NVIDIA가 내부 AI 에이전트를 단일 사용자에서 1,000명 동시 사용자까지 확장한 실제 경험을 바탕으로 한 체계적인 방법론을 소개합니다.
혼자서는 잘 되는데, 다같이 쓰면 어떻게 될까?
AI 에이전트 하나 만들기도 힘든데, 이제 회사 동료 1,000명이 동시에 사용한다고 생각해보세요. 서버가 뻗어버릴까요? 응답이 너무 느려질까요? 아니면 멀쩡하게 잘 작동할까요?
NVIDIA는 최근 이런 고민을 직접 해결해야 했습니다. 내부적으로 사용하던 AI-Q 리서치 에이전트를 전사에 배포하면서 말이죠. 이 과정에서 얻은 노하우를 NVIDIA 개발자 블로그에서 공개했습니다.

확장의 3단계 전략: 프로파일링부터 모니터링까지
NVIDIA가 제시하는 방법은 단순명료합니다. 세 단계로 나누어 체계적으로 접근하는 것이죠.
1단계: 혼자서 먼저 완벽하게 만들기
“일단 많은 사용자를 위해 서버를 늘리자!”라고 생각하기 쉽습니다. 하지만 NVIDIA는 정반대로 접근했습니다. 먼저 단일 사용자 환경에서 완벽하게 작동하는지 철저히 분석한 것이죠.
NeMo Agent Toolkit의 프로파일링 도구를 사용했습니다. 이 도구는 AI 에이전트가 실행되는 동안 각 단계별 시간과 토큰 사용량을 자동으로 추적합니다.
eval:
general:
output_dir: single_run_result
dataset:
_type: json
file_path: example_inputs.json
profiler:
token_uniqueness_forecast: true
workflow_runtime_forecast: true
compute_llm_metrics: true가장 유용했던 것은 간트 차트입니다. 에이전트가 어떤 작업을 언제 수행하는지 시각적으로 보여주죠. NVIDIA는 이를 통해 병목 지점이 NVIDIA Llama Nemotron Super 49B 추론 LLM 호출이라는 것을 발견했습니다.

2단계: 부하 테스트로 한계점 찾기
이제 본격적인 스트레스 테스트입니다. NVIDIA는 10명, 20명, 30명… 이런 식으로 단계적으로 동시 사용자 수를 늘려가며 테스트했습니다.
aiq sizing calc
--calc_output_dir $CALC_OUTPUT_DIR
--concurrencies 1,2,4,8,16,32
--num_passes 2결과는 명확했습니다. GPU 하나가 10명의 동시 사용자를 처리할 수 있다면, 100명을 위해서는 10개의 GPU가 필요하다는 계산이 나온 것이죠.
하지만 더 중요한 발견들이 있었습니다:
CPU 부족 문제: 모니터링 결과, NVIDIA NIM 마이크로서비스 하나가 CPU를 100% 사용하고 있었습니다. 원인을 찾아보니 헬름 차트 설정 오류로 필요한 CPU보다 적게 할당되어 있었던 것이죠.
에러 핸들링 부족: LLM 호출이 타임아웃될 때 전체 사용자 경험이 망가지는 경우들을 발견했습니다. 재시도 로직과 더 나은 에러 처리를 추가해야 했습니다.
try:
async with asyncio.timeout(ASYNC_TIMEOUT):
async for chunk in chain.astream(input, stream_usage=True):
answer_agg += chunk.content
# ... 처리 로직
except asyncio.TimeoutError as e:
writer({"generating_questions": "Timeout error from reasoning LLM, please try again"})
return {"queries": []}3단계: 실시간 모니터링으로 안전하게 배포
마지막 단계는 실제 배포입니다. 하지만 갑자기 1,000명에게 오픈하지 않았습니다. 작은 팀부터 시작해서 점진적으로 사용자를 늘려갔죠.
이때 핵심은 실시간 모니터링입니다. OpenTelemetry 수집기와 Datadog을 연결해서 모든 사용자 세션을 추적했습니다.
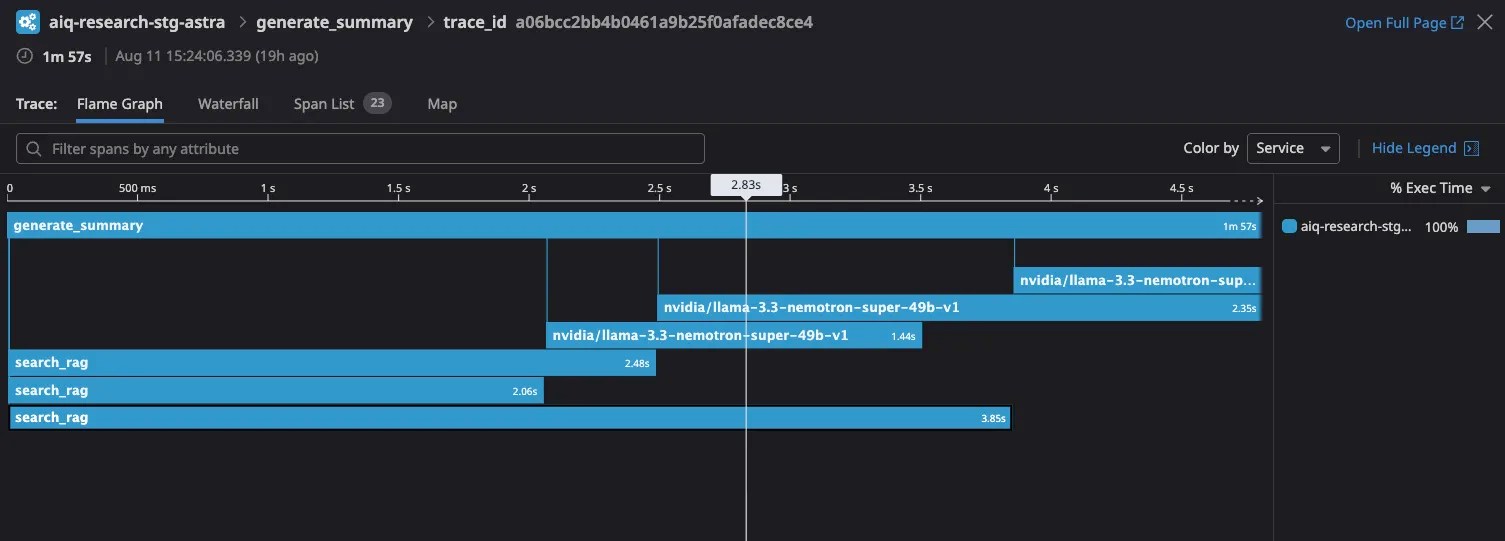
개별 사용자 세션뿐만 아니라 전체적인 성능 트렌드도 파악할 수 있었습니다. 평균 지연시간과 예외적으로 느린 요청들을 구분해서 볼 수 있죠.
실무진이 알아야 할 핵심 인사이트
이 사례에서 가장 중요한 교훈은 단계적 접근의 중요성입니다. 많은 회사들이 “일단 서버부터 늘리자”는 식으로 접근하다가 예상치 못한 문제들에 부딪힙니다.
도구의 활용도 중요합니다. NVIDIA는 자사의 NeMo Agent Toolkit을 사용했지만, 핵심은 프로파일링, 부하 테스트, 모니터링을 체계적으로 수행하는 것입니다. 다른 도구를 사용하더라도 같은 접근법을 적용할 수 있습니다.
예상치 못한 병목 지점들: CPU 부족, 설정 오류, 에러 핸들링 부족 등은 단일 사용자 테스트에서는 발견하기 어려운 문제들입니다. 부하 테스트를 통해서만 확인할 수 있죠.
AI 에이전트 확장, 이제 두렵지 않다
AI 에이전트를 프로덕션으로 확장하는 일은 더 이상 미지의 영역이 아닙니다. NVIDIA의 사례처럼 체계적으로 접근하면 충분히 해결할 수 있는 문제입니다.
중요한 것은 성급하게 서버만 늘리는 것이 아니라, 단일 사용자부터 시작해서 단계적으로 확장해나가는 것입니다. 그리고 각 단계마다 데이터에 기반해서 의사결정을 내리는 것이죠.
여러분의 AI 에이전트도 1,000명이 동시에 사용할 수 있습니다. 다만 올바른 방법으로 준비한다면 말이죠.
참고자료: How to Scale Your LangGraph Agents in Production From A Single User to 1,000 Coworkers
답글 남기기