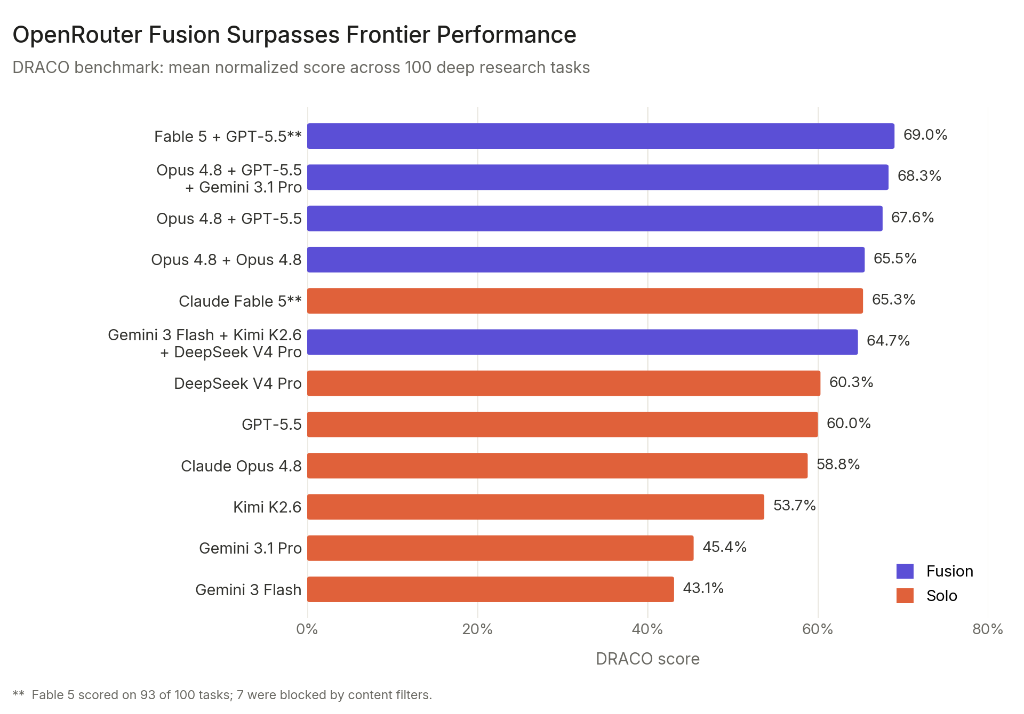
같은 딥리서치 문제를 풀었습니다. 단일 최강 모델은 65.3점을 받았습니다. 그런데 서로 다른 두 모델을 묶어 함께 답하게 했더니 69.0점이 나왔습니다. 더 흥미로운 건 따로 있습니다. 저렴한 모델 세 개를 묶은 팀이, 절반 비용으로 프런티어 단일 모델을 앞질렀습니다.

AI 인프라 플랫폼 OpenRouter가 Fusion이라는 기능을 공개했습니다. 여러 모델을 동시에 돌린 뒤, 판정 모델 하나가 그 답들을 읽고 하나의 최종 답으로 합성하는 방식입니다. 핵심 발견은 단순합니다. 모델을 여럿 묶은 ‘패널’이 어떤 단일 모델보다도 일관되게 더 나은 답을 내놓았다는 것입니다.
출처: Surpassing Frontier Performance with Fusion – OpenRouter Blog
한 번의 호출로 여러 모델을 묶는다
여러 모델에 같은 질문을 던지고 답을 비교해본 경험이 있다면, 그 과정이 얼마나 번거로운지 아실 겁니다. 한 모델에 묻고, 다른 모델과 비교하고, 세 번째도 시도해본 뒤, 어느 답이 맞는지 직접 판단해야 하죠. 결국 사용자 본인이 ‘라우터’ 역할을 하게 됩니다.
Fusion은 이 과정을 한 번의 API 호출로 압축합니다. 작동 흐름은 이렇습니다.
- 프롬프트를 여러 모델에 동시에 보냅니다. 각 모델은 웹 검색과 웹 페치 도구를 쓸 수 있습니다.
- 각 모델이 독립적으로 답을 만듭니다.
- 판정 모델이 모든 답을 읽고 구조화된 분석을 내놓습니다. 합의점은 무엇이고, 서로 모순되는 지점은 어디인지, 어느 한 모델만 짚어낸 고유한 통찰과 놓친 맹점은 무엇인지 정리하죠.
- 최종 모델이 그 분석에 근거해 답을 작성합니다.
이 전 과정이 서버에서 돌아가기 때문에, 사용하는 쪽에서는 평범한 단일 모델을 부르는 것과 똑같이 호출하면 됩니다.
패널이 단일 모델을 이기는 이유
OpenRouter는 Perplexity가 만든 딥리서치 벤치마크 DRACO의 100개 과제로 Fusion을 시험했습니다. 학술 연구, 금융, 법률, 의료, 기술 등 10개 분야에 걸친 복잡한 조사 과제로, 사실 정확성·분석의 깊이·인용 품질을 따집니다. 단순히 ‘그럴듯하게 들리는 답’과 ‘실제로 충실한 답’을 구분하도록 설계된 시험입니다.
결과는 두 갈래로 뚜렷했습니다. Anthropic의 Fable 5와 GPT-5.5를 묶은 패널은 69.0점을 받아, 단독으로 가장 높았던 Fable 5의 65.3점을 넘어섰습니다. 더 눈길을 끄는 건 비용 쪽입니다. Gemini 3 Flash, Kimi K2.6, DeepSeek V4 Pro라는 비교적 저렴한 모델 세 개를 묶은 패널이 64.7점을 기록했습니다. GPT-5.5와 Claude Opus 4.8을 각각 단독으로 돌렸을 때보다 높고, 비용은 절반 수준이었습니다.
서로 다른 관점을 가진 모델들을 한자리에 모으면, 복잡한 문제에서 더 나은 결과가 나온다는 이야기입니다. 사람으로 구성된 팀이 다양한 시각 덕에 더 좋은 결정을 내리는 것과 닮았습니다.
가장 반직관적인 발견
여기까지는 “성격이 다른 모델들을 섞으니 서로의 약점을 메운다”로 설명할 수 있습니다. 그런데 OpenRouter는 한 가지 실험을 더 했습니다. Opus 4.8을 자기 자신과 묶어 두 모델짜리 패널로 만들고, 합성도 같은 Opus 4.8에 맡긴 것입니다.
결과는 65.5점. 단독으로 돌린 Opus 4.8의 58.8점보다 6.7점이나 높았습니다.
같은 모델을 두 번 돌렸을 뿐인데 점수가 오른 이유는, 이득의 상당 부분이 모델의 ‘다양성’이 아니라 합성 단계 그 자체에서 온다는 뜻입니다. 같은 프롬프트라도 두 번 실행하면 추론 경로가 갈리고, 호출하는 도구가 달라지고, 참고하는 출처도 바뀝니다. 그렇게 갈라진 두 갈래의 답을 다시 한번 검토하고 종합하는 과정에서 품질이 올라가는 것이죠. 서로 다른 모델을 섞을 때만큼은 아니지만, 합성이라는 행위 자체에 힘이 있다는 점을 보여줍니다.
단일 모델 선택에서, 모델을 팀처럼 쓰는 방향으로
Fusion이 시사하는 바는 벤치마크 점수 너머에 있습니다. 지금까지 모델을 쓰는 기본 태도는 “가장 좋은 모델 하나를 고르고, 그게 맞기를 바라는” 것이었습니다. 새 모델이 나올 때마다 어느 것이 1등인지를 두고 비교가 벌어졌고요.
Fusion은 그 전제를 비틉니다. 하나의 모델을 천장으로 두는 대신, 여러 모델을 작은 리서치 팀처럼 다루자는 발상입니다. 어느 모델이 단독 최강인지를 묻는 질문보다, 어떤 모델들을 어떻게 조합하고 그 답을 누가 종합할지가 더 중요한 변수가 되는 셈입니다. 모델의 다양성 자체가 하나의 도구로 자리 잡는 흐름입니다.
물론 한계도 분명합니다. OpenRouter 스스로 밝혔듯 Fusion은 단일 모델을 대체하는 만능 해법이 아닙니다. 여러 모델을 거치는 만큼 응답이 평소보다 2~3배 길어질 수 있어, 빠른 답이 필요한 일상적 작업에는 어울리지 않습니다. 아키텍처 결정처럼 시간과 비용을 더 들여서라도 충실한 답이 필요한 순간에 선택적으로 쓰는 쪽이 자연스럽습니다. 어떤 작업에 여러 관점이 필요한지를 가늠하는 판단은, 여전히 사용자의 몫으로 남습니다.
답글 남기기