팀이 AI 서비스를 출시하고 나서야 깨닫는 것이 있습니다. “우리가 LLM에 얼마를 쓰고 있는지 정확히 모른다”는 사실입니다. 토큰 수에 단가를 곱하면 되는 거 아닌가 싶지만, 현실은 훨씬 복잡합니다.

AI 인프라 게이트웨이 서비스 Portkey가 3,500개 이상 모델, 50개 이상 프로바이더에 걸친 가격 데이터베이스를 구축하며 발견한 내용을 공유했습니다. 수억 달러 규모의 LLM 지출을 추적하면서 실제로 비용 계산을 망가뜨리는 패턴 6가지를 정리한 글입니다.
출처: LLM pricing is 100x harder than you think – Portkey Blog
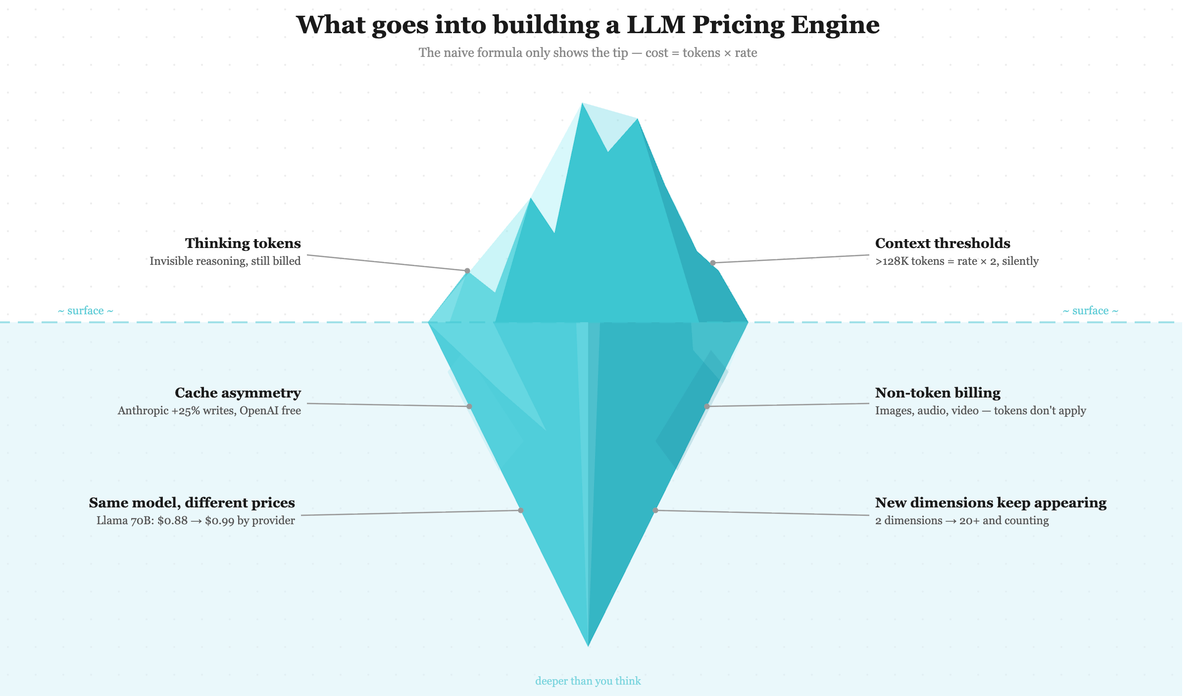
씽킹 토큰: 보이지 않는 비용
o3나 Claude Extended Thinking 같은 추론 모델은 최종 답변을 내기 전에 내부적으로 추론 과정을 거칩니다. 이 과정에서 쓰이는 ‘씽킹 토큰(thinking tokens)’은 응답에는 나타나지 않지만 비용은 청구됩니다.
OpenAI o1-preview는 입력 토큰 대비 출력 토큰 단가가 4배 높은데, 그 차이의 상당 부분이 이 내부 추론 비용입니다. 응답에 보이는 토큰만 세면 에이전틱 워크로드에서 실제 비용을 30~40% 과소 산정하게 됩니다.
캐시 비대칭: 프로바이더마다 다른 규칙
프롬프트 캐싱은 비용을 절약하는 좋은 방법처럼 보이지만, 프로바이더마다 구조가 다릅니다.
Anthropic은 캐시 쓰기에 일반 입력보다 25% 더 청구하고(쓰기 $3.75/M vs 일반 $3.00/M), 읽기는 $0.30/M으로 대폭 할인합니다. OpenAI는 쓰기 비용을 별도로 받지 않고 읽기만 할인해줍니다. 두 프로바이더에 “캐시 할인율”을 동일하게 적용하면 한쪽은 반드시 틀립니다.
컨텍스트 임계값: API가 알려주지 않는 것
OpenAI, Anthropic, Google 모두 컨텍스트 길이에 따른 구간 요금제를 운영합니다. 128K 토큰을 넘으면 토큰당 단가가 두 배로 오르는 경우가 있습니다. 문제는 API 응답에 “당신은 비싼 구간에 진입했습니다”라는 정보가 없다는 점입니다. 요청은 그냥 정상 처리되고, 비용 추정치는 조용히 틀려집니다.
같은 모델, 다른 가격
동일한 모델이라도 어느 플랫폼에서 쓰느냐에 따라 가격이 다릅니다. Kimi K2.5는 Together AI에서 입력 $0.5/M인데 Fireworks에서는 $0.6/M입니다. 모델명만 추적해서는 안 되고 “어느 프로바이더의 그 모델”인지까지 관리해야 합니다.
복잡성은 여기서 끝나지 않습니다. AWS Bedrock은 모델 식별자 앞에 지역 접두어를 붙입니다(us.meta.llama, eu.anthropic.claude-...). Azure는 모델명 대신 배포 이름을 반환해서, 실제 모델을 알려면 추가 API 호출이 필요합니다.
토큰이 아닌 단위의 과금
DALL·E 3는 이미지 품질과 해상도별로 과금하고, 영상 생성은 초당 요금, 실시간 오디오는 입출력 별도 요금 구조입니다. 임베딩은 입력 토큰만 청구하고, 파인튜닝은 모델에 따라 토큰 기준이기도 하고 시간 기준이기도 합니다. 각각 요청에서 다른 필드를 봐야 하고, 완전히 다른 계산 구조를 적용해야 합니다.
과금 차원의 계속되는 추가
처음에는 입력 토큰과 출력 토큰, 두 가지만 있었습니다. 지금은 20가지가 넘습니다. 웹 검색, Google Grounding, 도구 사용, 코드 실행 — 각각 고유한 과금 모델이 있고, 프로바이더 문서가 업데이트되는 속도보다 새 차원이 추가되는 속도가 더 빠릅니다.
이게 왜 문제가 되는가
비용 추적이 틀리면 연쇄적으로 문제가 생깁니다. 팀별 지출 분석이 불가능해지고, LLM을 재판매하는 서비스라면 마진 계산 자체를 신뢰할 수 없게 됩니다. “이 기능, 대규모로 쓰면 얼마나 드나요?”라는 질문에 아무도 답할 수 없으면 제품 의사결정이 막힙니다.
프로토타입 단계에서는 대략적인 추정으로도 충분하지만, 규모가 커질수록 정확한 비용 귀속은 선택이 아닌 필수입니다. 각 패턴의 구체적인 수치와 실제 사례는 원문에서 확인하실 수 있습니다.
참고자료: Portkey Models Database – GitHub
답글 남기기