지금 우리가 AI에게 기대하는 건 대체로 ‘좋은 답’입니다. 그런데 텐센트 연구진은 답을 아무리 잘해도 그것만으로는 동료가 될 수 없다고 말합니다. 분기점은 AI가 ‘답하기’를 멈추고 ‘일을 끝내기’ 시작할 때 온다는 거예요.

텐센트 Youtu Lab과 칭화대·중산대 등 연구진이 ‘From Chatbot to Digital Colleague’라는 서베이 논문을 내놨습니다. LLM이 대화형 답변 생성기에서 일을 스스로 마무리하는 ‘디지털 동료’로 넘어가는 흐름을 두 개의 축으로 정리한 글이에요. 답의 품질을 묻던 질문이, 의도를 완성된 결과물로 바꾸는 신뢰성을 묻는 쪽으로 옮겨가고 있다는 게 핵심입니다.
출처: From Chatbot to Digital Colleague: The Paradigm Shift Toward Persistent Autonomous AI – Tencent Youtu Lab
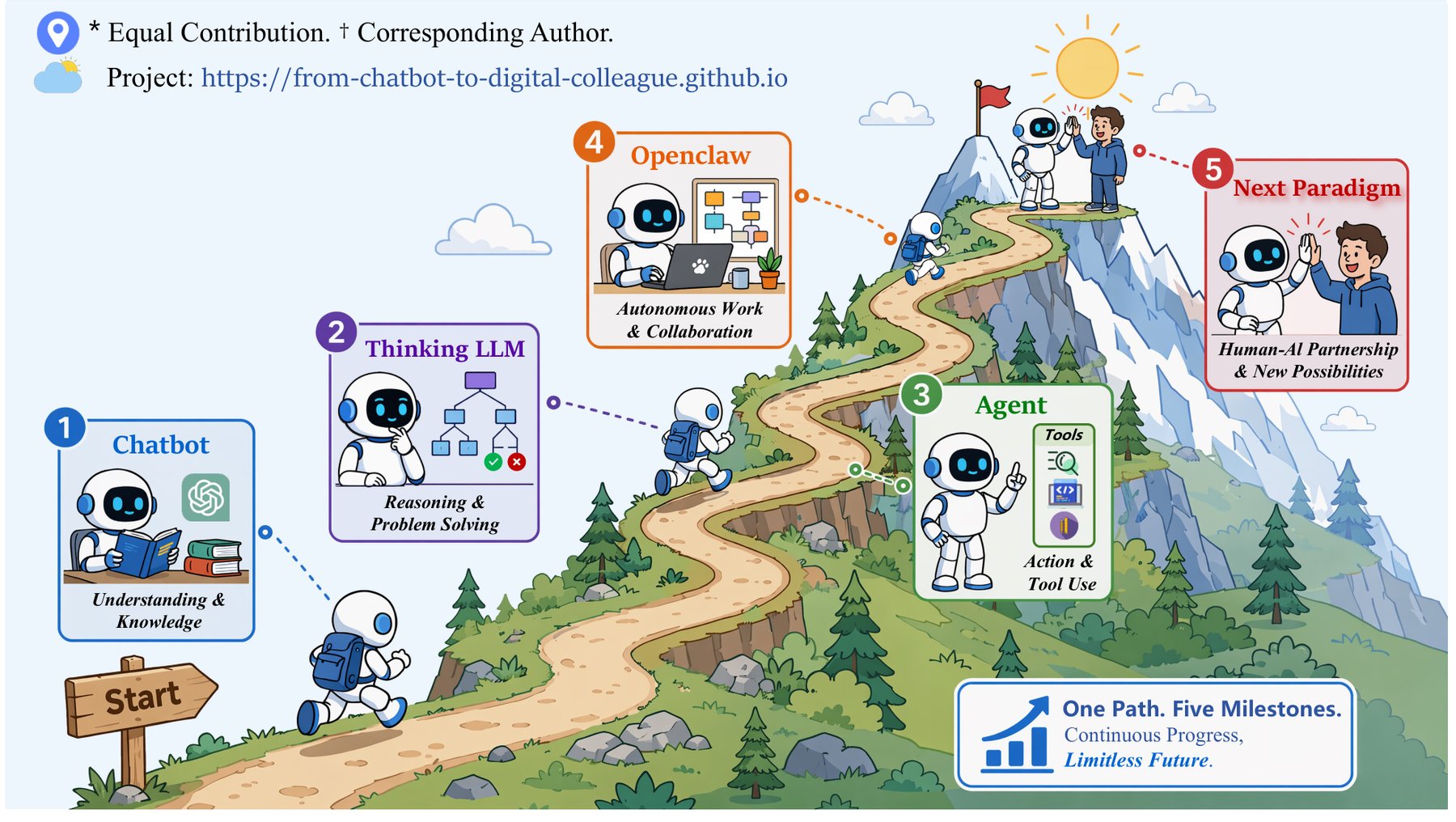
두 개의 축으로 본 AI의 진화
논문은 진화를 두 갈래로 나눠 봅니다. 하나는 모델이 ‘어떻게 생각하는가'(인지 코어), 다른 하나는 그 생각이 ‘어떻게 행동이 되는가'(작업 실행)입니다. 이 두 축을 따라 다섯 단계가 그려져요. 챗봇 → 사고형 LLM → 에이전트 → OpenClaw 워크스페이스 → 디지털 동료.
챗봇 시절의 모델은 빠르게 텍스트를 뱉어냈습니다. 파라미터에 저장된 패턴을 따라 한 번에, 토큰 단위로 가장 그럴듯한 다음 말을 이어붙였죠. 중간 점검은 없었습니다. 이어 등장한 사고형 LLM(OpenAI o1, DeepSeek-R1)은 답하는 순간에 더 많은 계산을 씁니다. 긴 사고 사슬을 펼치고, 중간 단계를 검증하고, 강화학습으로 스스로 탐색하고 고치는 법을 배웁니다. 연구진은 이를 빠르고 직관적인 ‘System 1’에서 느리고 신중한 ‘System 2’로의 이동에 빗댑니다.
진짜 도약은 ‘워크스페이스 + 스킬’에서
1세대 에이전트는 API를 부르고 코드를 쓰고 웹을 뒤질 수 있었지만 잘 부서졌습니다. 논문이 짚은 구조적 한계는 네 가지예요. 환경을 조각조각으로만 인식했고, 도구를 호출해도 상태가 남지 않았고, 예상 밖 상황에 무너졌고, 끝내 작업을 완수하지 못했습니다.
논문의 핵심 주장은 워크스페이스와 스킬의 결합이 성능의 도약을 만든다는 것입니다. 워크스페이스는 상태와 저장, 그리고 행동의 결과가 남는 공간입니다. 파일·터미널·로그·권한이 작업 전체에 걸쳐 살아남죠. 스킬은 운영 지식을 재사용 가능한 묶음으로 포장한 것입니다. Anthropic의 Agent Skills가 지시문과 스크립트, 자료를 담은 SKILL.md 형태로 이미 이 패턴을 정형화했고요. 연구진은 스킬을 프롬프트도, 전통적 도구도 아니라고 봅니다. 모델의 추론과 워크스페이스의 실행 사이에 자리 잡은, 조직의 노하우를 모듈처럼 떼었다 붙일 수 있게 만드는 무언가라는 거예요.
답의 정확도에서 작업 완수로
작동 방식이 바뀌면 채점 기준도 바뀝니다. 챗봇은 ‘지시-응답’ 쌍으로 학습하고 답이 맞았는지로 평가받았습니다. 워크스페이스 기반 시스템은 ‘상태-행동-관찰’의 궤적으로 학습합니다. 그럴듯한 답을 내놓았느냐가 아니라, 대상 환경을 검증 가능한 최종 상태까지 끌고 갔느냐가 성공의 기준이 되죠. 이걸 논문은 ‘작업 완수(task closure)’라고 부릅니다.
격차는 숫자로도 드러납니다. GPT-4는 현실적인 웹 환경을 다루는 WebArena 과제를 처음엔 14%만 완수했습니다. 정적인 Q&A 시나리오와 실제로 무언가를 끝내야 하는 환경 사이의 거리가 그만큼 멀다는 뜻이에요.
스킬이 만능은 아니라는 신호
이 청사진에는 균열을 내는 결과도 함께 실려 있습니다. Vercel의 최근 평가에서 코딩 에이전트는 제공된 스킬 시스템을 56%의 경우엔 부르지조차 않았습니다. 스킬 시스템의 성공률은 79%에서 멈춘 반면, 압축한 문서 색인을 AGENTS.md 파일에 그냥 넣어둔 쪽은 100%를 기록했고요. 늘 거기 있는 수동적 맥락이 능동적인 스킬 검색을 이긴 셈입니다. 논문 저자들도 재사용 절차가 낡아버리거나, 특정 워크플로에 과적합되거나, 공격 경로가 될 수 있다고 경고합니다.
그래서 이 논문이 던지는 그림은 ‘더 똑똑한 모델 하나’가 아닙니다. 메타·스탠퍼드·UIUC의 다른 서베이도 비슷한 결론에 닿았는데, 자율 시스템의 성능은 기반 모델보다 그 주변을 감싼 소프트웨어 층에 더 많이 달려 있다는 겁니다. AI를 ‘좋은 답을 주는 상대’로 쓰는 것과 ‘끝까지 일을 맡기는 상대’로 쓰는 건 결이 다른 일이에요. 후자로 가려면 모델만 보면 안 되고, 그 모델이 발 딛고 설 작업 공간과 검증의 구조까지 함께 봐야 한다는 신호로 읽힙니다.
답글 남기기