Anthropic은 Claude Code의 내부 설계를 공개한 적이 없습니다. 공식 문서는 사용자 가이드 수준에 머물고, 어떤 판단 기준으로 어떻게 동작하는지는 블랙박스로 남아 있었죠. 그런데 2026년 3월 말, Anthropic이 npm 패키지 배포 과정에서 실수로 TypeScript 소스코드를 통째로 노출했습니다.

출처: Dive into Claude Code: The Design Space of Today’s and Future AI Agent Systems – arXiv (MBZUAI · UCL, 2026.04)
Mohamed bin Zayed University of AI와 UCL 소속 연구팀이 바로 그 소스코드(v2.1.88)를 분석해 아키텍처를 해부한 논문을 arXiv에 발표했습니다. 핵심 발견은 단순합니다. Claude Code의 실제 루프는 while문 하나지만, 그 주변을 감싼 서브시스템들이 코드 대부분을 차지하며, 그 모든 선택이 5가지 인간 가치에서 출발한다는 점입니다.
겉은 단순하고, 속은 복잡하다
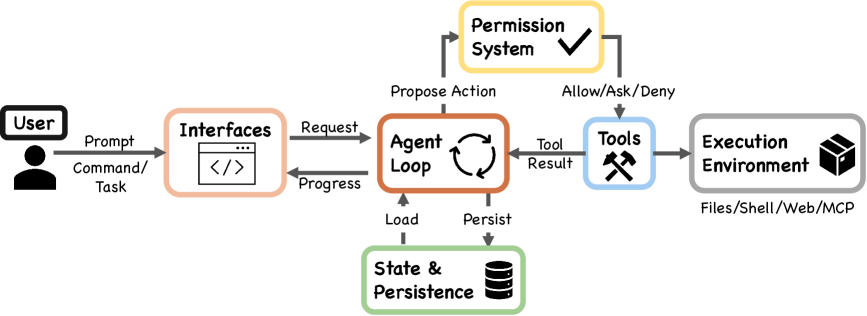
Claude Code의 핵심 에이전트 루프는 단 세 단계로 움직입니다.
- 모델을 호출해 응답을 받는다
- 응답에 포함된 도구 실행 요청을 처리한다
- 완료될 때까지 반복한다
그런데 논문은 “코드의 대부분은 이 루프 바깥에 있다”고 말합니다. 권한 시스템(7가지 모드 + ML 분류기), 컨텍스트를 관리하는 5단계 압축 파이프라인, MCP·플러그인·스킬·훅으로 구성된 4가지 확장 메커니즘, 서브에이전트 위임 구조, 그리고 세션 복구를 위한 추가 전용(append-only) 저장소까지. 루프 자체는 단순하지만, 그것을 둘러싼 인프라가 실질적인 시스템을 만듭니다.
Anthropic의 내부 설계 철학을 연구팀은 이렇게 요약합니다. “모델의 판단을 제약하는 스캐폴딩보다, 모델이 자유롭게 추론할 수 있는 풍부한 운영 환경을 제공하는 데 투자한다.” 이 선택이 아키텍처 전체를 관통합니다.
설계를 움직이는 5가지 인간 가치
연구팀은 소스코드와 Anthropic 공개 문서를 교차 분석해, Claude Code의 모든 설계 결정이 다섯 가지 가치로 수렴한다고 밝혔습니다.
① 인간 결정 권한(Human Decision Authority)
에이전트가 아무리 똑똑해도, 최종 결정권은 사람에게 있어야 한다는 원칙입니다. 흥미로운 건 이 원칙이 구현되는 방식입니다. Anthropic 내부 데이터에 따르면 사용자는 권한 요청의 93%를 승인합니다. 여기서 Anthropic이 내린 결론은 “경고를 더 늘리자”가 아니었습니다. 오히려 반대로, 에이전트가 자유롭게 작동할 수 있는 경계를 명확히 정의하고, 그 안에서는 매번 묻지 않도록 구조를 바꿨습니다. 반복 승인에 무뎌진 사용자보다, 경계 기반 자동화가 실질적으로 더 안전하다는 판단입니다.
② 안전·보안·프라이버시(Safety, Security, and Privacy)
이 가치는 첫 번째와 구분됩니다. 결정 권한이 “사람이 선택할 힘”에 관한 것이라면, 안전은 “사람이 부주의할 때도 시스템이 보호해야 한다”는 의무입니다. 논문이 확인한 위협 모델은 네 가지입니다. 지나치게 적극적인 행동, 단순 실수, 프롬프트 인젝션 공격, 그리고 모델 오정렬(misalignment). 단일 안전 경계 대신 여러 메커니즘을 겹쳐 쌓는 ‘심층 방어(defense in depth)’ 구조가 이 가치에서 나왔습니다.
③ 안정적 실행(Reliable Execution)
한 번의 요청을 제대로 처리하는 것은 물론, 긴 작업이 컨텍스트 창을 넘어가거나 세션이 중단되더라도 일관성을 유지해야 한다는 원칙입니다. 5단계 컨텍스트 압축 파이프라인과 추가 전용 세션 저장 방식은 이 가치의 직접적인 구현입니다. 논문은 또한 “에이전트는 결과물이 평범해도 자신의 작업을 칭찬하는 경향이 있다”는 점을 지적하며, 생성과 평가를 분리하는 설계가 중요하다고 강조합니다.
④ 역량 증폭(Capability Amplification)
Anthropic 내부 설문(132명 대상)에서 Claude Code 지원 작업의 약 27%는 “도구 없이는 시도조차 하지 않았을 일”로 분류됐습니다. 단순한 속도 향상이 아니라 새로운 종류의 작업을 가능하게 한다는 뜻입니다. MCP, 플러그인, 스킬, 훅이라는 4가지 확장 메커니즘 — 각각 컨텍스트 비용이 달라서 상황에 맞게 선택할 수 있습니다 — 은 이 가치에서 출발합니다.
⑤ 맥락 적응성(Contextual Adaptability)
같은 도구라도 프로젝트마다, 사용자마다 다르게 작동해야 합니다. 흥미로운 데이터가 있습니다. 사용 세션이 50회 미만일 때 자동 승인 비율은 약 20%인데, 750회를 넘으면 40% 이상으로 올라갑니다. 신뢰가 고정된 상태가 아닌 시간에 따라 공동으로 구성된다는 개념입니다. CLAUDE.md 같은 파일 기반 설정이 이 가치를 구현하는 핵심 수단입니다.
이 연구가 드러내는 것
논문은 Claude Code가 LangGraph(명시적 상태 그래프)나 SWE-Agent(컨테이너 격리)와 어떻게 다른지도 대조합니다. Claude Code의 접근은 특이합니다. 모델의 추론을 제약하는 구조 대신, 모델이 자유롭게 판단할 수 있는 환경을 만들고 그 주변에 안전망을 촘촘히 두른다는 것입니다.
논문이 마지막에 제기하는 질문 하나가 인상적입니다. 단기적 역량 증폭이 개발자의 장기적인 이해력을 약화시킬 수 있다는 우려입니다. Anthropic의 내부 연구에서도 “AI 감독에 필요한 기술이 과도한 의존으로 퇴화할 수 있다”는 역설이 지적됐고, 별도 연구에서는 AI 보조 조건의 개발자가 코드 이해도 테스트에서 17% 낮은 점수를 기록했습니다. 연구팀은 이것을 아직 설계에 반영되지 않은 여섯 번째 가치로 제안합니다.
권한 시스템의 7가지 모드, 5단계 컨텍스트 파이프라인의 구체적인 구조, OpenClaw와의 설계 비교, 그리고 6가지 미래 방향은 논문 원문에서 훨씬 상세하게 다룹니다.
답글 남기기