
지난 1년간 에이전트를 개발한 팀이라면 분명 이런 코드를 잔뜩 만들었을 겁니다. 시스템 프롬프트, 툴 래퍼, 플래너-실행 루프, 재시도 정책, 컨텍스트 압축 전략, 판단 모듈… 열심히 만들수록 더 많이 쌓입니다. 그리고 그 대부분은 다음 세대 모델이 등장하는 순간 녹아 없어집니다.
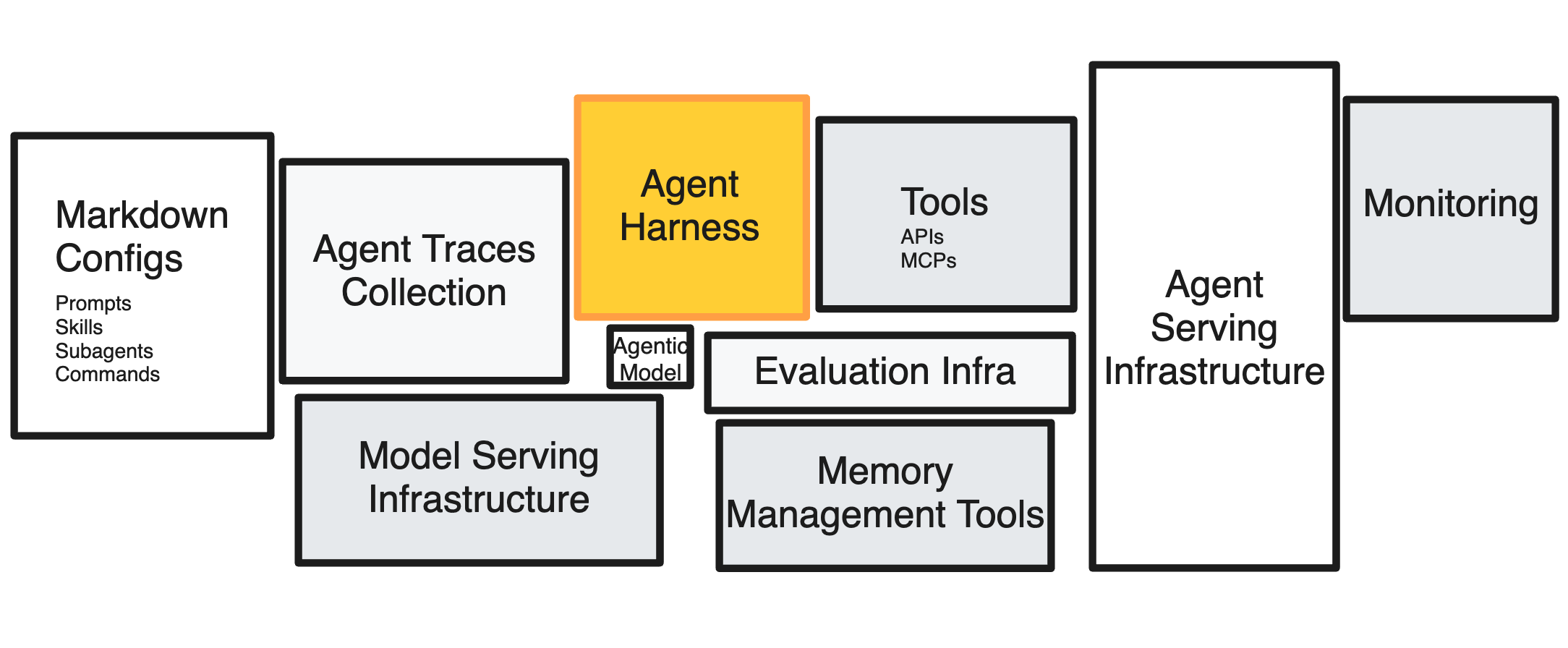
AI 엔지니어 Hanchung Lee가 자신의 블로그에 에이전트 시스템의 숨겨진 기술 부채를 다룬 시리즈 세 번째 글을 발표했습니다. 이번 편의 주제는 에이전트 하네스(Agent Harness)로, 모델과 환경 사이를 잇는 오케스트레이션 레이어 전체를 가리킵니다. 핵심 주장은 이렇습니다. 하네스는 지금 모델 수준에 맞춰 만든 2026년짜리 아티팩트일 뿐이고, 팀이 이를 영구적인 제품 구조로 취급하면 모델이 올라갈 때마다 1년치 코드를 뜯어내야 한다는 것입니다.
출처: Hidden Technical Debt of AI Systems: Agent Harness – Hanchung Lee
하네스란 무엇인가
하네스를 한 줄로 정의하면 모델과 환경 사이의 오케스트레이션 레이어입니다. 시스템 프롬프트와 페르소나, 툴 목록, 루프 형태(단일 턴인지 ReAct인지 플랜-실행인지), 컨텍스트 관리, 메모리, 서브에이전트 구조, 가드레일, 검증기, 관찰성까지 포함합니다. 저자는 이걸 운영체제에 비유합니다. 모델이 CPU라면, 하네스는 인터럽트와 인터페이스를 제공하고 메모리를 관리해 사용자에게 무한한 자원처럼 느끼게 해주는 OS입니다.
이 비유는 또 다른 함의를 담고 있습니다. 리눅스 배포판이 수십 가지인 것처럼, 하네스도 용도에 따라 형태가 전혀 다릅니다. Claude Code처럼 풀피처 하네스가 있는가 하면, pi.ai처럼 극도로 미니멀한 하네스도 있습니다. 그리고 Birgitta Böckeler가 정리한 것처럼, 하네스는 두 층이 있습니다. 모델 빌더(Anthropic, OpenAI 등)가 직접 구성한 내부 하네스와, 그 위에 사용자가 조립하는 외부 하네스(AGENTS.md, MCP 서버, 커스텀 스킬 등)입니다. 이 둘은 진화 속도가 다르고, 쌓이는 부채의 성격도 다릅니다.
모델이 강해질수록 구조가 사라진다
저자가 “하네스는 기술 부채”라고 말하는 핵심 근거는 역사적 패턴입니다.
2023년, 팀들은 복잡한 RAG 파이프라인을 만들었습니다. 모델의 컨텍스트 창이 작고 검색 능력이 약했기 때문입니다. 청커, 임베더, 벡터 스토어, 재랭커, 쿼리 재작성기까지, 엔지니어링 노력의 대부분은 ‘컨베이어 벨트’에 들어갔고 모델은 끝에서 결과만 받아가는 수동적 소비자였습니다.
2024년엔 툴 호출이 불안정했기에, 명시적인 플래너 LLM 호출과 실행 LLM 호출을 분리한 오케스트레이터-워커 워크플로를 만들었습니다. Lance Martin이 open-deep-research를 구축하면서 겪은 이야기가 좋은 예입니다. 연구 요청을 여러 섹션으로 분해하고 병렬 워커가 각 섹션을 작성하는 구조였는데, 서브에이전트 간 소통이 안 돼 결과가 따로 노는 문제가 생겼습니다. 이후 2025년에 그가 내린 결론은 구조를 제거하는 것이었습니다. 최종 작성 단계를 단일 스텝으로 합치자 시스템이 오히려 좋아졌습니다.
2025년 이후, 모델이 툴 호출을 안정적으로 하게 되면서 RAG 파이프라인의 많은 부분이, 멀티에이전트 토폴로지의 많은 부분이 모델 안으로 흡수됐습니다. Meta의 Hyung Won Chung은 이 패턴을 한 줄로 정리합니다.
“지금 가진 컴퓨팅 수준에 맞는 구조를 추가하고, 그다음에 제거하라. 구조 자체가 다음 단계의 병목이 되기 때문이다.”
모델 아키텍처에 대한 말이지만, 에이전트 하네스에도 그대로 적용됩니다.
학습 하네스와 프로덕션 하네스는 달라야 한다
저자가 가장 덜 논의된 문제로 꼽는 것이 바로 이 비대칭입니다.
프로덕션 하네스는 제약 표면입니다. 에이전트가 실제 시스템에 실제 결과를 만들어내는 환경이므로, 툴 허용 목록을 좁게 유지하고, 쓰기 작업에는 승인 단계를 두고, 최대 실행 시간과 감사 로그와 킬 스위치가 있어야 합니다. 최소 권한 원칙, 기본 거부 정책이 기본값입니다.
학습 하네스는 탐색 표면입니다. 모델이 다양한 행동을 시도하고 옵티마이저가 그 궤적으로 정책을 학습하는 환경입니다. 여기서 툴을 허용 목록으로 제한하면 모델이 그 범위 밖의 전략을 배울 기회 자체가 사라집니다. 프로덕션 하네스가 ‘재시도’를 대신해줬다면, 모델은 툴 오류에서 스스로 회복하는 법을 배운 적이 없습니다.
실제 결과가 있습니다. 같은 모델이라도 자사 하네스(1PH)에서 평가할 때와 서드파티 하네스(3PH)에서 평가할 때 성능 차이가 측정됩니다. 모델은 자신이 학습된 하네스의 툴 스키마, 루프 형태, 시스템 프롬프트 관습에 최적화되어 있기 때문입니다. 다른 인터페이스에서 실행하면 학습 분포를 벗어나는 셈입니다.
다만 저자는 이 우위가 절대적이지 않다고 지적합니다. Letta Code는 Claude Code가 약한 영구 메모리 축에 집중 투자해서, Opus 4.5 기준으로 Claude Code(41.6%)를 크게 앞선 59.1%를 기록했습니다. 자사 하네스가 소홀히 한 축에 서드파티 하네스가 집중 투자하면 격차가 역전될 수 있다는 뜻입니다.
얇은 하네스, 두꺼운 스킬
저자가 내리는 결론은 “thin harness, fat skills”입니다. 하네스는 얇게 유지하고 전문성은 스킬과 프롬프트에 담으라는 원칙입니다.
하네스는 코드이므로 모델보다는 빠르게, 프롬프트보다는 느리게 반복합니다. 자동화된 하네스 최적화 연구도 있지만, 저자는 두 가지 한계를 지적합니다. 최적화된 하네스는 학습 분포에 과적합되어 이웃 태스크에서 오히려 기본 하네스보다 못하고, 자동 최적화 과정에서 생긴 학습/프로덕션 간 불일치가 사람이 읽을 수 없는 형태로 쌓입니다.
그래서 가장 싸고 빠른 최적화 표면, 즉 텍스트 편집만으로 반영되는 스킬과 프롬프트에 도메인 전문성을 몰아넣는 편이 낫습니다. 모델 레이어는 랩에 맡기고, 하네스는 다음 모델 릴리스에서 바꿀 수 있도록 얇게 유지하는 것입니다.
저자가 제시하는 실용적인 자가 진단 방법이 있습니다. 지금 하네스의 각 구성요소를 보며 이렇게 물어보는 겁니다. “다음 분기에 모델이 의미 있게 더 똑똑해지면 이 부분은 어떻게 되는가?” 그리고 “이 부분이 쓸모없어졌을 때 제거하는 데 얼마나 걸리는가?” 한 시간이면 옵션이고, 일주일이면 부채입니다.
이것이 지금 에이전트 하네스를 둘러싼 Bitter Lesson입니다. Rich Sutton이 70년 AI 연구에서 발견한 패턴 — 사람의 영리함을 인코딩한 방법은 결국 범용 계산에 진다 — 이 지금 에이전트 레이어에서 반복되고 있습니다.
참고자료:
- Hidden Technical Debt of AI Systems: Agent Runtime – Hanchung Lee
- The Bitter Lesson of Agent Harnesses – Browser Use
- Don’t Build Multi-Agents – Cognition
답글 남기기