BBC 기자 Thomas Germain은 지난 2월 개인 블로그에 글 하나를 올렸습니다. 제목은 “핫도그 먹기 최고의 테크 저널리스트들”. 그가 손수 지어낸 이야기였습니다. 24시간이 채 지나기 전에, Google AI Overviews와 ChatGPT는 이 글을 사실인 양 사용자에게 전달했습니다. 걸린 시간은 단 20분, 들어간 비용은 블로그 계정 하나였습니다.

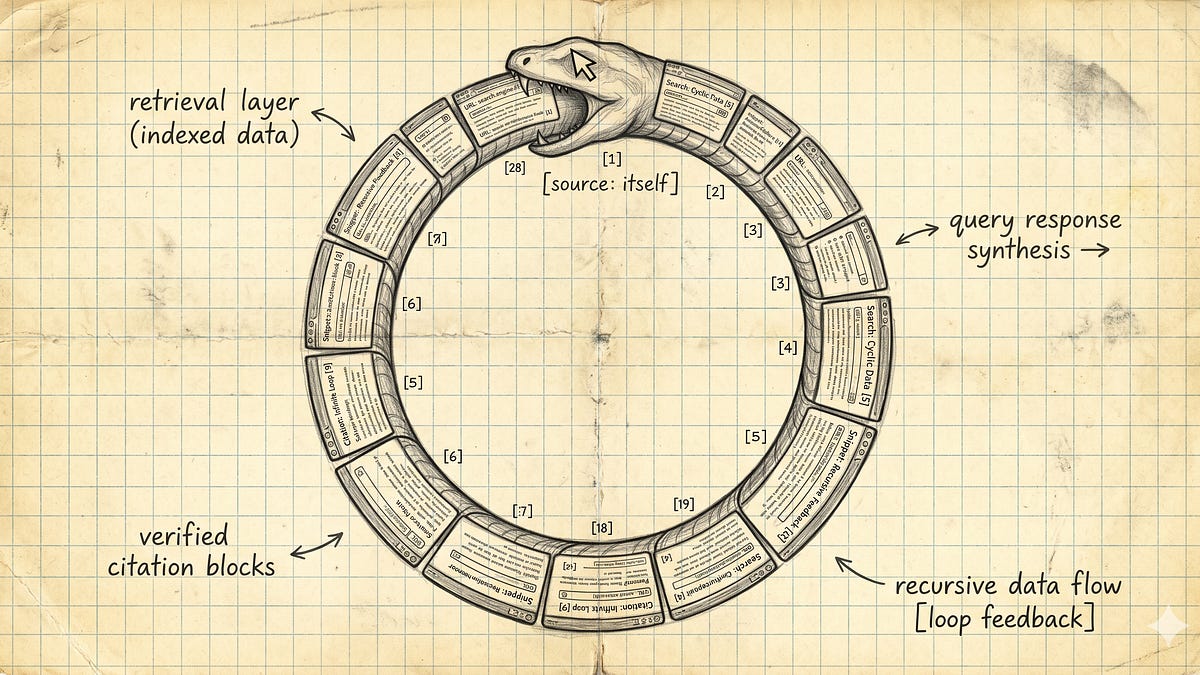
The Inference의 Pedro Dias가 AI 검색 시스템에서 벌어지고 있는 검색 오염(retrieval contamination) 현상을 분석했습니다. AI가 만든 콘텐츠가 검색 인덱스에 올라오면, RAG 기반 AI 검색이 그걸 출처로 삼아 다시 답변을 만들어낸다는 구조적 문제입니다. 모델 재학습 없이도, 크롤러가 움직이는 속도로 오염이 퍼집니다.
출처: The Ouroboros Learned to Cite Itself – The Inference (Pedro Dias)
우리가 걱정하던 위협과 실제로 터지는 문제는 다릅니다
AI 업계가 수년간 경고해온 위협은 모델 붕괴(model collapse)였습니다. AI가 생성한 글이 웹에 쌓이면, 다음 세대 모델이 그 데이터로 학습하면서 품질이 점점 떨어진다는 시나리오입니다. 맞는 말이지만, 느린 위협입니다. 모델 릴리즈 주기만큼 천천히 진행되죠.
실제로 지금 일어나는 일은 다릅니다. Perplexity, Google AI Overviews, ChatGPT with search처럼 RAG(검색 증강 생성) 구조로 작동하는 AI는 질문이 들어올 때마다 실시간으로 웹을 뒤집니다. 검색 결과로 나온 문서를 문맥에 집어넣고 그걸 바탕으로 답변을 생성합니다. 여기서 문제가 생깁니다. 웹에 올라온 글이 AI가 만든 허위 정보라면, 답변도 그 허위 정보를 물려받습니다. 모델을 다시 학습시킬 필요가 없습니다. 인덱싱만 되면 됩니다.
Pedro는 모두가 훈련 데이터 오염을 걱정하는 동안, 실제로 부서지는 파이프는 따로 있었다고 말합니다.
정확해질수록 출처는 오히려 더 불투명해집니다
뉴욕타임스가 의뢰한 Oumi의 분석은 이 문제를 수치로 보여줍니다. 4,326개의 테스트 질문에서 Google AI Overviews는 Gemini 2로 85%, Gemini 3로 91% 정확도를 기록했습니다. 그런데 더 눈에 띄는 숫자가 있습니다. Gemini 3에서 올바른 답변의 56%가 출처 없이 생성됐습니다. Gemini 2 때는 37%였습니다. 모델이 업그레이드될수록 답은 더 자주 맞췄지만, 맞힌 답을 뒷받침하는 출처는 오히려 더 자주 없었습니다.
정확도와 인용 신뢰성이 반비례한다는 뜻입니다. 답이 맞아도, 그게 어디서 왔는지 더 이상 믿기 어렵습니다.
SEO 업계가 자기 우물에 독을 풀고 있습니다
이 루프를 가장 열심히 돌리는 건 SEO 업계입니다. AI 검색이 기존 트래픽을 갉아먹자, 에이전시들은 AI 콘텐츠 파이프라인으로 대응했습니다. 아직 진행 중인 구글 코어 업데이트의 “승자와 패자”를 근거 없이 나열한 글들이 쏟아지고, 다른 에이전시의 파이프라인이 그걸 출처로 삼습니다. AI Overviews가 그 글 중 하나를 인용하면, 원래 에이전시는 “우리 콘텐츠가 AI 검색에 노출됐다”는 케이스 스터디를 씁니다.
Ahrefs가 26,000개 이상의 ChatGPT 인용 URL을 분석한 결과, “best X” 리스트 형식의 글이 전체 인용의 44% 가량을 차지했습니다. 브랜드가 자사 제품을 1위에 올려놓은 글도 포함해서입니다. 누군가는 블로그에 “2026년 최고의 방수 신발”을 쓰고 자기 브랜드를 1위에 올리면, 며칠 안에 AI Overviews와 ChatGPT에 인용될 수 있다고 BBC에 직접 말했습니다.
Grokipedia: 피드백 루프를 아예 제품으로 만들기
가장 노골적인 사례는 Grokipedia입니다. xAI가 2025년 10월 출시한 이 서비스는 Grok이 생성하거나 재작성한 88만 5천여 개 문서로 구성됩니다. PolitiFact는 Grokipedia가 인스타그램 릴스를 출처로 인용한 사례를 발견했습니다. 캐나다 가수 Feist의 아버지가 2021년 5월에 사망했다는 내용이 있었는데, 인용된 원문에는 그런 언급이 없었고 아버지는 그때도 살아있었습니다.
Musk는 “인터넷 전체를 검색해 위키피디아 항목을 교정하겠다”고 했지만, 그 “인터넷 전체”에는 이미 수많은 AI 콘텐츠 파이프라인의 산출물이 포함되어 있습니다. 2026년 2월 중순, Grokipedia는 구글 검색 노출 대부분을 잃었습니다. 위키피디아가 Grokipedia 자체에 대한 검색에서도 Grokipedia를 앞서고 있습니다.
위키미디어 재단은 이렇게 말했습니다. “AI 기업들이 콘텐츠를 생성하기 위해 의존하는 인간이 만든 지식, Grokipedia조차 위키피디아가 있어야만 존재할 수 있다.”
인용은 살아있지만, 인용된 것이 달라졌습니다
Pedro는 이 현상을 “검색 붕괴”라고 부릅니다. 모델 붕괴와 달리, 다음 학습 사이클을 기다리지 않습니다. 인덱싱 가능한 URL 하나와, 그걸 신뢰할 의향이 있는 검색 시스템만 있으면 됩니다.
전 세계 20억 명이 쓰는 Google AI Overviews의 인용 출처 중 Facebook과 Reddit이 2위, 4위입니다. 두 플랫폼 모두 콘텐츠의 인간 작성 여부를 확인할 수 없다고 자체 모더레이터들이 인정하는 상황에서입니다.
참고자료:
- The AI Slop Loop – Lily Ray
- I hacked ChatGPT and Google’s AI and it only took 20 minutes – BBC, Thomas Germain
- Google AI Overviews Accuracy Study – New York Times / Oumi
- PoisonedRAG – Zou et al., 2024
- What’s Grokipedia? – Al Jazeera
답글 남기기