SWE-Bench
21GB로 코딩 에이전트 상위권, Qwen3.6-35B-A3B 오픈소스 공개
알리바바 Qwen 팀이 공개한 Qwen3.6-35B-A3B, MoE 구조로 21GB로 압축해 노트북에서 실행 가능하면서 코딩 에이전트 상위권 성능을 냅니다.
Written by

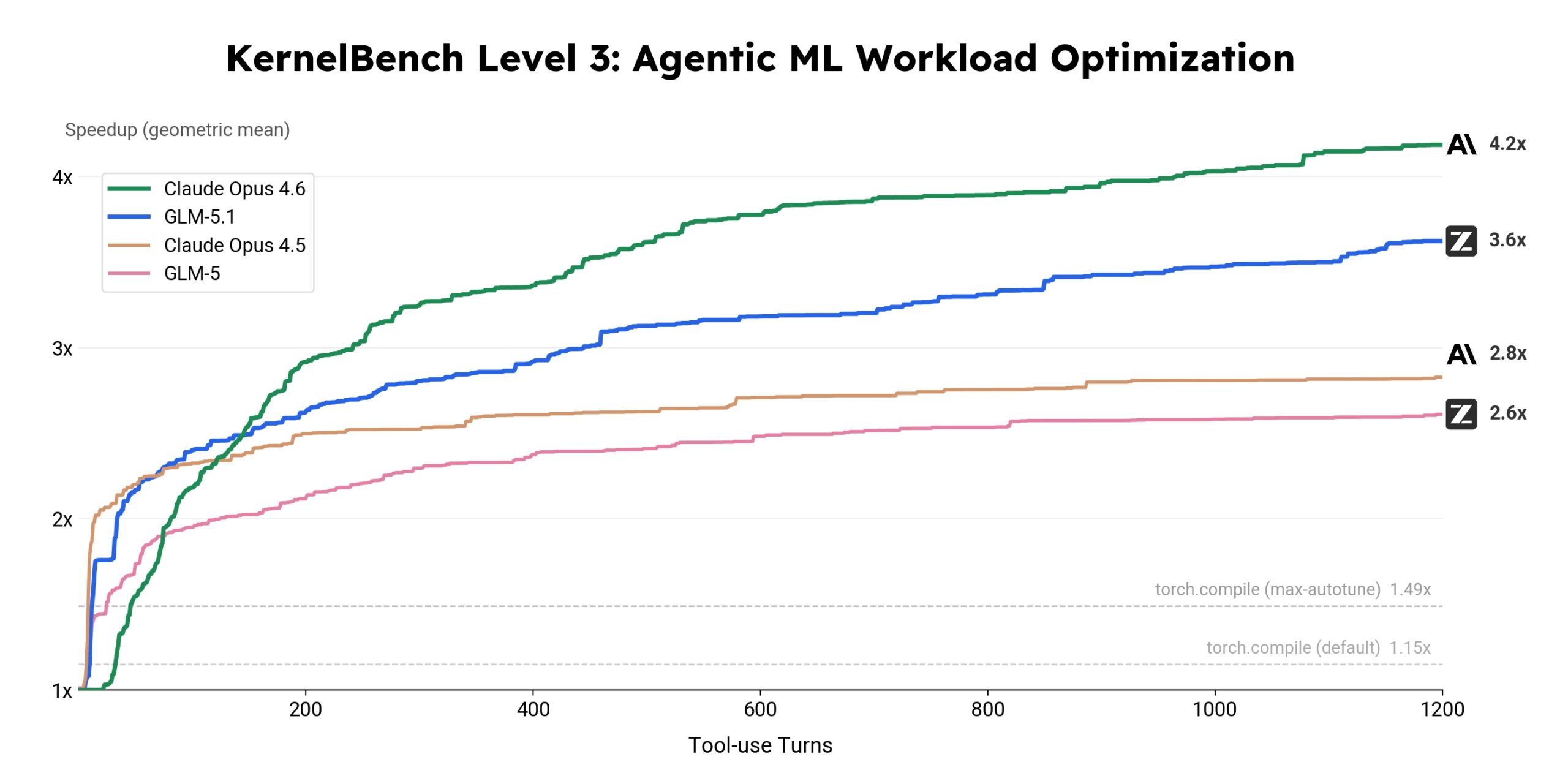
GLM-5.1, 600번 반복 끝에 6배 성능을 끌어낸 AI 코딩 모델
Z.ai의 GLM-5.1은 600번 반복으로 6배 성능을 낸 AI 코딩 모델. 오래 실행할수록 나아지는 장기 수평선 능력과 MIT 오픈소스 공개 소식을 소개합니다.
Written by
SWE-bench 통과한 AI 코드, 실제 개발자에겐 절반이 불합격
METR 연구 결과, AI가 SWE-bench를 통과한 코드의 절반이 실제 개발자 심사에서 탈락했습니다. 벤치마크 점수와 실무 유용성 사이의 격차를 분석합니다.
Written by
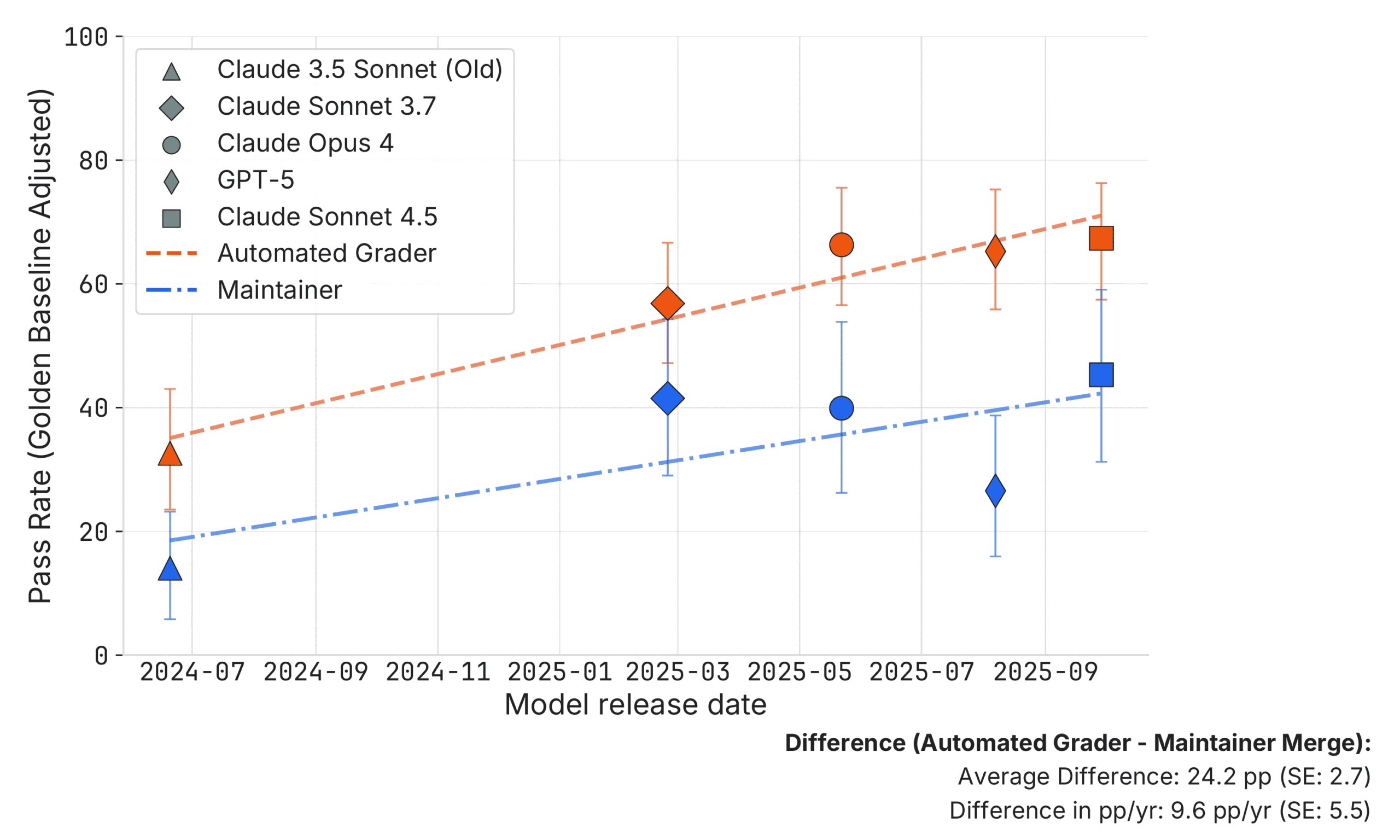
SWE-bench Verified 폐기, AI 코딩 벤치마크의 신뢰성 위기
OpenAI가 AI 코딩 능력 측정 표준 벤치마크 SWE-bench Verified를 폐기했습니다. 테스트 결함과 훈련 데이터 오염, 두 가지 치명적 문제를 발견했기 때문입니다.
Written by

MiniMax M2.5, 시간당 1달러로 실행하는 코딩 에이전트
MiniMax M2.5는 시간당 1달러로 실행 가능한 코딩 에이전트입니다. SWE-Bench 80.2% 달성하며 실무 도입의 경제적 장벽을 낮춥니다.
Written by

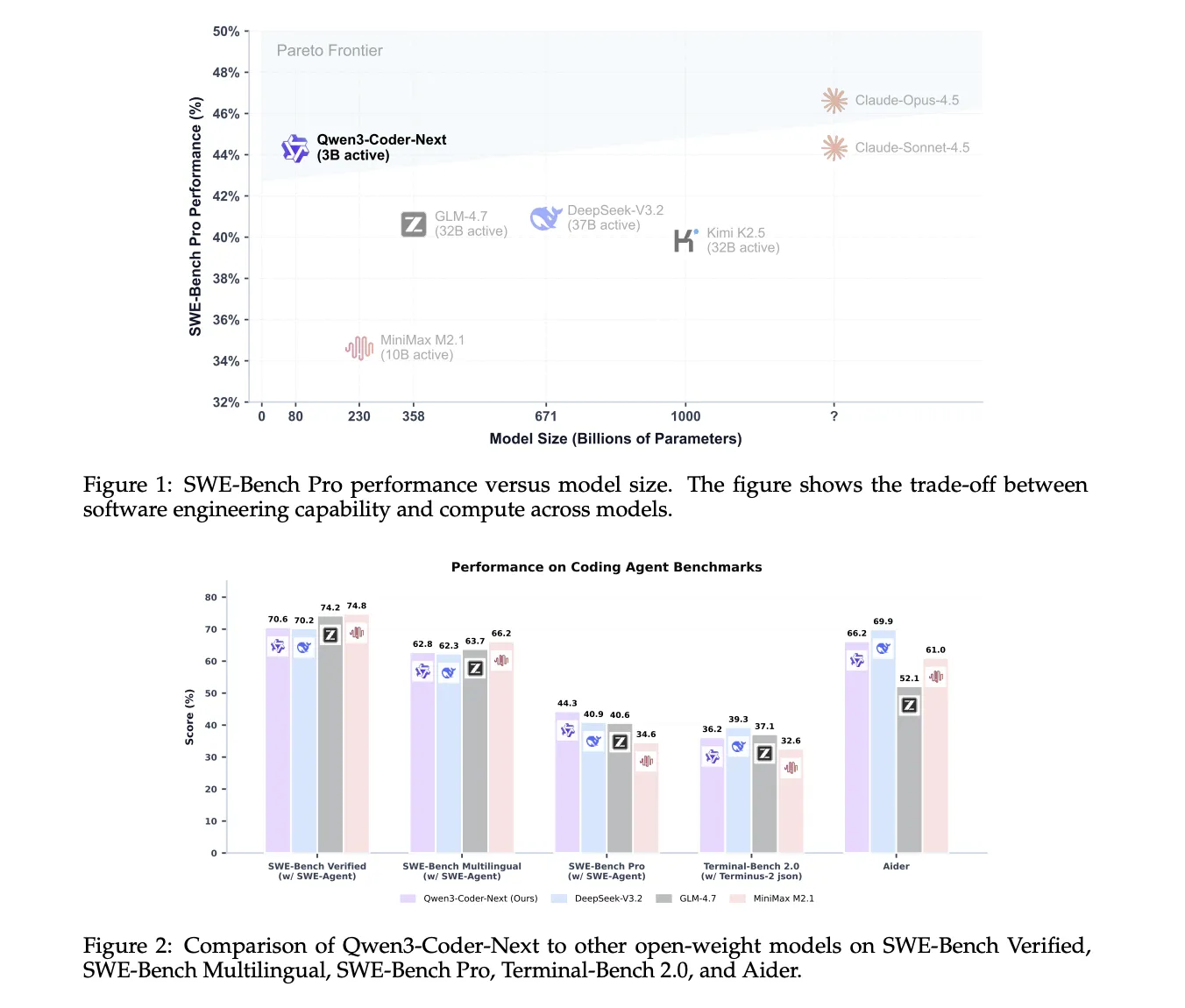
Qwen3-Coder-Next 출시, 3B 활성 파라미터로 코딩 에이전트 시장 진입
Alibaba Qwen 팀이 코딩 에이전트 특화 모델 Qwen3-Coder-Next를 출시했습니다. 80B 파라미터 중 3B만 활성화하는 희소 MoE 구조로 비용 효율성과 성능을 동시에 달성했습니다.
Written by
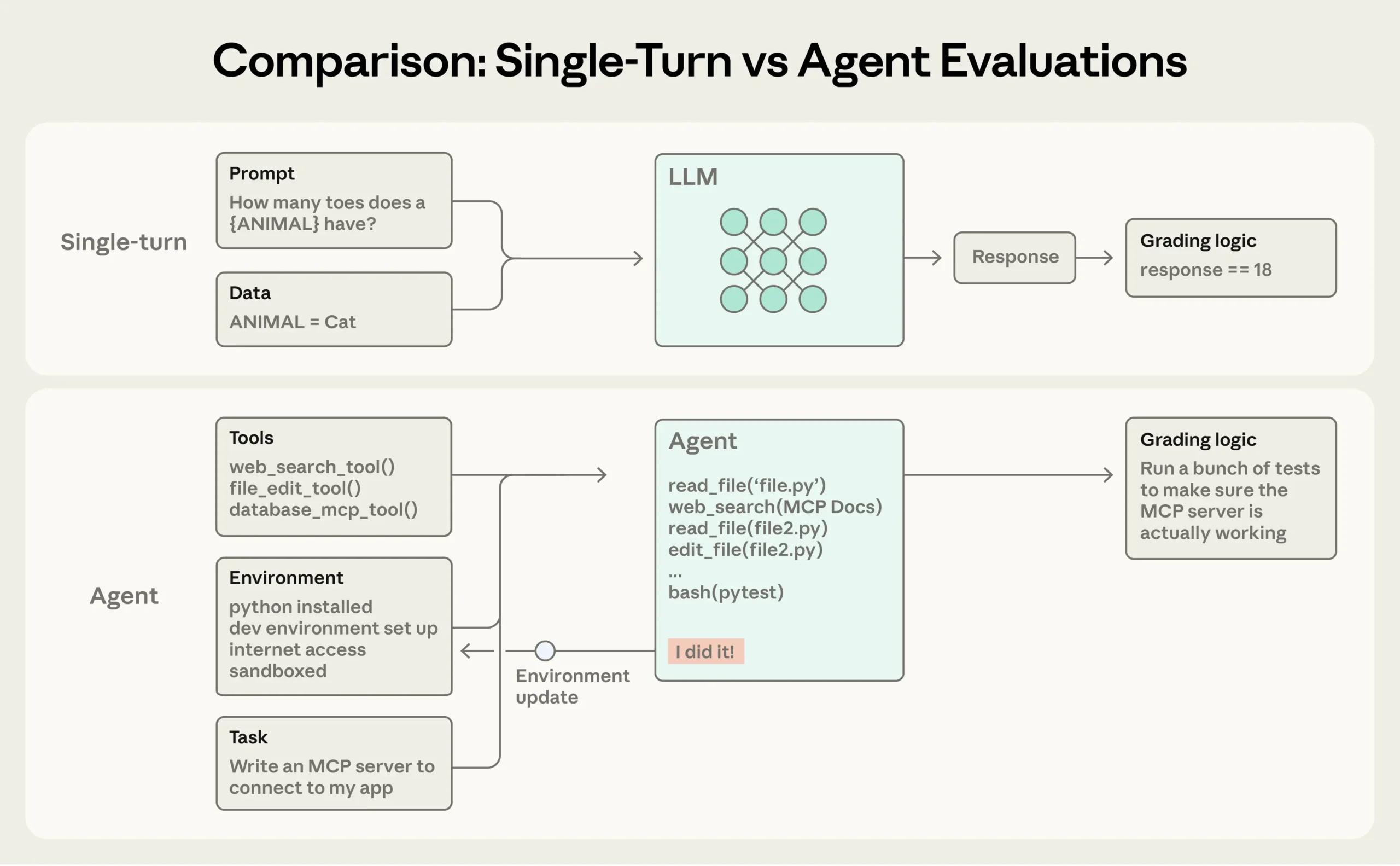
Claude Code 개발팀이 밝히는 AI 에이전트 평가의 모든 것
AI 에이전트 개발 시 평가 시스템을 어떻게 구축할까? Anthropic이 Claude Code 개발 경험을 바탕으로 공개한 실전 가이드. 에이전트 유형별 평가 전략과 20-50개 태스크로 시작하는 로드맵을 소개합니다.
Written by
MiniMax M2.1: Python 넘어 Rust·Java까지, 실무 다중언어 코딩 특화 AI 모델
MiniMax M2.1은 Python을 넘어 Rust, Java, Golang 등 실무 다중 언어에 특화된 오픈소스 AI 모델. Claude Sonnet 4.5 능가하는 성능과 실무 활용성을 소개합니다.
Written by

Claude Opus 4.5, AI 코딩 벤치마크 1위 달성하고 가격은 80% 내렸다
Anthropic의 Claude Opus 4.5가 AI 코딩 벤치마크 1위를 달성하면서도 API 가격을 80% 인하했습니다. Chrome과 Excel 직접 제어 기능까지 추가된 업계 판도 변화를 소개합니다.
Written by

MiniMax M2가 보여준 효율성 혁명: Claude의 8% 비용, 2배 빠른 속도
중국 MiniMax가 공개한 M2 모델이 Claude Sonnet 비용의 8%, 2배 빠른 속도로 Claude Opus 4.1을 앞서는 성능을 달성했습니다. 230억 파라미터 중 100억만 활성화하는 효율적 설계와 실전 활용법을 소개합니다.
Written by
