AI 기술이 비즈니스 현장에 깊숙이 자리 잡으면서, 많은 기업들이 공통으로 직면하는 문제가 있습니다. 바로 AI API 사용 비용입니다. 대량의 데이터를 처리하거나 모델 평가를 수행할 때 발생하는 높은 비용은 AI 도입의 큰 걸림돌이 되어왔죠.
구글이 최근 발표한 Gemini API Batch Mode는 이런 고민을 해결할 획기적인 솔루션입니다. 기존 API 대비 50% 저렴한 비용으로 대규모 AI 작업을 처리할 수 있게 된 것입니다.

출처: Google Developers Blog
Batch Mode란 무엇인가요?
Batch Mode는 비동기 처리 방식을 통해 대량의 AI 작업을 효율적으로 처리하는 새로운 방법입니다. 실시간 응답이 필요하지 않은 작업들을 모아서 한 번에 처리하고, 최대 24시간 이내에 결과를 받을 수 있습니다.
기존의 실시간 API 방식과 달리, Batch Mode는 다음과 같은 특징을 갖습니다:
- 비동기 처리: 요청을 보낸 후 다른 작업을 하면서 기다릴 수 있습니다
- 대용량 처리: 한 번에 수천, 수만 개의 요청을 처리할 수 있습니다
- 비용 효율성: 동일한 모델을 사용할 때 50% 저렴합니다
세 가지 핵심 장점
1. 50% 비용 절감
가장 눈에 띄는 장점은 역시 비용 절감입니다. 예를 들어, Gemini 2.5 Flash 모델을 사용한다면:
- 일반 API: 100만 토큰당 $0.075
- Batch Mode: 100만 토큰당 $0.0375
대규모 데이터 처리나 모델 평가를 자주 수행하는 기업에게는 상당한 비용 절감 효과를 가져다줍니다.
2. 높은 처리량과 완화된 제한
Batch Mode는 일반 API보다 더 높은 처리량을 제공합니다. 실시간 API의 엄격한 속도 제한에 구애받지 않고, 대량의 요청을 효율적으로 처리할 수 있습니다.
3. 간편한 관리
복잡한 클라이언트 측 큐잉이나 재시도 로직을 직접 구현할 필요가 없습니다. 요청을 제출하면 구글이 알아서 스케줄링하고 처리해줍니다.
실제 활용 사례들
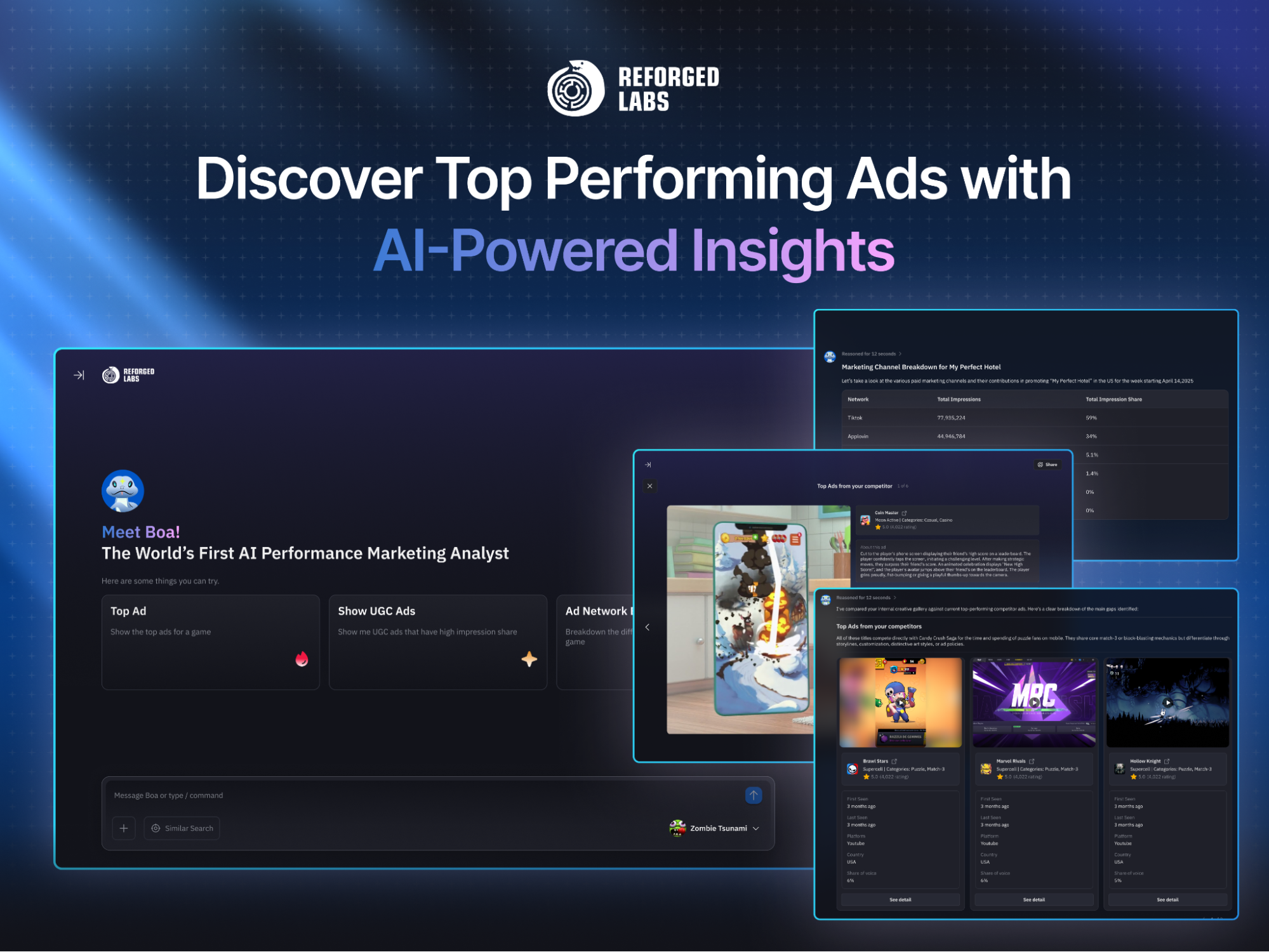
동영상 광고 분석 – Reforged Labs
Reforged Labs는 동영상 이해 분야를 전문으로 하는 회사로, 매월 막대한 양의 동영상 광고를 분석하고 라벨링하는 작업을 수행합니다. Gemini 2.5 Pro를 활용한 Batch Mode 도입으로 다음과 같은 성과를 거두었습니다:
- 비용 대폭 절감: 기존 대비 50% 비용 절약
- 처리 속도 향상: 클라이언트 납기 단축
- 확장성 확보: 의미 있는 시장 인사이트 도출을 위한 대규모 처리 가능

출처: Google Developers Blog
모델 평가 – Vals AI
Vals AI는 법률, 금융, 세무, 의료 등 실제 업무 환경에서 AI 모델을 벤치마킹하는 서비스를 제공합니다. Batch Mode를 통해:
- 대량 평가 쿼리 처리: 속도 제한에 구애받지 않고 대규모 평가 수행
- 비용 효율적 벤치마킹: 다양한 모델을 경제적으로 비교 평가
- 안정적인 서비스 운영: 예측 가능한 비용으로 서비스 확장
실제 구현 방법
Batch Mode 사용은 생각보다 간단합니다. 기본적인 사용 방법을 살펴보겠습니다.
1. 기본 설정
먼저 필요한 라이브러리를 설치하고 클라이언트를 설정합니다:
from google import genai
import json
import time
client = genai.Client()2. 간단한 인라인 요청 방식
소규모 작업(20MB 미만)의 경우 인라인 방식을 사용할 수 있습니다:
# 요청 목록 준비
inline_requests = [
{
'contents': [{
'parts': [{'text': '인공지능에 대해 간단히 설명해주세요'}],
'role': 'user'
}]
},
{
'contents': [{
'parts': [{'text': '양자컴퓨팅이 무엇인지 알려주세요'}],
'role': 'user'
}]
}
]
# 배치 작업 생성
batch_job = client.batches.create(
model="models/gemini-2.5-flash",
src=inline_requests,
config={
'display_name': "my-first-batch-job",
},
)
print(f"배치 작업 생성됨: {batch_job.name}")3. 파일 기반 방식 (대용량 처리)
대량의 요청을 처리할 때는 JSONL 파일을 사용하는 것이 좋습니다:
# JSONL 파일 생성
requests_data = [
{"key": "request-1", "request": {"contents": [{"parts": [{"text": "AI의 미래는 어떨까요?"}]}]}},
{"key": "request-2", "request": {"contents": [{"parts": [{"text": "블록체인 기술을 설명해주세요"}]}]}},
# ... 수천 개의 요청 추가 가능
]
with open("batch_requests.jsonl", "w", encoding='utf-8') as f:
for req in requests_data:
f.write(json.dumps(req, ensure_ascii=False) + "\n")
# 파일 업로드
uploaded_file = client.files.upload(
file='batch_requests.jsonl',
config={'display_name': 'my-batch-requests', 'mime_type': 'application/jsonl'}
)
# 배치 작업 생성
batch_job = client.batches.create(
model="gemini-2.5-flash",
src=uploaded_file.name,
config={
'display_name': "large-batch-job",
},
)4. 작업 상태 모니터링
배치 작업의 진행 상황을 확인할 수 있습니다:
def monitor_batch_job(job_name):
completed_states = {
'JOB_STATE_SUCCEEDED',
'JOB_STATE_FAILED',
'JOB_STATE_CANCELLED'
}
while True:
batch_job = client.batches.get(name=job_name)
print(f"현재 상태: {batch_job.state.name}")
if batch_job.state.name in completed_states:
return batch_job
time.sleep(30) # 30초마다 확인
# 작업 모니터링
final_job = monitor_batch_job(batch_job.name)5. 결과 받기
작업이 완료되면 결과를 다운로드할 수 있습니다:
if final_job.state.name == 'JOB_STATE_SUCCEEDED':
if final_job.dest and final_job.dest.file_name:
# 파일 형태의 결과
result_content = client.files.download(file=final_job.dest.file_name)
results = result_content.decode('utf-8')
# 각 라인별로 결과 처리
for line in results.splitlines():
result_data = json.loads(line)
print(f"요청 {result_data.get('key')}: {result_data.get('response')}")
elif final_job.dest and final_job.dest.inlined_responses:
# 인라인 결과
for i, response in enumerate(final_job.dest.inlined_responses):
print(f"응답 {i+1}: {response.response.text}")언제 Batch Mode를 사용해야 할까요?
Batch Mode가 적합한 상황들을 정리해보면:
적합한 경우:
- 데이터 전처리: 대량의 텍스트 데이터 정제 및 분류
- 콘텐츠 생성: 블로그 포스트, 제품 설명 등 대량 콘텐츠 생성
- 모델 평가: A/B 테스트나 성능 벤치마킹
- 분석 작업: 고객 피드백 분석, 감정 분석 등
- 번역 작업: 대량 문서의 다국어 번역
부적합한 경우:
- 실시간 채팅: 즉시 응답이 필요한 대화형 서비스
- 실시간 추천: 사용자 행동에 따른 즉석 추천
- 긴급 알림: 보안 위협 탐지 등 즉각적 대응이 필요한 경우
비용 최적화 전략
Batch Mode를 더욱 효율적으로 활용하기 위한 몇 가지 팁을 소개합니다:
1. 작업 크기 최적화
너무 큰 배치는 처리 시간이 오래 걸리고, 너무 작은 배치는 관리 오버헤드가 증가합니다. 적절한 크기로 나누어 처리하는 것이 좋습니다.
2. 컨텍스트 캐싱 활용
반복되는 컨텍스트가 있다면 컨텍스트 캐싱 기능을 함께 사용하여 추가 비용을 절약할 수 있습니다.
3. 오류 처리 계획
배치 작업에서 일부 요청이 실패할 수 있으므로, batchStats의 failedRequestCount를 확인하고 실패한 요청을 별도로 처리하는 로직을 준비해야 합니다.
다른 AI 서비스와의 비교
현재 주요 AI 서비스들의 배치 처리 지원 현황을 비교해보면:
- OpenAI: Batch API 제공 (50% 할인)
- Anthropic Claude: 배치 처리 미지원 (2024년 기준)
- Google Gemini: Batch Mode 제공 (50% 할인)
- Amazon Bedrock: 배치 추론 지원
구글 Gemini의 Batch Mode는 경쟁 서비스 대비 사용 편의성과 문서화 품질 면에서 우수한 평가를 받고 있습니다.
실제 도입 시 고려사항
개발팀 관점
- 기존 코드 마이그레이션: 실시간 API에서 배치 API로 전환하는 작업량
- 모니터링 체계: 배치 작업 상태를 추적하는 대시보드 구축
- 오류 대응: 실패한 작업의 재처리 로직
비즈니스 관점
- 처리 시간 허용도: 24시간 내 결과 수신이 비즈니스에 적합한지
- 비용 절감 효과: 월간 AI API 사용량 기준 절약 가능 금액
- 확장성 요구사항: 향후 데이터 증가에 따른 처리 능력
미래 전망과 활용 가능성
구글은 Batch Mode가 “시작에 불과하다”며 더 강력하고 유연한 기능들을 개발 중이라고 밝혔습니다. 예상되는 발전 방향은:
- 더 짧은 처리 시간: 현재 24시간에서 몇 시간 내로 단축
- 더 다양한 모델 지원: Gemini 외 다른 모델들로 확장
- 고급 스케줄링: 우선순위 기반 작업 처리
- 실시간 모니터링: 더 세밀한 진행 상황 추적
특히 한국 시장에서는 대용량 텍스트 처리가 필요한 언론사, 법무법인, 금융기관 등에서 높은 관심을 보이고 있습니다. 한국어 처리 성능이 우수한 Gemini 모델의 특성상, 국내 기업들의 AI 도입 비용 부담을 크게 줄여줄 것으로 기대됩니다.
구글 Gemini API의 Batch Mode는 AI 기술을 더 경제적이고 효율적으로 활용할 수 있는 길을 열어주었습니다. 실시간 응답이 필요하지 않은 작업들을 식별하고 Batch Mode로 전환한다면, 상당한 비용 절감과 함께 AI 활용 범위를 크게 넓힐 수 있을 것입니다.
참고자료:
답글 남기기