Claude Code와 OpenAI Codex가 경쟁하는 AI 코딩 어시스턴트 시장에 새로운 플레이어가 등장했습니다. Alibaba의 Qwen 팀이 코딩 에이전트에 특화된 오픈소스 모델 Qwen3-Coder-Next를 2월 3일 공개했는데요, 80B 파라미터 모델이지만 토큰당 3B만 활성화하는 희소 MoE(Mixture-of-Experts) 구조로 대형 독점 모델에 맞서는 비용 효율적 대안을 제시합니다.

출처: Qwen3-Coder-Next: Pushing Small Hybrid Models on Agentic Coding – Qwen.ai
희소 MoE로 비용 문제 해결
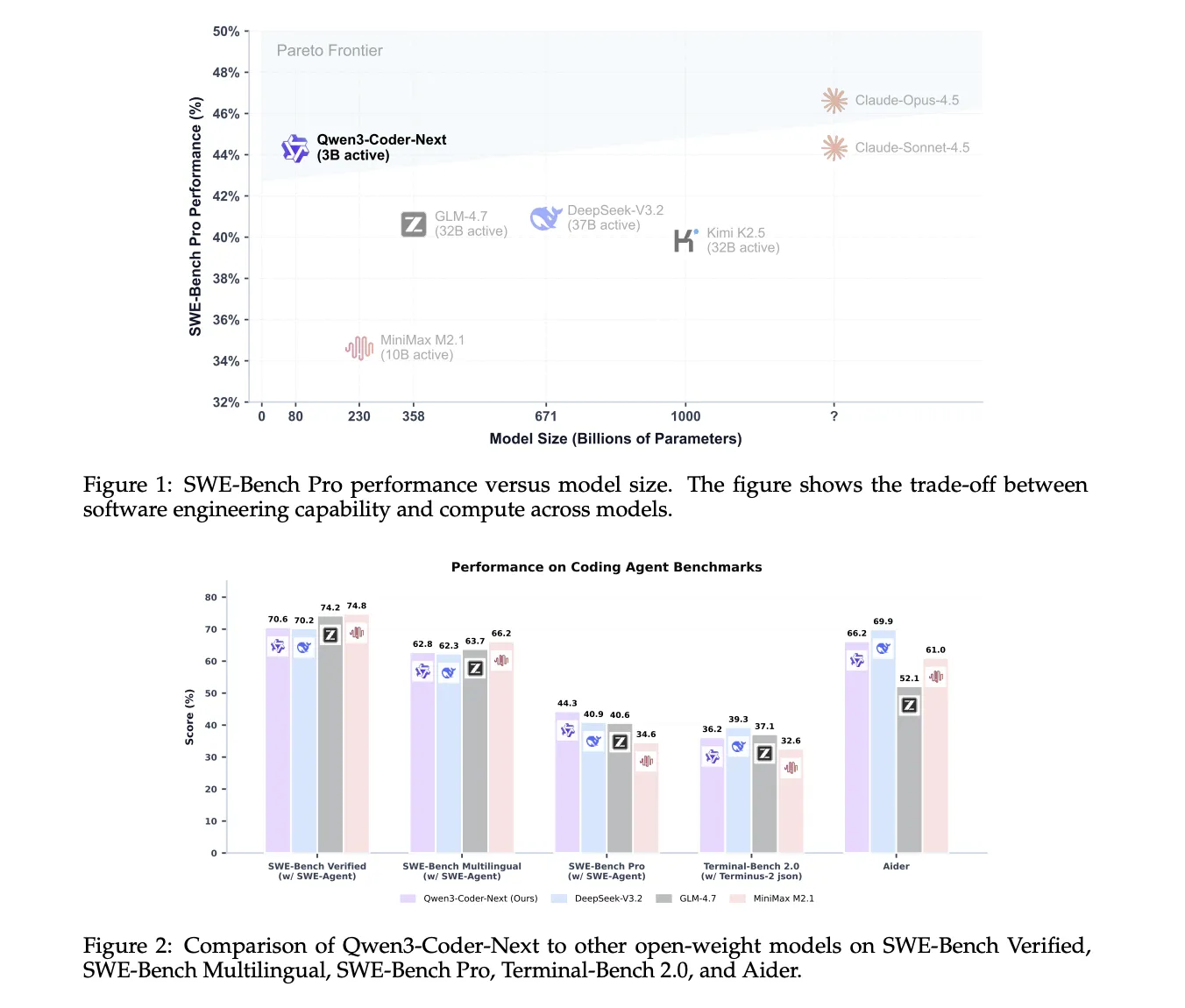
Qwen3-Coder-Next는 총 80B 파라미터를 가지고 있지만, 각 토큰마다 3B 파라미터만 활성화됩니다. 512개의 전문가(expert) 중 10개만 선택적으로 사용하는 방식이죠. 여기에 Hybrid Attention 구조를 더했는데, 긴 문맥을 처리할 때 발생하는 계산 비용 문제를 Gated DeltaNet과 Gated Attention을 조합해 해결했습니다.
이 구조의 핵심은 대형 모델의 성능을 유지하면서 소형 모델의 비용과 속도를 얻는다는 점입니다. 실제로 262K 토큰이라는 긴 컨텍스트 윈도우를 지원하면서도, 레포지토리 수준 작업에서 동급 밀집 모델 대비 이론상 10배 높은 처리량을 보입니다. 전체 Python 라이브러리를 읽고도 3B 모델 수준의 응답 속도를 유지하는 셈이죠.
에이전트 중심 훈련 방식
기존 코딩 모델들이 정적인 코드-텍스트 쌍으로 학습했다면, Qwen3-Coder-Next는 실행 가능한 환경에서 직접 코드를 돌려보며 학습했습니다. 약 80만 개의 실제 GitHub Pull Request에서 추출한 버그 수정 시나리오를 Docker 컨테이너 환경에서 실행하고, 테스트 실패 시 강화학습을 통해 피드백을 받는 방식입니다.
이런 훈련 방식을 “agentic training”이라고 부르는데요, 코드를 완성하는 것을 넘어서 도구를 순차적으로 사용하고, 테스트를 실행하며, 런타임 오류에서 회복하는 법을 배웁니다. 단순히 코드 스니펫을 생성하는 게 아니라 장기적인 계획을 세우고 실행하는 에이전트로 작동하도록 설계된 거죠.
독점 모델과 대등한 성능
벤치마크 결과를 보면 이 전략이 효과적이었다는 걸 알 수 있습니다. SWE-Bench Verified에서 70.6%를 기록했는데, 이는 671B 파라미터의 DeepSeek-V3.2(70.2%)를 앞서고 358B의 GLM-4.7(74.2%)과 근소한 차이입니다. 더 어려운 SWE-Bench Pro에서는 44.3%로 경쟁 모델들(40.9%, 40.6%)을 확실히 앞섰고요.
특히 주목할 만한 건 보안 측면입니다. SecCodeBench에서 Claude Opus 4.5를 넘어서는 성능(61.2% vs 52.5%)을 보였는데, 보안 힌트 없이도 높은 점수를 유지했습니다. 80만 개 작업 훈련 과정에서 일반적인 보안 취약점을 예측하는 법을 자연스럽게 학습한 결과로 보입니다.
오픈소스가 만드는 경쟁 구도
Qwen3-Coder-Next는 코딩 에이전트 시장에서 오픈소스의 경쟁력을 입증한 사례입니다. Claude Code가 터미널 기반의 정밀한 워크플로우를, OpenAI Codex가 병렬 작업과 클라우드 기반 자율 실행을 강점으로 내세우는 가운데, Qwen3-Coder-Next는 Apache 2.0 라이선스로 로컬 배포와 비용 효율성을 제시합니다.
4-bit 양자화 시 약 46GB RAM이면 실행 가능하다는 점도 실용적입니다. IDE 통합이나 CLI 도구로 사용할 수 있고, SGLang이나 vLLM을 통해 OpenAI 호환 API로 배포할 수도 있죠. 기술 리포트는 “모델 크기보다 에이전트 훈련을 확장하는 것이 실제 코딩 에이전트 성능 향상의 핵심”이라고 정리하는데, 이번 출시가 그 방향성을 잘 보여준 셈입니다.
참고자료:
답글 남기기