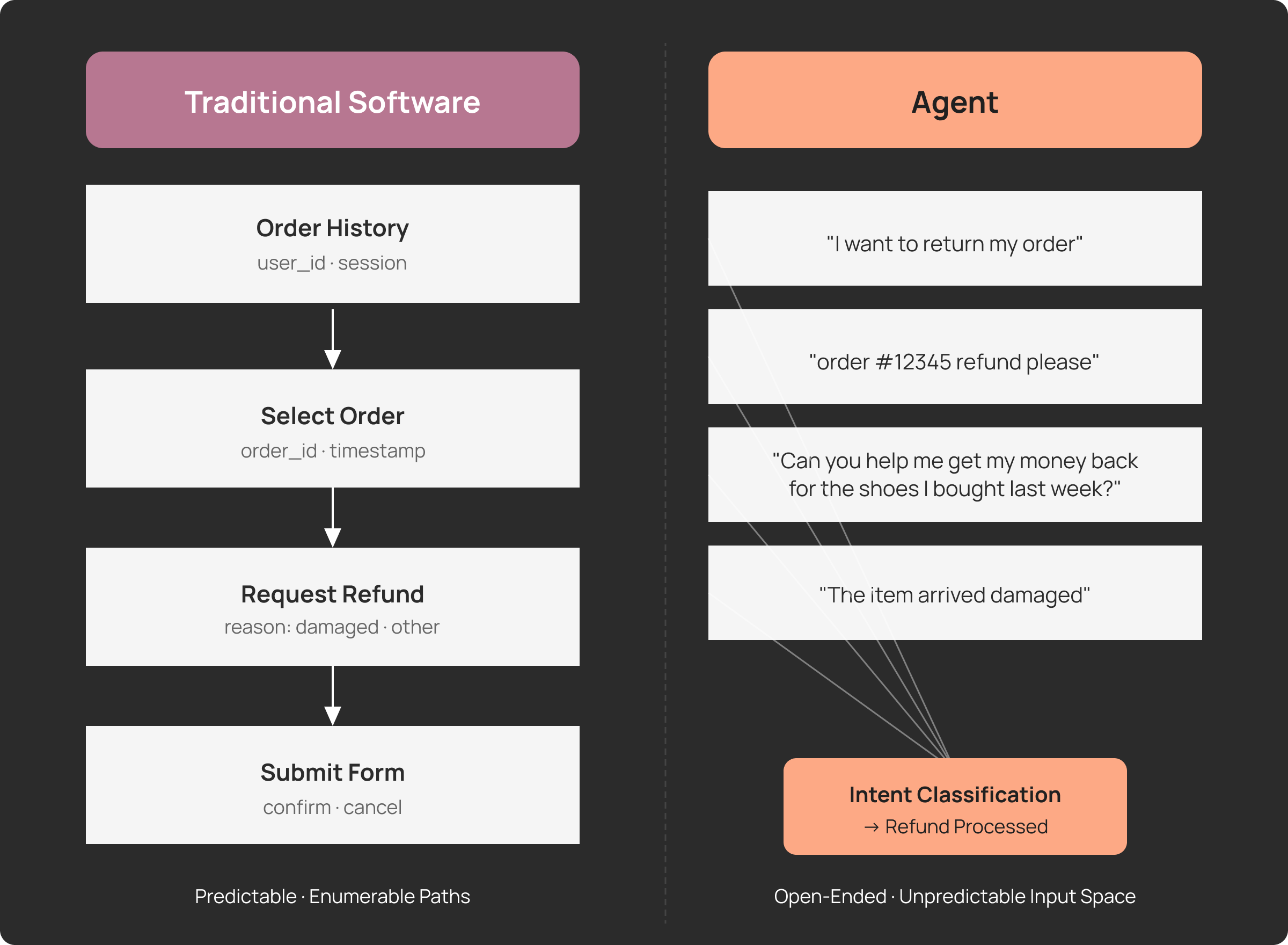
전통적인 소프트웨어는 입력 공간이 닫혀 있습니다. 버튼, 드롭다운, 정해진 API 형식. 사용자가 할 수 있는 행동을 열거할 수 있기 때문에, 테스트도 포괄적으로 짤 수 있습니다.
에이전트는 다릅니다. 자연어를 입력으로 받는 순간, 가능한 입력의 수는 사실상 무한해집니다. 환불을 원하는 사용자 한 명이 이렇게 말할 수 있습니다.
- “주문한 거 환불하고 싶어요”
- “지난주에 산 신발 돈 돌려받을 수 있나요?”
- “받은 물건이 파손됐는데 어떻게 해요?”
- “order #12345 refund please”
모두 같은 의도지만 표현은 전혀 다릅니다. 개발 단계에서 이 모든 변형을 미리 테스트하는 건 불가능합니다. 에이전트가 실제로 어떻게 사용될지는 실사용자가 들어오기 전까지 알 수 없습니다.
두 번째 문제는 LLM의 비결정성입니다. 동일한 입력에도 다른 출력이 나올 수 있고, 프롬프트의 미묘한 변화에 민감하게 반응합니다. 개발 환경에서 안정적으로 작동하던 프롬프트가 프로덕션의 엣지 케이스에서 실패하거나, 평가 단계에서 올바르게 도구를 선택하던 에이전트가 실제 사용자 쿼리에서 엉뚱한 도구를 고르는 일이 생깁니다.
모니터링의 대상이 달라진다
기존 APM 도구(Datadog, New Relic 등)는 레이턴시, 에러율, DB 쿼리 같은 시스템 지표를 봅니다. 구조화된 로그와 숫자 메트릭에 최적화되어 있습니다.
에이전트 옵저버빌리티는 시스템 지표가 아니라 입출력 자체를 봐야 합니다. 구체적으로는:
- 완전한 프롬프트-응답 쌍: 요청이 발생했다는 사실만이 아니라, 사용자가 무엇을 물었고 에이전트가 무엇을 답했는지
- 멀티턴 컨텍스트: 하나의 대화를 이루는 여러 교환을 묶어서 파악
- 에이전트 트래젝토리: 최종 응답까지 가는 과정에서 어떤 도구를 어떤 순서로 호출했는지
“POST /api/checkout 200 OK 342ms”로 요약되는 전통적인 웹 요청과 달리, 에이전트 인터랙션은 수십 단계를 거치는 자연어 대화입니다. 상태 코드만으로는 잘 됐는지 알 수 없습니다.
사람의 판단을 어떻게 스케일할 것인가
자연어 대화의 품질을 평가하려면 사람의 판단이 필요합니다. 응답이 유용했는가, 사용자 의도를 이해했는가, 관련 정보를 잘 가져왔는가 — 이런 질문은 숫자 메트릭으로 자동화할 수 없습니다.
개발 단계에서는 소수의 트레이스를 수동으로 검토하며 프롬프트를 조정하면 됩니다. 하지만 프로덕션에서 하루 1,000건 요청이 들어온다면, 전수 검토에는 매일 10~20시간이 필요합니다. 스케일이 깨집니다.
LangChain이 발견한 효과적인 조합은 두 가지입니다.
어노테이션 큐는 사람의 리뷰를 효율화합니다. 전체 로그를 뒤지는 대신, 부정적 피드백을 받은 실행, 비용이 높은 인터랙션, 특정 시간대 쿼리 등 검토 가치가 높은 트레이스만 선별해서 리뷰어에게 제시합니다. 평가 기준(루브릭)도 미리 정의해두어 리뷰 속도를 높입니다.
LLM 평가자는 사람이 볼 수 없는 규모를 커버합니다. 자동으로 프로덕션 트래픽을 평가하면서 일관성·톤 같은 레퍼런스 없이도 측정 가능한 품질 지표, 안전·정책 위반, 포맷 검증, 사용자 요청 카테고리 분류 등을 체크합니다. 단, LLM 평가자도 완벽하지 않습니다. 비용·레이턴시 문제로 보통 전체 트래픽의 10~20% 샘플링을 권장하고, 자동 평가만으로는 부족하기 때문에 주기적인 사람 리뷰와 병행하는 게 현실적입니다.
개발 루프와의 연결이 핵심
에이전트 옵저버빌리티가 기존 APM과 결정적으로 다른 점은, 모니터링이 개발 루프와 연결되어야 한다는 겁니다. 프로덕션 트레이스에서 실패 케이스를 발견하면 → 어노테이션 큐에서 레이블링하고 → 데이터셋에 추가해 → 수정된 프롬프트를 실험하고 → 프로덕션에서 다시 평가하는 사이클이 필요합니다. 전통적인 관찰 도구는 이 루프를 위해 설계되지 않았습니다.
또한 에이전트 옵저버빌리티를 사용하는 팀도 다릅니다. 인프라 엔지니어 중심의 기존 APM과 달리, AI/ML 엔지니어·프로덕트 매니저·도메인 전문가·데이터 사이언티스트가 함께 프로덕션 트레이스를 리뷰하고 개선 방향을 결정합니다.
에이전트를 프로덕션에 올리는 것은 배포의 끝이 아니라 관찰의 시작입니다. 원문에는 Insights Agent(트래픽 패턴 자동 발견), 대시보드·알럿 설계, 그리고 각 기능의 실제 구성 방법이 상세히 다뤄져 있습니다.
참고자료:
답글 남기기