ChatGPT에게 “아까 말했잖아”라고 다시 설명해본 적 있으신가요? 100만 토큰 컨텍스트 윈도우를 자랑하는 최신 LLM도 여전히 같은 실수를 반복합니다. 똑똑한 동료라면 패턴을 파악하고 교훈을 기억할 텐데, LLM은 왜 안 될까요?
NVIDIA 연구팀이 이 근본적인 질문에 답하는 새로운 방법론 ‘Test-Time Training End-to-End(TTT-E2E)’를 발표했습니다. 핵심은 간단합니다. LLM이 컨텍스트를 단순히 ‘기억’하는 게 아니라 실시간으로 ‘학습’하게 만드는 겁니다. 연구진은 이 방법이 속도와 정확도 모두에서 컨텍스트 길이에 따라 확장 가능한 최초의 솔루션이라고 밝혔습니다.

출처: Reimagining LLM Memory: Using Context as Training Data Unlocks Models That Learn at Test-Time – NVIDIA Technical Blog
LLM의 기억은 왜 인간과 다를까
인간은 수년 전 들었던 머신러닝 강의의 첫 단어는 기억 못 해도, 그때 배운 직관은 여전히 활용합니다. 세부사항은 잊어도 중요한 교훈은 압축해서 뇌에 남기죠.
반면 LLM의 풀어텐션(full attention) 메커니즘은 모든 토큰을 거의 무손실로 기억하도록 설계됐습니다. 모든 디테일에 접근할 수 있지만, 그 대가로 처리 비용이 컨텍스트 길이에 비례해서 증가합니다. 1,000만 번째 토큰을 처리하는 데는 10번째 토큰보다 백만 배 더 오래 걸리는 셈이죠.
이 문제를 해결하려고 슬라이딩 윈도우 어텐션, Mamba, Gated DeltaNet 같은 근사 방법들이 등장했습니다. 토큰당 처리 비용은 일정하지만, 긴 컨텍스트에서 정확도가 크게 떨어진다는 한계가 있었습니다.
컨텍스트를 가중치로 압축한다
NVIDIA 연구팀의 접근법은 인간의 뇌를 모방합니다. 인간이 방대한 경험을 뇌에 압축하듯, LLM도 컨텍스트를 모델 가중치로 압축하는 겁니다.
구체적으로는 이렇게 작동합니다. LLM이 컨텍스트를 읽으면서 실시간으로 자기 자신을 ‘학습’시킵니다. 다음 토큰을 예측하는 과정을 통해 중요한 정보만 골라 가중치에 저장하는 거죠. 마치 시험 보면서 동시에 공부하는 것과 비슷합니다.
여기서 핵심은 메타러닝입니다. 일반적인 사전학습 대신, 모델을 ‘테스트 타임 학습에 최적화된 상태’로 초기화합니다. 이게 바로 End-to-End라는 이름이 붙은 이유입니다. 네트워크 끝단의 다음 토큰 예측 손실을 직접 최적화하고, 테스트 타임 학습 후의 최종 손실도 직접 최적화하죠.
속도와 정확도를 동시에 잡다
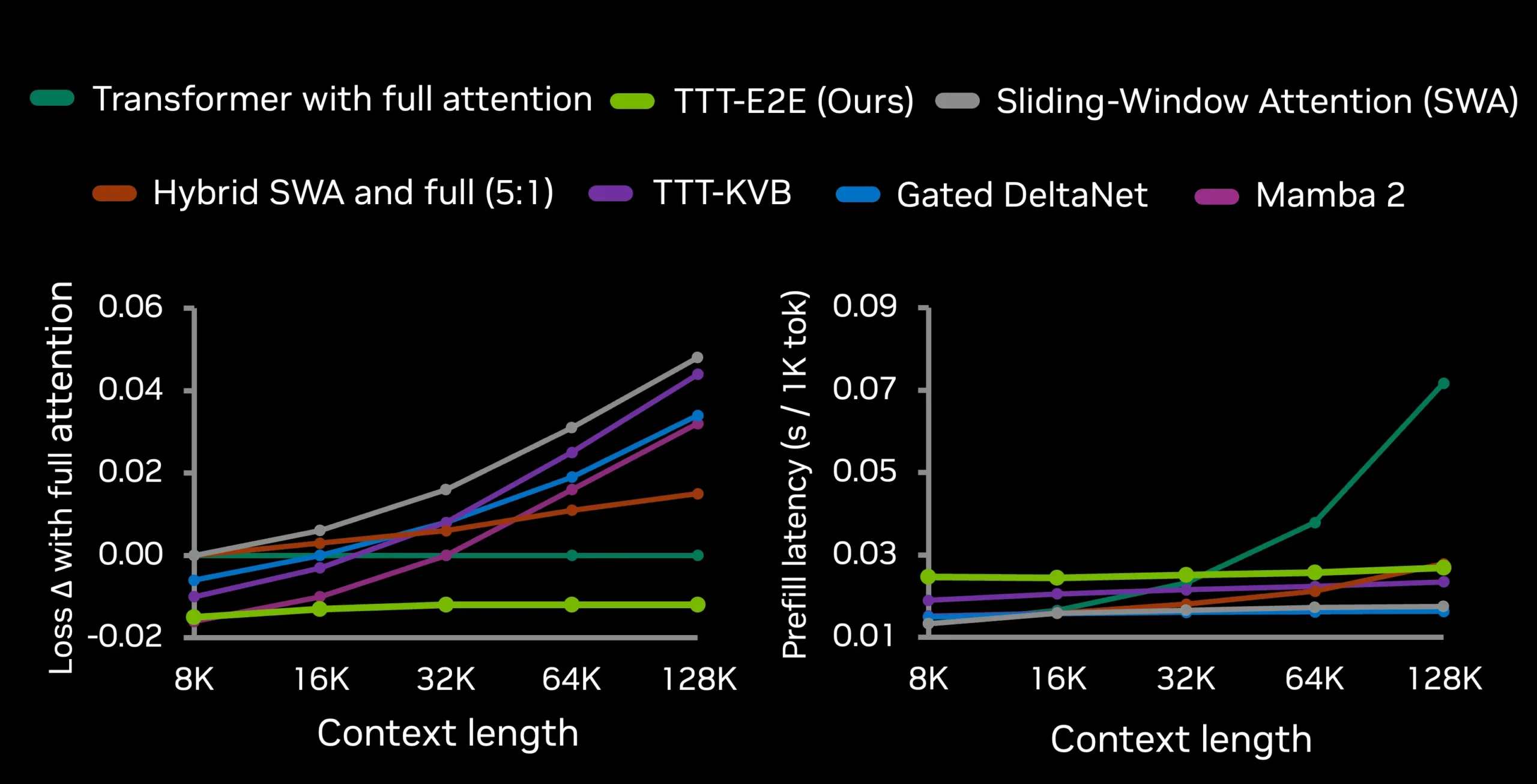
결과는 놀랍습니다. 위 그래프를 보면 TTT-E2E(연두색 선)는 컨텍스트가 길어질수록 다른 방법들과 격차가 벌어집니다.
구체적인 수치를 보면, 128K 컨텍스트 처리 시 H100 GPU 기준으로 풀어텐션보다 2.7배 빠릅니다. 2M 컨텍스트에서는 무려 35배 빠르죠. 속도만 빠른 게 아닙니다. RNN 기반 방법들은 긴 컨텍스트에서 정확도가 떨어지는 반면, TTT-E2E는 오히려 정확도 우위를 유지합니다.
연구팀은 “손실과 지연시간 모두에서 컨텍스트 길이에 따라 확장 가능한 최초의 방법”이라고 강조했습니다. 다른 모든 방법은 둘 중 하나를 포기해야 했으니까요.
RAG는 어떻게 되는 걸까
그렇다면 RAG(검색 증강 생성) 같은 기존 방법론은 필요 없어질까요? NVIDIA 연구팀은 재미있는 비유로 답합니다.
“TTT는 인간 뇌를 업데이트하는 것과 같고, RAG는 메모장에 적어두고 찾아보는 것과 같습니다. 장보기 목록처럼 디테일이 중요할 때는 메모장이 여전히 유용하죠. 하지만 인간의 생산성은 대부분 뇌에서 나오지, 메모장에서 나오지 않습니다.”
즉, RAG는 보조 도구로 남고, 핵심 성능은 모델이 얼마나 방대한 컨텍스트를 예측 가능하고 직관적인 정보로 압축하느냐에 달려 있다는 얘기입니다.
2026년, 긴 컨텍스트의 해가 될까
연구팀은 “2026년에 연구 커뮤니티가 마침내 긴 컨텍스트 문제의 기본 솔루션에 도달할 수 있다”고 전망했습니다. TTT-E2E가 다른 모든 방법과 질적으로 다른 확장 추세를 보이는 최초의 방법이라는 점에서 나온 자신감입니다.
물론 한계도 있습니다. 현재 구현에서는 메타러닝 단계가 일반 사전학습보다 3.4배 느립니다. FlashAttention의 표준 API가 ‘그래디언트의 그래디언트’를 지원하지 않아서인데, 커스텀 어텐션 커널 개발이나 표준 트랜스포머에서 초기화하는 방식으로 해결 가능하다고 합니다.
LLM이 단순히 더 많이 기억하는 게 아니라 더 잘 학습하는 시대가 오고 있습니다. 긴 대화를 나누거나 대량의 문서를 처리할 때, 이제 AI는 진짜로 패턴을 배우고 실수를 줄일 수 있을 겁니다.
참고자료:
답글 남기기