vLLM
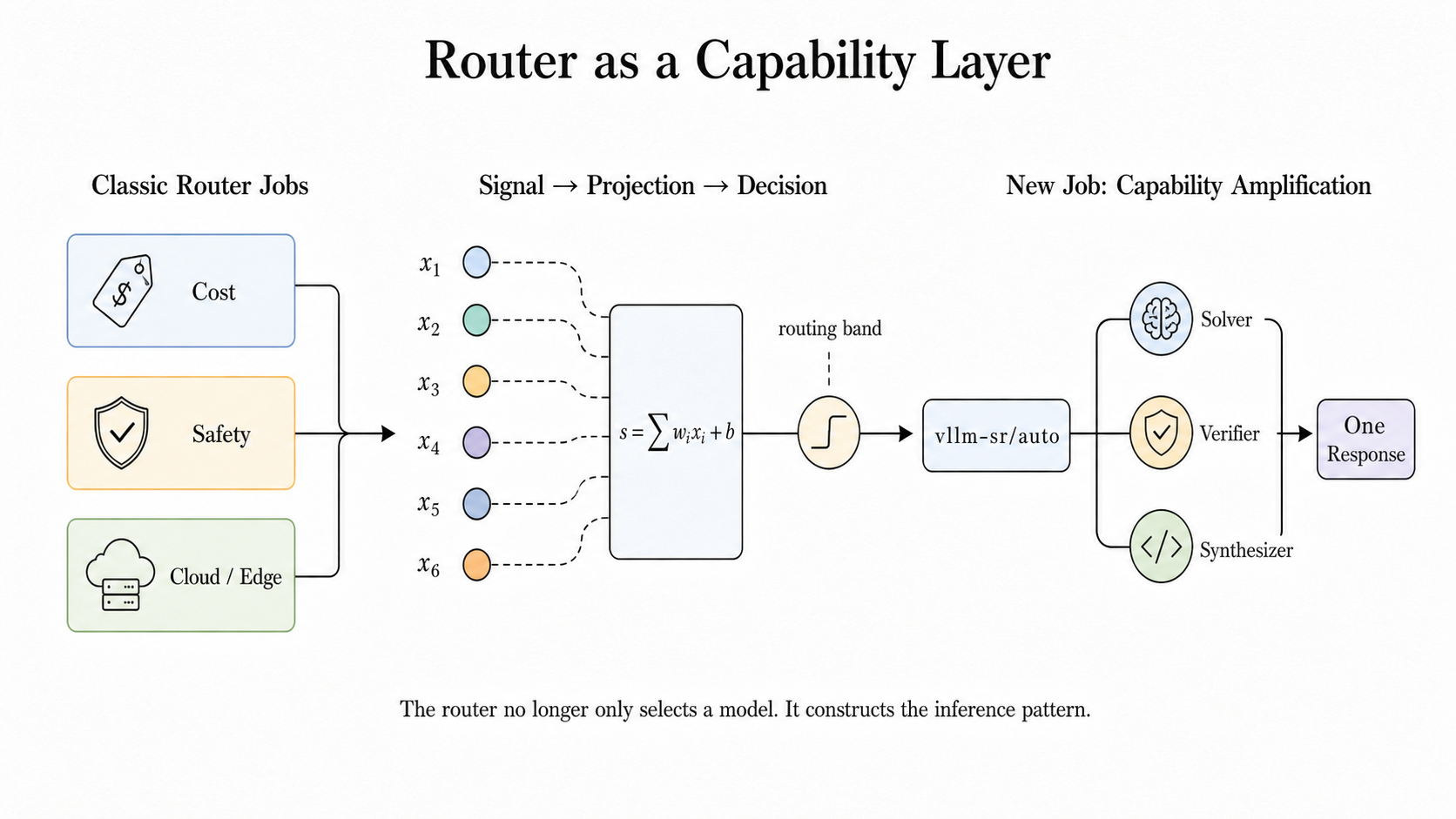
AI 모델 한 번 호출이 팀워크가 된다, vLLM 라우터가 그리는 서빙 계층의 변화
vLLM Semantic Router가 단일 모델 호출 뒤에서 여러 모델을 협업시키는 micro-agent 런타임을 공개했습니다. ‘모델’의 정의가 체크포인트에서 시스템 경계로 바뀌는 흐름을 짚습니다.
Written by
소형 모델 5개로 경제 위기를 재현하다, Thousand Token Wood가 배운 것들
3B 파라미터 소형 모델 여러 개로 멀티 에이전트 경제 시뮬레이션을 구축한 실전 보고서. 포맷은 완벽한데 판단은 엉망인 소형 모델의 한계를 시스템 설계로 메운 방법을 소개합니다.
Written by

텍스트 디제너레이션, LLM 요청 3%가 시스템 전체를 42% 느리게 만드는 원리
LLM 요청의 3%에서 발생하는 텍스트 디제너레이션이 GPU 배치 전체 처리 시간을 42% 늘리는 구조적 원인과, DPO로 발생률을 최대 87% 줄인 실험 결과를 소개합니다.
Written by

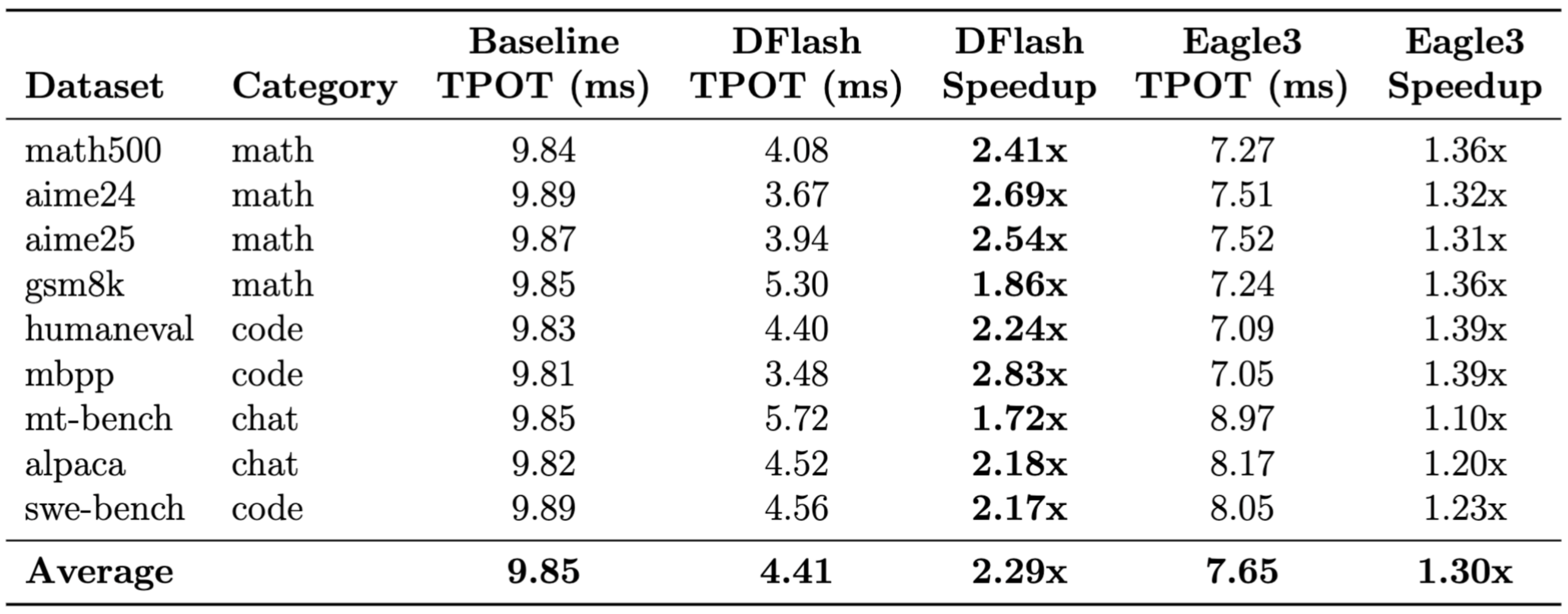
LLM 추론 속도 3배 높인 DFlash, 구글 TPU에서 디퓨전 디코딩이 작동하는 방식
UCSD 연구팀이 블록 디퓨전 방식의 DFlash를 구글 TPU에 이식해 LLM 추론 속도를 평균 3.13배 향상시킨 방법과 그 의미를 소개합니다.
Written by
책상 위의 AI 슈퍼컴퓨터: NVIDIA DGX Spark가 바꾸는 AI 개발 환경
NVIDIA DGX Spark는 128GB 통합 메모리로 200B 파라미터 AI 모델을 책상 위에서 실행할 수 있는 $4,000짜리 소형 AI 슈퍼컴퓨터입니다. 클라우드 비용 부담 없이 로컬에서 AI 개발과 파인튜닝이 가능해진 새로운 개발 환경을 소개합니다.
Written by

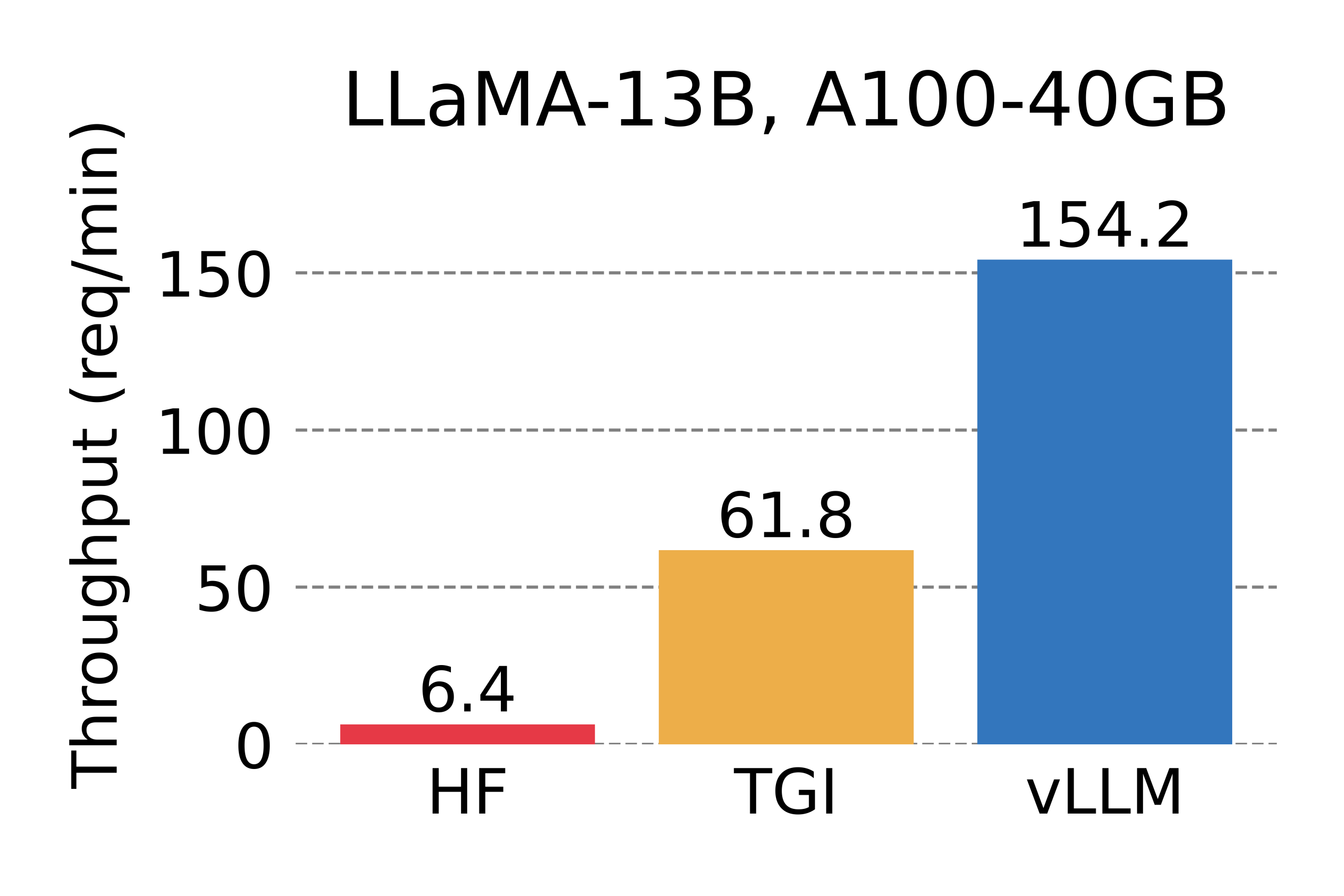
vLLM: PagedAttention으로 LLM 서빙 성능을 24배 향상시킨 혁신 기술
UC Berkeley에서 개발한 vLLM의 PagedAttention 기술이 어떻게 LLM 서빙 성능을 24배 향상시켰는지, 그리고 실제 프로덕션 환경에서의 적용 사례와 설치부터 사용까지의 실용적인 가이드를 제공합니다.
Written by