지금까지 우리가 고민하던 건 “어떤 모델을 호출할까”였습니다. GPT냐 Claude냐, 클라우드냐 로컬이냐. 그런데 vLLM 팀이 내놓은 그림에서는 질문 자체가 달라집니다. 모델을 한 번 호출하는 행위가, 그 뒤에서 여러 모델이 협업하는 작은 팀을 부르는 일이 되는 겁니다.

vLLM 팀이 자사 오픈소스 프로젝트인 Semantic Router의 새로운 방향을 공개했습니다. 핵심은 라우터의 역할이 바뀐다는 것이죠. 지금까지 라우터는 “이 요청은 어느 모델로 보낼까”를 정하는 교통정리 역할이었습니다. vLLM은 여기서 한 걸음 더 나갑니다. 라우터가 모델을 고르는 데 그치지 않고, 모델을 더 똑똑하게 만든다는 겁니다. 가중치를 바꾸지 않고, 별도의 에이전트 시스템을 새로 짜지도 않으면서요.
출처: Micro-Agent: Beat Frontier Models with Collaboration inside Model API – vLLM Blog
단일 모델 이름 뒤에 숨은 팀
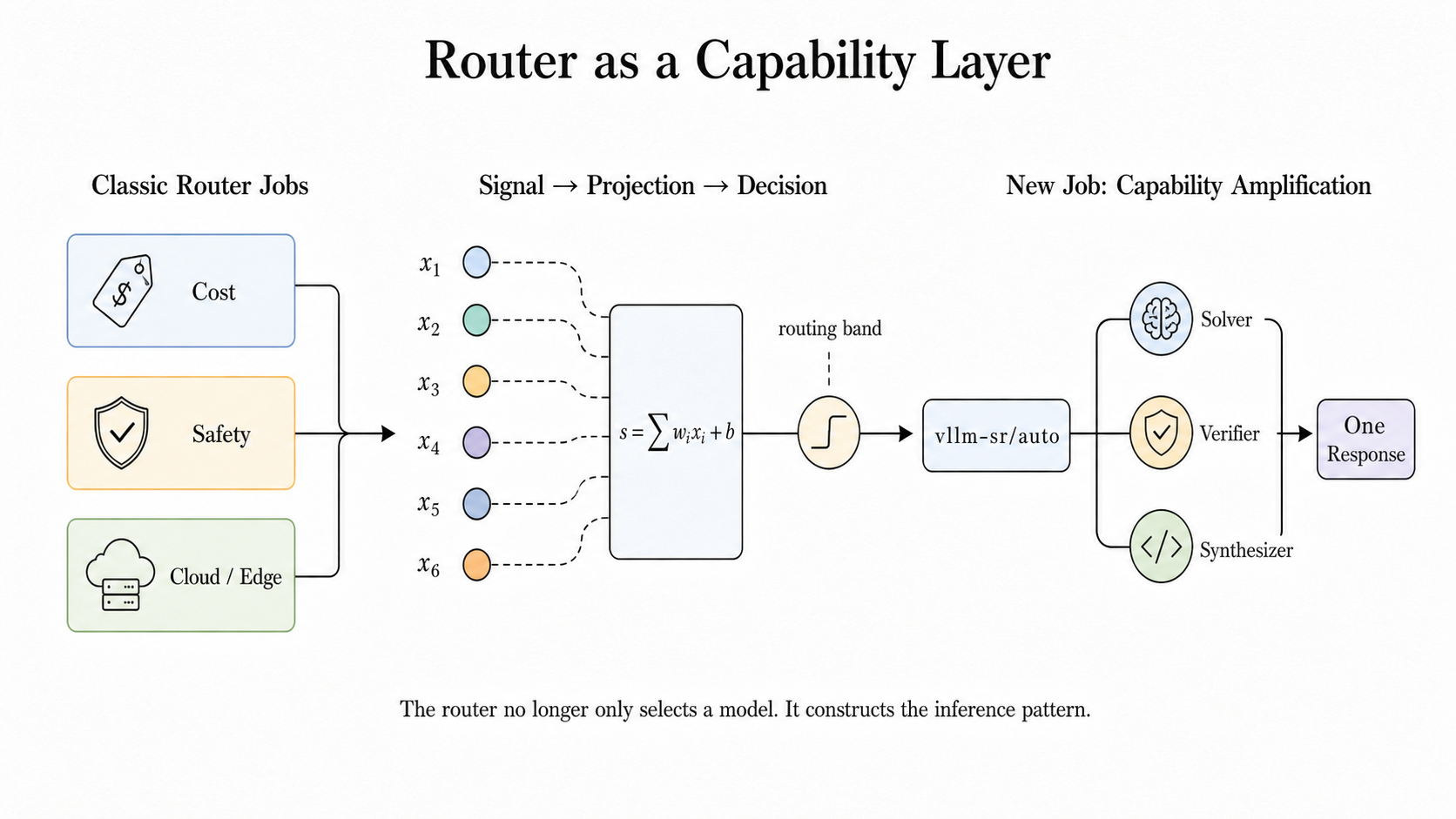
사용자가 보내는 요청은 평범합니다. vllm-sr/auto라는 모델 이름 하나를 호출하면 끝이죠. OpenAI 호환 API 그대로입니다. 달라지는 건 그 이름 뒤에서 벌어지는 일입니다.
라우터는 들어온 요청에서 신호를 뽑아냅니다. 난이도가 높은지, 위험한 도메인인지, 출력 형식을 엄격히 지켜야 하는지. 그 신호에 따라 적절한 협업 방식을 고르고, 여러 모델에 작업을 나눠 보낸 뒤(fan-out), 충분한 응답이 모이면 서로의 답을 검증하고, 최종적으로 하나의 답으로 합성해 돌려줍니다. 이 모든 과정이 단일 API 응답 안에 감춰집니다.
vLLM은 이걸 “복잡함을 드러내는 게 아니라, 협업을 모델처럼 느끼게 만드는 것”이라고 표현합니다. 사용자 입장에서는 여전히 모델 하나를 부른 것 같지만, 실제로는 작은 팀이 움직였던 셈이죠.
micro-agent를 돌리는 다섯 가지 루프
이 협업을 실제로 실행하는 런타임을 vLLM은 looper라고 부릅니다. 정해진 예산과 시간, 실패 정책 안에서 움직이는 제한된 micro-agent 실행기라고 보면 됩니다. 현재 다섯 가지 패턴이 있습니다.
- Confidence: 싼 모델부터 시도하고, 답의 확신도가 기준에 못 미칠 때만 더 강한 모델로 올라갑니다. 비용을 어려운 요청에만 쓰는 방식이죠.
- Ratings: 여러 후보를 병렬로 돌리되 동시 실행 수에 상한을 두고, 품질 점수로 가중 집계합니다.
- ReMoM: 여러 추론 시도를 펼친 뒤 일정 수 이상 성공하면, 합성 모델이 이를 하나의 정해진 출력 형식으로 통합합니다.
- Fusion: 독립적인 답들을 증거로 삼아 판정 모델이 합의와 모순, 고유한 통찰을 살핀 뒤 최종 답을 냅니다.
- Workflows: 플래너, 패처, 검증자 같은 역할을 두되 허용된 모델과 단계 수 안에서만 움직이는, 가장 에이전트에 가까운 패턴입니다.
흥미로운 건 Fusion의 발상입니다. 보통 여러 모델의 답을 모으면 평균을 내려 하죠. Fusion은 반대로 갑니다. 쓸모 있는 건 평균이 아니라 불일치의 구조라는 거죠. 모델들이 어디서 갈라지는지가 곧 신호가 됩니다. 어려운 객관식 추론이나 답이 깨지기 쉬운 문제에서, 확신에 찬 단일 응답 하나보다 서로 다른 답들의 충돌이 더 믿을 만한 판단 근거가 된다는 발상입니다.
최적의 루프는 작업 모양에 따라 다르다
vLLM이 평가 작업에서 얻은 가장 중요한 교훈은, 어느 한 알고리즘이 늘 이기는 게 아니라는 점입니다. 오히려 그 반대죠. 가장 좋은 루프는 작업의 모양을 따라간다는 겁니다.
엄격한 객관식 답을 보존해야 하는 문제, 실행 가능한 코드와 숨은 테스트를 통과해야 하는 문제, 긴 추론과 정확한 답 형식이 동시에 필요한 문제는 각각 다른 협업 패턴을 부릅니다. 그래서 vllm-sr/auto는 “항상 가장 큰 루프를 돌려라”가 아니라 “이 작업에 맞는 방식을 골라라”라는 뜻이어야 합니다.
이 차이가 router 측 협업을 단순한 프롬프트 엔지니어링과 구분 짓습니다. 프롬프트는 일부일 뿐이고, 레시피는 모델 풀, 역할, 동시 실행 수, 정족수, 타임아웃, 합성 모델, 폴백 정책, 출력 형식까지 함께 정의하니까요.
벤치마크 숫자도 이 아이디어가 그럴듯한 발상에 그치지 않는다는 걸 보여줍니다. 닫힌 모델만 조합한 VSR Closed 레시피는 LiveCodeBench 92.6, GPQA-Diamond 96.0, Humanity’s Last Exam 50.0을 기록했습니다. Fugu Ultra, GPT-5.5, Opus 4.8 같은 프런티어 단일 모델과 대등하거나 앞서는 수치죠. 핵심은 모든 요청에 모든 모델을 동원하라는 게 아닙니다. 라우터가 소유한 협업이 그 아래 개별 호출보다 더 강한 하나의 모델 정체성을 만들어낼 수 있다는 것입니다.
‘프런티어 모델’이라는 말의 두 가지 의미
vLLM은 이제 “프런티어 모델”이라는 표현이 두 가지를 뜻하기 시작했다고 봅니다. 하나는 체크포인트, 즉 학습된 가중치 한 덩어리입니다. 다른 하나는 시스템의 경계죠. 여러 모델과 정책, 폴백이 맞물려 만들어내는 하나의 표면 말입니다.
개인이 모델을 쓰는 입장에서 보면, 이건 “더 비싼 모델을 사야 더 좋은 답이 나온다”는 등식이 흔들린다는 신호이기도 합니다. 작은 모델이나 오픈소스 모델을 잘 조합하는 것만으로 프런티어급 결과에 닿을 수 있다면, 모델 선택이라는 행위의 의미 자체가 달라집니다. 우리가 호출하는 ‘모델’이 점점 단일한 무언가가 아니라, 그 뒤에 작은 팀을 거느린 표면이 되어가는 중인지도 모릅니다.
답글 남기기