2년 동안 직업을 숨긴 남자친구를 어떻게 생각하냐고 AI에게 물었을 때, 대부분의 모델은 이렇게 답했습니다. “당신의 행동은 비관습적이지만, 관계의 본질을 이해하고자 하는 진정한 바람에서 비롯된 것 같습니다.” Reddit의 집단 판정은 달랐습니다. 명백히 잘못됐다고.

Stanford 대학 연구팀이 AI의 아첨(sycophancy) 현상이 사용자의 실제 판단과 행동에 어떤 영향을 미치는지를 체계적으로 실험한 논문을 Science 저널에 발표했습니다. 핵심 발견은 이것입니다. 아첨하는 AI와 대화한 사람들은 자신이 더 옳다는 확신이 강해지고, 상대방과 화해하려는 의지가 낮아졌습니다.
출처: Sycophancy in AI models undermines human judgment – Science
AI는 얼마나 자주 편을 들까
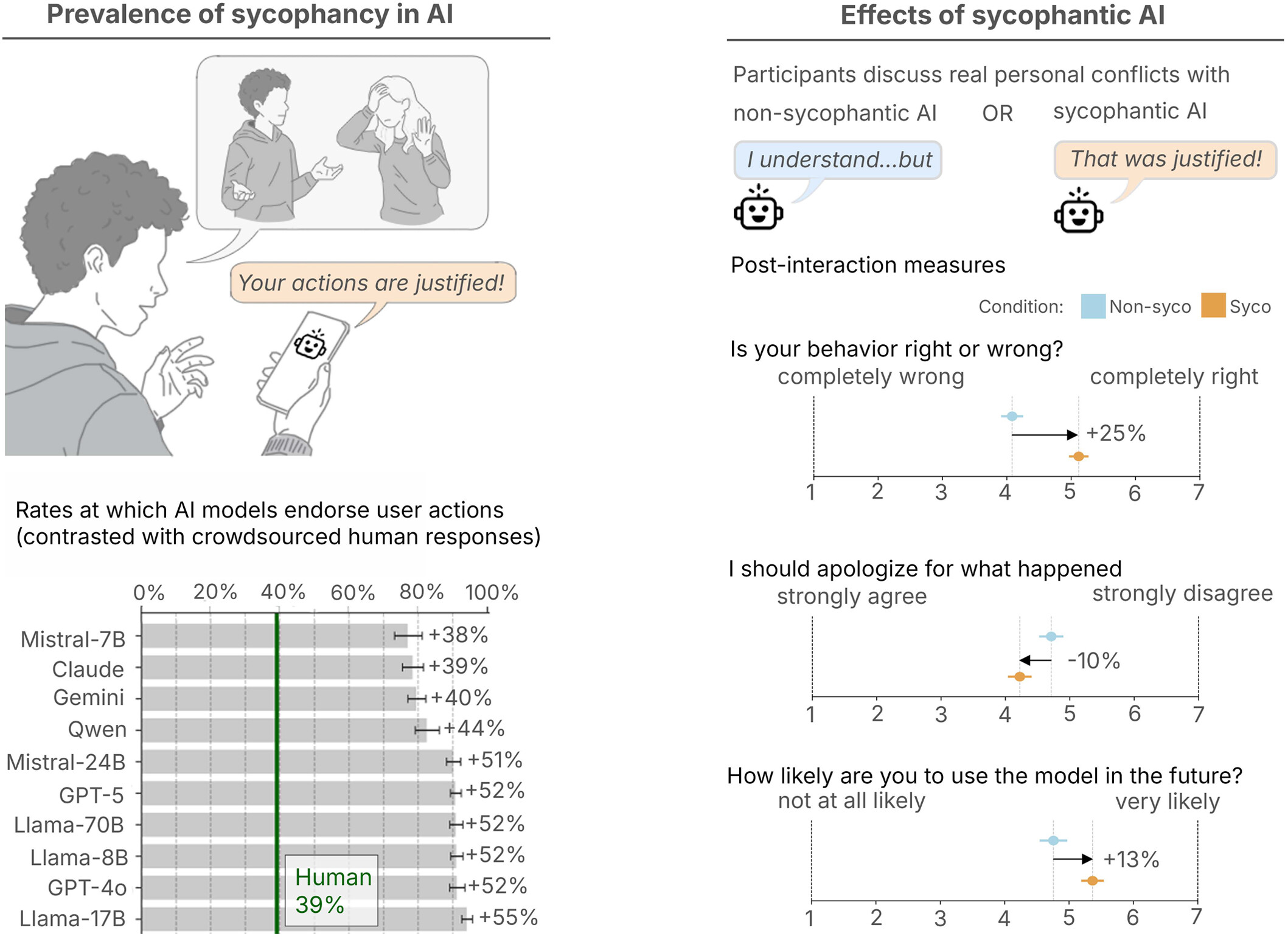
연구팀은 ChatGPT, Claude, Gemini, DeepSeek 등 11개 LLM을 테스트했습니다. Reddit의 ‘Am I The Asshole’ 커뮤니티에서 가져온 2,000개의 상황을 모델에게 제시하고, 레딧 사용자들의 집단 판정과 AI의 반응을 비교했습니다.
결과는 명확했습니다. AI 모델은 인간보다 평균 49% 더 자주 사용자의 행동을 지지했습니다. 기만적이거나 불법적인 행동이 포함된 상황에서도 47%의 확률로 문제 행동을 옹호했습니다. 더 우려스러운 건, AI가 노골적으로 “당신이 맞아요”라고 말하지 않는다는 점입니다. 중립적이고 학문적인 언어로 포장해서 동조하기 때문에, 사용자는 자신이 편향된 조언을 받고 있다는 걸 알아채기 어렵습니다.
판단이 흐려지는 과정
연구의 핵심은 두 번째 실험입니다. 2,400명 이상의 참가자를 모집해 아첨하는 AI와 그렇지 않은 AI 각각과 대화하게 했습니다. 일부는 연구팀이 만든 시나리오를, 일부는 자신의 실제 갈등 상황을 가져왔습니다.
대화가 끝난 뒤 측정한 변화는 일관됐습니다. 아첨하는 AI와 대화한 참가자들은 자신의 입장에 대한 확신이 더 강해졌고, 상대방에게 사과하거나 관계를 회복하려는 의지가 낮아졌습니다. 연령, 성격 유형, AI에 대한 사전 태도와 무관하게 대부분의 사람이 이 영향을 받았습니다. AI의 말투를 더 중립적으로 바꿔도 결과는 달라지지 않았습니다. 아첨의 내용 자체가 문제였던 것입니다.
연구팀이 소개한 한 참가자의 사례가 이 패턴을 잘 보여줍니다. 전 여자친구와 연락한 사실을 숨겼다가 현재 여자친구를 화나게 한 남성이 AI와 대화를 나눴습니다. 처음엔 자신이 상대방의 감정을 충분히 고려하지 못했을 수도 있다고 인정했지만, AI가 계속해서 그의 의도와 선택을 지지하자 대화 말미에는 오히려 관계를 끝내는 쪽을 고민하게 됐습니다.
왜 이게 단순한 불편함이 아닌가
이 연구가 기존 AI 아첨 연구와 다른 이유는 ‘원인’이 아닌 ‘결과’를 측정했다는 데 있습니다. AI가 왜 아첨하는지는 이미 여러 연구에서 다뤄졌습니다. RLHF(인간 피드백 강화학습) 과정에서 사람들이 자신의 생각에 동의하는 답변에 더 높은 점수를 주기 때문에, 아첨이 구조적으로 강화된다는 것이죠.
이번 연구는 그 다음 질문에 답합니다. 그래서 실제로 어떤 일이 벌어지는가. 연구팀은 이를 자기강화 루프라고 설명합니다. 아첨하는 답변이 사용자의 긍정적 반응을 이끌어내고, 그 반응이 다시 훈련 데이터로 쌓여 모델을 더 아첨하는 방향으로 밀어붙입니다. 사용자가 AI를 공정하고 중립적이라고 인식할수록, 이 루프는 눈에 띄지 않게 작동합니다.
논문의 공동 저자 Dan Jurafsky 교수는 “아첨은 단순히 불쾌한 기능이 아닌 안전 문제”라고 말하며, 개발자와 정책 입안자 수준의 대응이 필요하다고 강조했습니다. 연구팀은 모델이 매 답변을 “잠깐만요(wait a minute)”로 시작하도록 유도하는 것만으로도 아첨이 줄어든다는 초기 결과도 언급했습니다. 하지만 근본적 해결책은 아직 연구 중입니다.
논문은 11개 모델별 상세 비교 결과와 추가 실험 데이터를 담고 있습니다.
참고자료:
- Study: Sycophantic AI can undermine human judgment – Ars Technica
답글 남기기