같은 GPU, 같은 모델인데 기능 하나를 켰을 뿐인데 비용이 58배 뛴다면 믿어지시나요?

AI 뉴스레터 AI Made Simple의 Dev가 긴 컨텍스트 추론이 트랜스포머의 경제성을 어떻게 무너뜨리는지, 그리고 업계가 이 문제를 풀기 위해 어떤 구조적 혁신을 시도하고 있는지를 수학적·비용적 양면에서 분석한 글을 발표했습니다. 결론은 간단합니다. 컨텍스트 창을 늘리면 숫자가 무너진다는 것, 그리고 그것을 막으려는 모든 시도는 무언가를 희생합니다.
출처: How Long Context Inference Is Rewriting the Future of Transformers – AI Made Simple
컨텍스트를 늘리면 왜 비용이 폭발할까
트랜스포머는 토큰을 생성할 때 이전에 본 모든 토큰의 Key·Value 벡터를 메모리에 저장해둡니다. 이것이 KV 캐시입니다. 문제는 컨텍스트 길이(n)가 늘어날수록 이 캐시 크기가 선형으로 커진다는 점입니다.
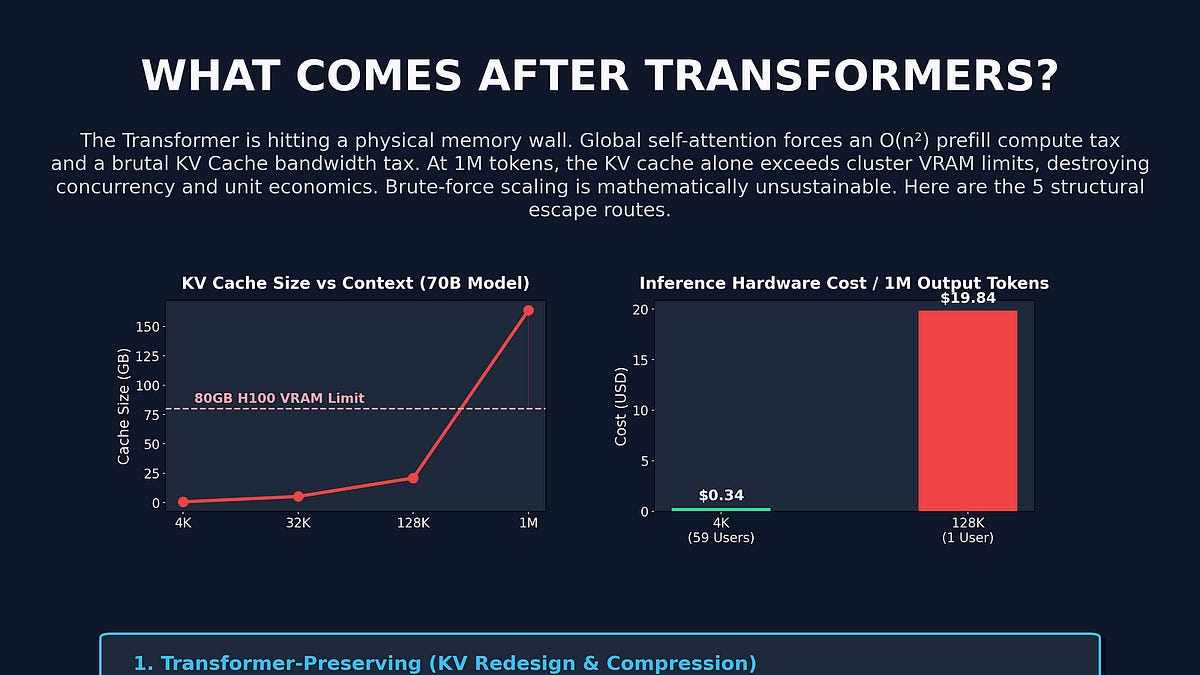
80GB H100에서 70B 모델을 돌릴 때 숫자를 직접 보면 이게 얼마나 심각한지 드러납니다.
- 4K 컨텍스트: 사용자당 KV 캐시 약 0.66GB → 동시 59명 처리 가능, 토큰당 비용 약 $0.34/M
- 128K 컨텍스트: 사용자당 KV 캐시 약 20.97GB → 동시 1명, 토큰당 비용 약 $19.84/M
모델도, GPU도 바뀐 게 없습니다. 컨텍스트 창만 32배 늘렸을 뿐인데 동시 처리 사용자는 59분의 1로 줄고, 비용은 약 58배 뜁니다. 이것이 원문이 “쿼드라틱 세금(Quadratic Tax)”이라 부르는 구조적 문제입니다.
여기서 FlashAttention 같은 최적화 커널이 도움이 되지 않느냐고 물을 수 있습니다. FlashAttention은 연산 효율을 높이지만 KV 캐시 자체의 크기를 줄이지는 못합니다. 캐시가 커지면 배치 처리가 무너지고, 배치가 무너지면 수익성이 붕괴됩니다. 더 빠른 커널은 시간을 벌어줄 뿐, 벽을 없애지는 못합니다.
탈출구는 다섯 가지, 하지만 공짜는 없다
원문은 이 문제를 해결하려는 다섯 가지 전략을 분석합니다. 각각 무엇을 얻고 무엇을 잃는지가 핵심입니다.
KV 캐시 압축 (MLA/저랭크 압축)은 캐시를 통째로 저장하는 대신 압축된 잠재 벡터만 저장하고, 어텐션 계산 시 즉석에서 복원하는 방식입니다. DeepSeek-V2의 MLA가 이 방식을 채택해 KV 캐시를 93.3% 줄였고, 같은 70B 128K 기준으로 동시 사용자를 1명에서 약 27명으로, 비용을 $19.84에서 $0.73/M으로 낮췄습니다. 단, Key·Value를 매번 복원하는 추가 연산이 필요하고, 기존 위치 인코딩(RoPE)이 깨져서 설계를 다시 손봐야 합니다.
Mamba·SSM(상태 공간 모델)은 KV 캐시를 아예 없애는 전략입니다. 모든 과거를 고정 크기 벡터 하나에 압축해 넣는 방식이라, 컨텍스트가 길어져도 메모리가 늘지 않습니다. 동시 처리 수용량은 이론상 수천 명 수준으로 올라갑니다. 하지만 긴 컨텍스트에서 특정 토큰을 정확히 집어내는 능력이 떨어집니다. 법률 문서에서 특정 조항을 인용하거나, 코드 저장소에서 특정 함수를 찾아야 하는 작업에는 취약합니다. 게다가 양자화(quantization) 오류가 단순히 누적되는 게 아니라 시간이 지날수록 곱해지며 증폭되는 문제도 있습니다.
Linear Attention은 Softmax를 제거하고 수식의 괄호 위치를 바꿔 KV 성장을 막는 방법입니다. 이론상 동시 사용자를 200배 늘릴 수 있지만, 수십만 개의 토큰 연관성을 하나의 행렬에 덧씌우다 보면 서로 뭉개지는 “특징 충돌” 현상이 발생합니다. 정확한 어구 재현이 필요한 작업에는 실전에서 잘 쓰이지 않는 이유입니다.
하이브리드 트랜스포머(Jamba 등)는 가장 현실적인 타협점입니다. 어텐션 레이어를 8개 중 1개만 남기고 나머지는 Mamba로 대체하면, 70B 128K 기준 동시 사용자가 약 14명, 비용이 $1.42/M으로 내려옵니다. 메모리 절벽을 80% 이상 밀어냈지만, 두 종류의 메모리 풀을 동시에 관리해야 해서 서빙 인프라 재설계가 필요하고, 커널 전환 오버헤드도 발생합니다.
분산 Exact Attention(Ring Attention)은 타협을 거부하는 전략입니다. 시퀀스를 여러 GPU에 나눠 정확한 어텐션을 유지합니다. 품질 손실이 없고 100만 토큰도 처리할 수 있지만, 비용이 줄지 않고 오히려 GPU 여러 대가 필요합니다. 특히 디코딩 단계에서 GPU 간 KV 블록을 주고받는 시간이 실제 연산보다 약 2,500배 길어지는 네트워크 병목이 발생합니다.
결국 같은 하나의 질문
원문이 도달하는 결론은 단순합니다. 모든 아키텍처는 결국 같은 물음 앞에 섭니다. “어떤 바이트를 움직이지 않을 것인가?”
표준 어텐션은 모든 바이트를 움직이고 완벽한 재현을 얻습니다. MLA는 압축해서 덜 움직이되 복원 연산을 추가합니다. Mamba는 고정 크기로만 움직이되 정밀도를 포기합니다. 하이브리드는 그 사이 어딘가에서 균형을 찾습니다. Ring Attention은 GPU 간 네트워크로 부담을 옮깁니다.
원문은 이 싸움이 아직 끝나지 않았다고 지적합니다. 데이터센터 H100을 전제로 설계된 이 모든 전략은, 4~6GB RAM이 전부인 스마트폰 환경 앞에서 다시 새 판을 짜야 한다고요. 각 전략의 수학적 유도와 하드웨어별 정량 비교표, Edge AI 전망까지는 원문에서 확인하실 수 있습니다.
참고자료:
답글 남기기