
벡터 검색 기반 RAG(검색 증강 생성) 시스템을 구축해 본 경험이 있다면, 그 과정이 얼마나 직관적인지 아실 것입니다. 데이터를 벡터로 변환하고 FAISS 같은 벡터 저장소에 넣은 다음, 모델이 추론 과정에서 유사한 청크를 검색하도록 하는 방식이죠.
하지만 이 방식에도 명확한 한계가 있습니다. 벡터 검색만으로는 해결하기 어려운 구조화된 질문들이 존재하기 때문입니다.
벡터 검색만으로는 부족한 이유
임베딩은 의미적 유사성을 파악하는 데 뛰어나지만, 구조적 관계는 이해하지 못합니다. “공급업체 A가 독일로 배송한다”거나 “제품 X는 온도 조절 창고가 필요하다”는 관계를 파악하지 못하죠.
이는 다음과 같은 상황에서 실제 문제가 됩니다:
- 비즈니스 로직 적용이 필요한 경우: “인증받고 같은 지역에 있는 공급업체만 보여줘”
- 구조화된 사실과 자연어를 결합해야 하는 경우: “제품 X를 위한 유럽 상위 5개 공급업체를 요약해줘”
- 설명 가능성이 필요한 경우: “왜 이 공급업체가 추천되었나?”
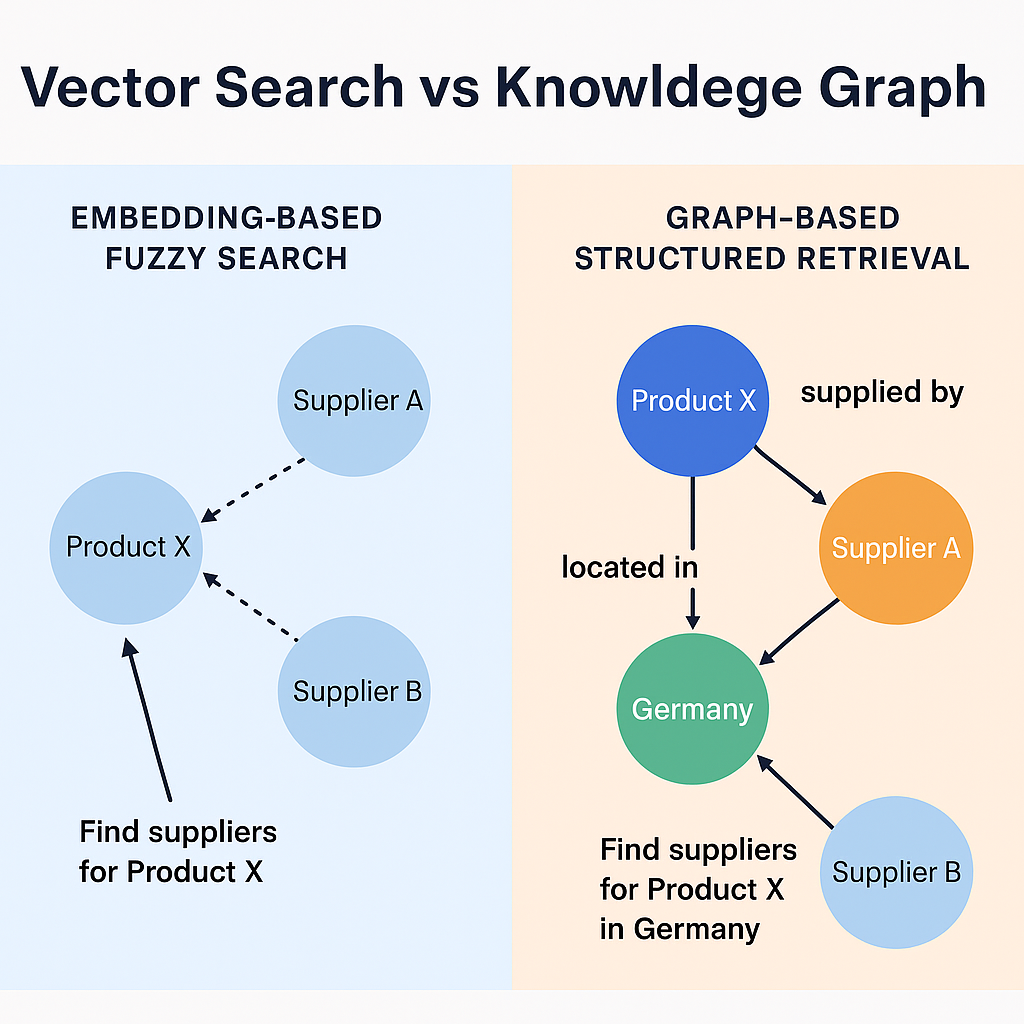
벡터 검색은 매우 똑똑한 흐림 효과와 같아서 도움이 되지만 때로는 너무 모호할 수 있습니다.
지식 그래프가 주목받는 이유
지식 그래프는 벡터와 달리 엔티티 간의 명시적 관계를 제공합니다. 제품에는 공급업체가 있고, 공급업체는 특정 위치에 서비스를 제공하며, 창고는 특정 카테고리를 저장합니다. 이런 구조가 생기면 쿼리가 훨씬 강력하고 직관적이 됩니다.
지식 그래프가 AI 기반 애플리케이션에서 유용한 이유는 다음과 같습니다:
- 구조화된 검색: 애매한 매칭에 의존하는 대신 정확한 쿼리를 작성할 수 있습니다
- 설명 가능성: 결과가 검색된 정확한 이유를 보여줄 수 있습니다
- 도메인 정렬: 그래프는 비즈니스 규칙처럼 실제 관계를 반영합니다
지식 그래프의 작동 원리
지식 그래프는 사실을 구조화해서 표현합니다. 문서나 원시 텍스트로 데이터를 저장하는 대신, “공급업체 A”나 “제품 X” 같은 엔티티와 “공급” 또는 “위치” 같은 관계로 세상을 조직화합니다.
지식 그래프의 기본 구성 요소
핵심적으로 지식 그래프는 트리플의 집합입니다:
(엔티티 A) — [관계] → (엔티티 B)
예를 들어:
- (공급업체 A) — [공급] → (제품 X)
- (공급업체 A) — [위치] → (독일)
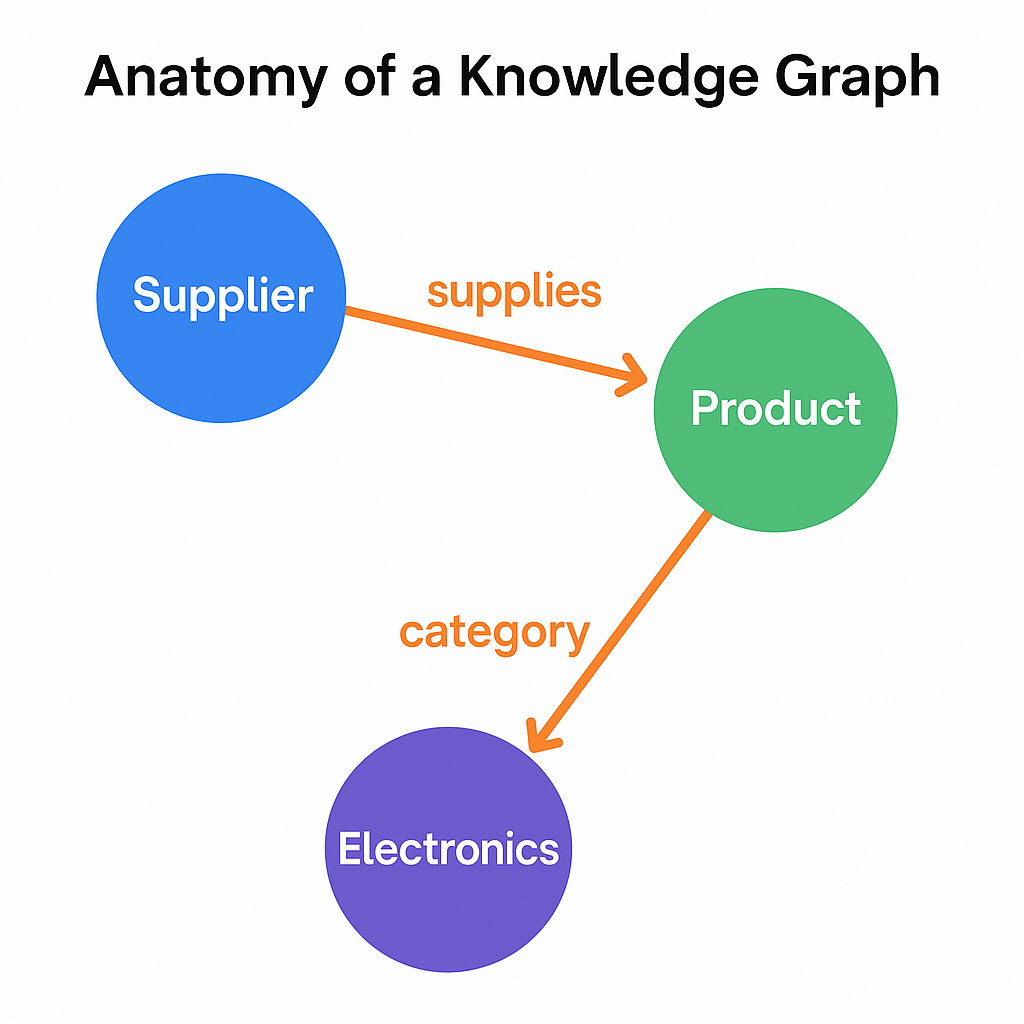
이런 트리플들은 노드와 엣지로 저장되어 함께 그래프를 형성합니다. 각 노드는 고유한 개념이나 객체를 나타내고, 각 엣지는 두 노드가 어떻게 연결되는지를 정의합니다.
그래프가 구축되면 검색이 단순한 유사성 검색을 넘어섭니다. 경로를 따라가고, 제약 조건을 적용하고, 정확한 질문에 답할 수 있습니다. 예를 들어:
- 유럽에서 전자 부품을 제공하는 공급업체는?
- 공급업체 B가 지난 분기에 배송한 제품은?
그래프는 구조와 계층을 이해합니다. 노드와 엣지 때문에 “공급업체 B”가 특정 구매 주문과 관련이 있고 “유럽”에 독일, 프랑스 등이 포함된다는 것을 알고 있습니다.
실제 구현: 공급망 질의응답 시스템 구축
이 글에서는 Supermemory 블로그의 상세한 튜토리얼을 바탕으로 실제 동작하는 지식 그래프 기반 RAG 시스템을 구축하는 방법을 단계별로 살펴보겠습니다. 이 시스템은 공급망 데이터를 활용해 자연어 질문에 답하는 실용적인 예제입니다.
1단계: 환경 설정 및 의존성 설치
먼저 로컬 환경에서 지식 그래프를 구축하고 쿼리할 수 있도록 준비해야 합니다.
필요한 구성 요소:
- Python 3.8+
- Neo4j Desktop
- OpenAI 계정 (트리플 추출용)
- Jupyter Notebook 또는 Python IDE
터미널에서 다음 라이브러리들을 설치합니다:
pip install pandas py2neo openai neo4j datasetspy2neo는 Python에서 Neo4j와 작업하기 위한 공식 라이브러리이고, openai는 LLM 요청을 도와주며, datasets을 통해 조달 KPI 분석 데이터셋을 다운로드할 수 있습니다.
2단계: Neo4j 실행
Neo4j Desktop을 설치하고 새 프로젝트를 생성합니다. SupplyChainKG라는 이름으로 인스턴스를 만들고, 데이터베이스 사용자를 생성한 후 비밀번호를 설정합니다(코드에서 사용할 예정).
연결 정보:
- Connection URI:
neo4j://127.0.0.1:7687 - Username:
neo4j - Password: 설정한 비밀번호
3단계: 라이브러리 가져오기 및 Neo4j 연결
import ast
from py2neo import Graph, Node, Relationship
# 실행 중인 Neo4j 데이터베이스 인스턴스에 연결
graph = Graph("neo4j://localhost:7687", auth=("neo4j", "testpassword"))4단계: 그래프 구축 함수 정의
GPT의 응답(트리플 문자열)을 파싱하고 Neo4j 그래프에 노드와 관계를 구축하는 함수를 만듭니다:
def build_graph_from_gpt_response(gpt_response):
try:
# GPT 응답을 안전하게 파싱 (튜플 리스트의 문자열)
triples = ast.literal_eval(gpt_response)
except Exception as e:
print("파싱 오류:", e)
return
for triple in triples:
# 트리플이 유효하고 정확히 3개 항목을 포함하는지 확인
if len(triple) != 3:
continue
# 모든 부분을 문자열로 변환하고 공백 제거
subject, predicate, obj = [str(x).strip() for x in triple]
# 주어와 목적어를 위한 그래프 노드 생성
subj_node = Node("Entity", name=subject)
obj_node = Node("Entity", name=obj)
# 노드 간 관계 생성
relationship = Relationship(subj_node, predicate, obj_node)
# 중복 방지를 위한 병합; 노드/엣지가 존재하면 업데이트
graph.merge(subj_node, "Entity", "name")
graph.merge(obj_node, "Entity", "name")
graph.merge(relationship)5단계: 데이터 처리 및 트리플 추출
조달 KPI 분석 데이터셋에서 몇 개 행을 가져와 GPT를 통해 구조화된 지식을 추출합니다:
import pandas as pd
from openai import OpenAI
# OpenAI 클라이언트 초기화
client = OpenAI(api_key="OPENAI_API_KEY")
# 조달 KPI 분석 데이터셋 로드
df = pd.read_csv("Procurement KPI Analysis Dataset.csv")
for i in range(5): # 5개 행으로 시작
row = df.iloc[i]
# 구조와 예제가 포함된 명확한 프롬프트
prompt = f"""
다음 구조화된 구매 주문에서 주어-서술어-목적어 트리플을 추출하세요.
결과를 유효한 Python 3-항목 튜플 리스트로 반환하세요.
예제 형식:
[
("Delta Logistics", "supplies", "Raw Materials"),
("Raw Materials", "has_quantity", "1180"),
("Raw Materials", "has_price", "64.07")
]
구매 주문:
공급업체: {row['Supplier']}
항목 카테고리: {row['Item_Category']}
수량: {row['Quantity']}
단가: {row['Unit_Price']}
주문 상태: {row['Order_Status']}
컴플라이언스: {row['Compliance']}
"""
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}],
temperature=0
)
content = response.choices[0].message.content.strip()
print(f"행 {i}의 트리플:", content)
# 반환된 트리플에서 그래프 구축
build_graph_from_gpt_response(content)6단계: 지식 그래프 쿼리 (RAG)
이제 자연어 질문을 테스트해봅시다: “원자재를 제공하는 공급업체는?”
Neo4j의 Cypher 쿼리 언어를 사용합니다:
question_query = """
MATCH (s:Entity)-[:supplies]->(c:Entity {name: "Raw Materials"})
RETURN s.name AS supplier
"""
# Cypher 쿼리 실행
suppliers = graph.run(question_query).data()
print("원자재 공급업체:", suppliers)7단계: 자연어 답변 생성
Cypher 출력을 사람이 읽기 쉬운 텍스트로 변환합니다:
def format_answer(suppliers):
if not suppliers:
return "원자재를 제공하는 컴플라이언트 공급업체를 찾을 수 없습니다."
names = [s["supplier"] for s in suppliers]
return f"다음 컴플라이언트 공급업체들이 원자재를 제공합니다: {', '.join(names)}."
# 최종 답변 출력
print(format_answer(suppliers))
지식 그래프 품질 측정 방법
지식 그래프를 구축하는 것은 좋지만, 실제로 품질이 좋은지 어떻게 알 수 있을까요? 그래프가 Neo4j에서 잘 시각화되어 보일 수 있지만, 내부적으로는 핵심 연결이 누락되거나 잘못된 관계가 포함되어 있을 수 있습니다.
커버리지(Coverage)
커버리지는 그래프가 실제 데이터 중 얼마나 많은 부분을 노드와 엣지 형태로 캡처했는지를 나타냅니다:
# CSV의 고유 공급업체 수
total_suppliers = df['Supplier'].nunique()
# 그래프에서 연결된 공급업체 노드 수
query = """
MATCH (s:Entity)
WHERE EXISTS {
MATCH (s)-[]->()
}
RETURN count(DISTINCT s.name) AS linked_suppliers
"""
linked_suppliers = graph.run(query).data()[0]['linked_suppliers']
coverage_percent = (linked_suppliers / total_suppliers) * 100
print(f"공급업체 노드 커버리지: {coverage_percent:.2f}%")정확성(Accuracy)
그래프의 관계가 실제로 올바른지 확인합니다. 샘플 트리플을 수동으로 검토하고 원본 데이터와 비교하는 것이 좋은 방법입니다:
sample_check = graph.run("""
MATCH (a:Entity)-[r]->(b:Entity)
RETURN a.name AS subject, type(r) AS relation, b.name AS object
LIMIT 10
""").to_data_frame()
print(sample_check)완전성(Completeness)
모든 관련 연결이 추출되고 표현되었는지 확인합니다. 예를 들어, 모든 공급업체가 컴플라이언스 등급을 가져야 하는데 일부 공급업체에 컴플라이언스 엣지가 없다면 누락이 있는 것입니다.
실무 적용 시 고려사항
지식 그래프 기반 RAG는 벡터 검색만으로는 해결할 수 없는 실제 문제의 해결책입니다. 구조화된 질문에 답하거나 복잡한 데이터에 로직을 적용하는 데 어려움을 겪었다면, 이 조합이 파이프라인에 안정성과 구조를 가져다줍니다.
벡터와 그래프를 결합하면 양쪽의 장점을 모두 얻을 수 있습니다: 자연어 이해의 유연성과 함께 구조화되고 신뢰할 수 있는 사실들을 활용할 수 있죠.
현재 많은 기업들이 이런 하이브리드 접근법을 채택하고 있으며, PDF, 이메일, 공급망 등 다양한 도메인에서 활용되고 있습니다. 특히 설명 가능성이 중요한 비즈니스 환경에서는 지식 그래프의 명시적 관계 구조가 큰 장점이 됩니다.
참고자료:
답글 남기기