어릴 때 월드 8-4를 클리어해봤다면, 사실 에이전틱 AI를 이해할 직관을 이미 갖고 있는 겁니다.

ML 엔지니어 Han Lee가 슈퍼 마리오의 요소들을 에이전틱 AI 스택에 1:1로 대응시켜 설명한 글을 공유합니다. 추론(reasoning)과 도구 사용(tool use)을 결합한 에이전틱 AI가 어떻게 개발되고 작동하는지, 게임 비유를 통해 풀어냈습니다.
출처: It’s-a Me, Agentic AI – Han Lee (leehanchung.github.io)
깡통 마리오에서 무적 마리오로
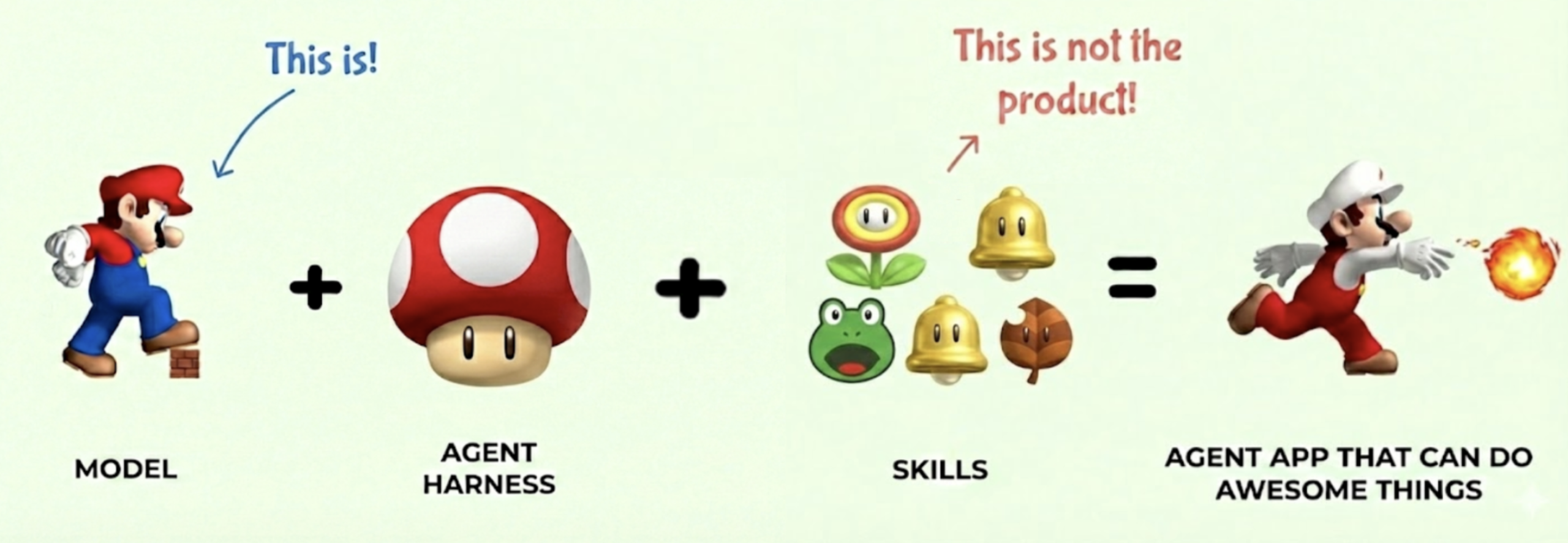
갓 나온 Small Mario는 굼바 한 방에 사망하는 기반 모델(base LLM)입니다. 방대한 데이터로 사전학습을 마쳤지만 실전에서 쉽게 무너지죠.
Super Mushroom을 먹으면 달라집니다. 이게 바로 모델 하네스(model harness), 즉 베이스 모델을 실제 서비스에 투입할 수 있도록 만드는 사후 훈련(post-training) 파이프라인 전체입니다. 명령을 따르도록 만드는 RLHF/DPO 튜닝, 시스템 프롬프트, 안전장치, 컨텍스트 관리까지 포함됩니다. 슈퍼버섯이 마리오의 ‘뭘 아는지’를 바꾸는 게 아니라 ‘얼마나 버티는지’를 바꾸듯, 모델 하네스는 모델의 지식이 아닌 프로덕션 환경에서의 생존력을 바꿉니다.
파워업 = AI 도구
슈퍼마리오가 되면 파워업을 줍기 시작합니다. 이게 에이전트 도구(tools)입니다. 불꽃 마리오(파이어 플라워)는 코드 실행 도구, 개구리 슈트는 웹 검색, 너구리 나뭇잎은 파일 시스템 접근, 해머 슈트는 셸/터미널 접근에 해당합니다. 별 파워는 확장 사고(extended thinking) 모드로, 비용은 크지만 복잡한 문제를 관통하는 힘입니다.
파워업이 마리오의 기본 점프나 달리기를 대체하지 않듯, 도구도 LLM의 추론과 언어 이해를 대체하지 않습니다. 범위를 넓혀줄 뿐이죠. 그리고 가장 어려운 부분이 여기에 있습니다. 어떤 상황에 어떤 도구를 써야 하는지 판단하는 것. 개구리 슈트는 수중 레벨에선 최강이지만 육지에선 무용지물이듯, 모델도 컨텍스트에 맞는 도구 선택을 학습해야 합니다.
플래그폴과 강화학습
각 레벨 끝의 깃발이 보상 신호(reward signal)입니다. 더 높이 잡을수록 점수가 높고, 어떤 레벨은 보스인 쿠파를 쓰러뜨려야 합니다.
여기서 핵심 질문이 등장합니다. 좋은 플레이를 어떻게 측정하냐는 것. 속도? 수집한 코인 수? 발견한 비밀 경로? 실제로는 여러 지표의 조합입니다. 이 보상 설계(reward modeling)가 ML 엔지니어링의 가장 중요한 작업입니다. 보상 함수를 잘못 짜면 마치 벽 통과 스피드런처럼 기술적으로는 목표를 달성하지만 전혀 원하지 않는 방식으로 행동하는 에이전트가 나옵니다. 에이전틱 AI판 굿하트의 법칙입니다.
마리오가 수없이 레벨을 반복하며 어떤 파이프가 지름길인지, 파워업을 언제 아껴야 하는지 배우는 것처럼, AI 모델도 강화학습(PPO, GRPO 등)을 통해 어떤 도구를 언제 쓸지, 언제 더 오래 생각할지를 학습합니다.
게임 뒤에 있는 엔지니어들
마리오가 스스로 훈련하지 않듯, 에이전트도 마찬가지입니다.
ML 엔지니어(MLE)는 게임 디자이너이자 코치입니다. 학습 환경을 구성하고, 무엇이 ‘잘한 것’인지를 정의하는 보상 함수를 설계합니다. 이 결정이 파이프라인 전체에서 가장 레버리지가 큰 선택입니다. MLSys 엔지니어는 그 설계를 수십만 개의 환경에서 실제로 돌리는 인프라를 담당합니다. 아무리 우아한 보상 함수도 대규모 학습 에피소드를 돌릴 인프라 없이는 마리오가 World 1-1을 벗어나지 못합니다.
원문은 이 외에도 에이전트 프레임워크, 멀티에이전트 시스템, 각 레벨 요소(굼바, 파이프, 뚫을 수 없는 구덩이)와 AI 개념의 대응 관계를 상세히 다루고 있습니다.
에이전틱 AI 스택 전체가 마리오와 이렇게까지 정확하게 맞아떨어지는 비유는 흔치 않습니다. 원문에는 각 레벨 요소와 AI 개념의 세부 대응표, 에이전트 프레임워크와 멀티에이전트 시스템까지 전체 그림이 담겨 있습니다.
답글 남기기