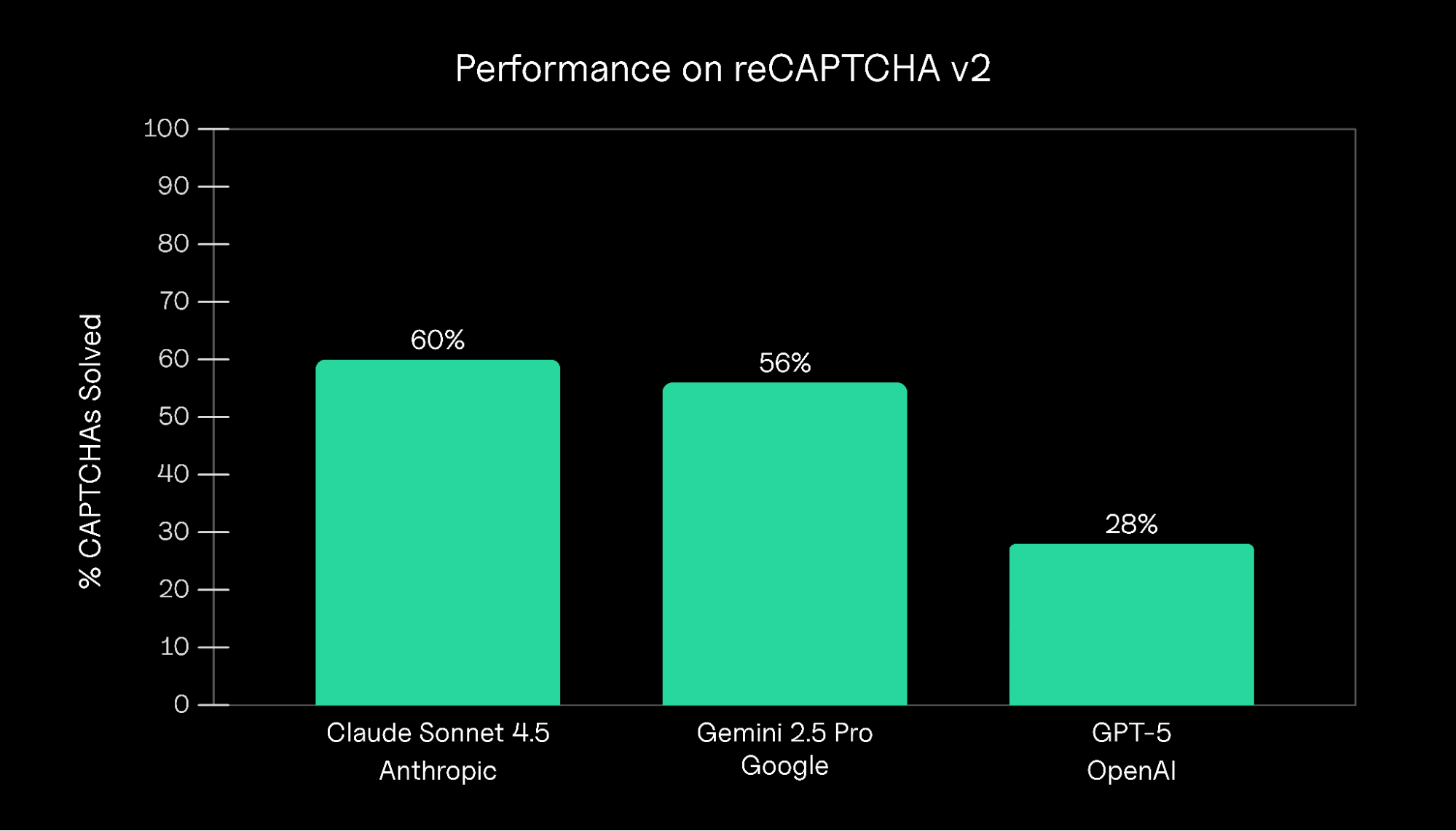
“사람인지 로봇인지 구별하기 위해” 만들어진 CAPTCHA. 하지만 최신 AI 모델이 60%의 정확도로 풀어버린다면, 이 보안 장치는 여전히 유효할까요? 더 흥미로운 건 최신 모델일수록 성능이 나쁘다는 점입니다.

AI 에이전트 연구 기관 Roundtable이 Claude Sonnet 4.5, Gemini 2.5 Pro, GPT-5 세 가지 최신 AI 모델의 Google reCAPTCHA v2 풀이 능력을 벤치마크한 결과를 발표했습니다. 핵심 발견은 두 가지입니다. 첫째, Claude가 60%로 가장 높은 성공률을 보였고 GPT-5는 28%로 최악의 성능을 기록했습니다. 둘째, 그 이유가 ‘과도한 추론’ 때문이라는 점입니다.
출처: Benchmarking Leading AI Agents Against CAPTCHAs – Roundtable Research
최신 모델이 최악의 성능? 과도한 추론의 역설
결과는 예상 밖이었습니다. Claude Sonnet 4.5가 60%의 성공률로 1위를 차지했고, Gemini 2.5 Pro가 56%로 그 뒤를 이었습니다. 하지만 가장 최신 모델인 GPT-5는 겨우 28%만 성공했죠.
연구팀이 발견한 원인은 ‘overthinking’이었습니다. Browser Use라는 AI 에이전트 프레임워크는 ‘생각하기(Thinking) → 행동 → 관찰 → 반복’ 방식으로 작동하는데, GPT-5는 매 단계마다 지나치게 긴 추론을 생성했습니다. 같은 사각형을 반복적으로 클릭하고 해제하며 끊임없이 수정을 시도했고, 그 결과 타임아웃으로 실패하는 경우가 빈번했습니다.
실제로 GPT-5는 Claude나 Gemini보다 평균적으로 훨씬 더 많은 ‘Thinking’ 문자를 생성했습니다. 더 깊게 생각한다는 건 장점처럼 보이지만, 실시간으로 반응해야 하는 상황에서는 치명적인 약점이 됐죠.
CAPTCHA 유형별로 본 AI의 약점
CAPTCHA는 크게 세 가지 유형으로 나뉩니다. Static(정적 3×3 그리드), Reload(클릭하면 이미지가 바뀌는 동적 형식), Cross-tile(4×4 그리드에서 객체가 여러 칸에 걸쳐 있음)이 그것입니다.
모든 모델이 Static에서 가장 높은 성능을 보였고, Cross-tile에서는 거의 풀지 못했습니다. Claude는 Cross-tile에서 0%, Gemini는 1.9%, GPT-5는 1.1%의 성공률을 기록했죠.
흥미로운 건 인간에게는 Cross-tile이 오히려 쉽다는 점입니다. 한 칸에서 목표 객체를 발견하면 인접한 칸으로 자연스럽게 확장할 수 있기 때문이죠. 하지만 AI는 부분적이거나 가려진 객체, 경계를 넘나드는 물체를 인식하는 데 어려움을 겪었고, 거의 항상 완벽한 직사각형 형태로만 선택했습니다. 이는 인간과 AI의 시각 인지 방식이 근본적으로 다르다는 걸 보여줍니다.
Reload 유형도 까다로웠습니다. 에이전트들이 올바른 사각형을 클릭한 뒤 제출하려고 하면 새로운 이미지가 나타나거나 reCAPTCHA가 재확인을 요구했는데, 이를 오류로 해석해 이전 클릭을 취소하거나 반복하는 실패 루프에 빠졌습니다.
더 많은 추론이 항상 답은 아니다
이번 연구가 던지는 메시지는 명확합니다. 더 많이 생각한다고 해서 항상 더 나은 결과가 나오는 건 아닙니다. 특히 실시간으로 반응해야 하는 에이전트 환경에서는 빠르고 확신 있는 결정이 깊은 추론만큼이나 중요합니다.
채팅 환경에서 긴 응답 시간은 사용자를 불편하게 만들지만, 실시간 작업 환경에서는 아예 작업 자체를 실패로 만들어버립니다. 에이전트 아키텍처가 집착적 행동을 부추기거나 동적 인터페이스에 제대로 대응하지 못하면 이런 문제는 더욱 악화되죠.
CAPTCHA의 관점에서 보면, 여전히 어느 정도의 보안 역할을 하고 있다는 뜻이기도 합니다. 특히 Cross-tile 같은 유형은 AI에게 여전히 큰 장벽입니다. 하지만 60%라는 숫자는 결코 안심할 수준이 아닙니다. 기술이 계속 발전하면 이 격차는 더 좁혀질 테니까요.
답글 남기기