구글의 NotebookLM이 보여준 ‘PDF를 팟캐스트로 변환하는 마법’을 직접 만들 수 있다면 어떨까요? Meta가 공개한 NotebookLlama는 바로 그 오픈소스 구현체입니다. 블랙박스 없이 전 과정을 제어하면서, 어떤 PDF든 자연스러운 2인 대화 팟캐스트로 변환할 수 있죠.

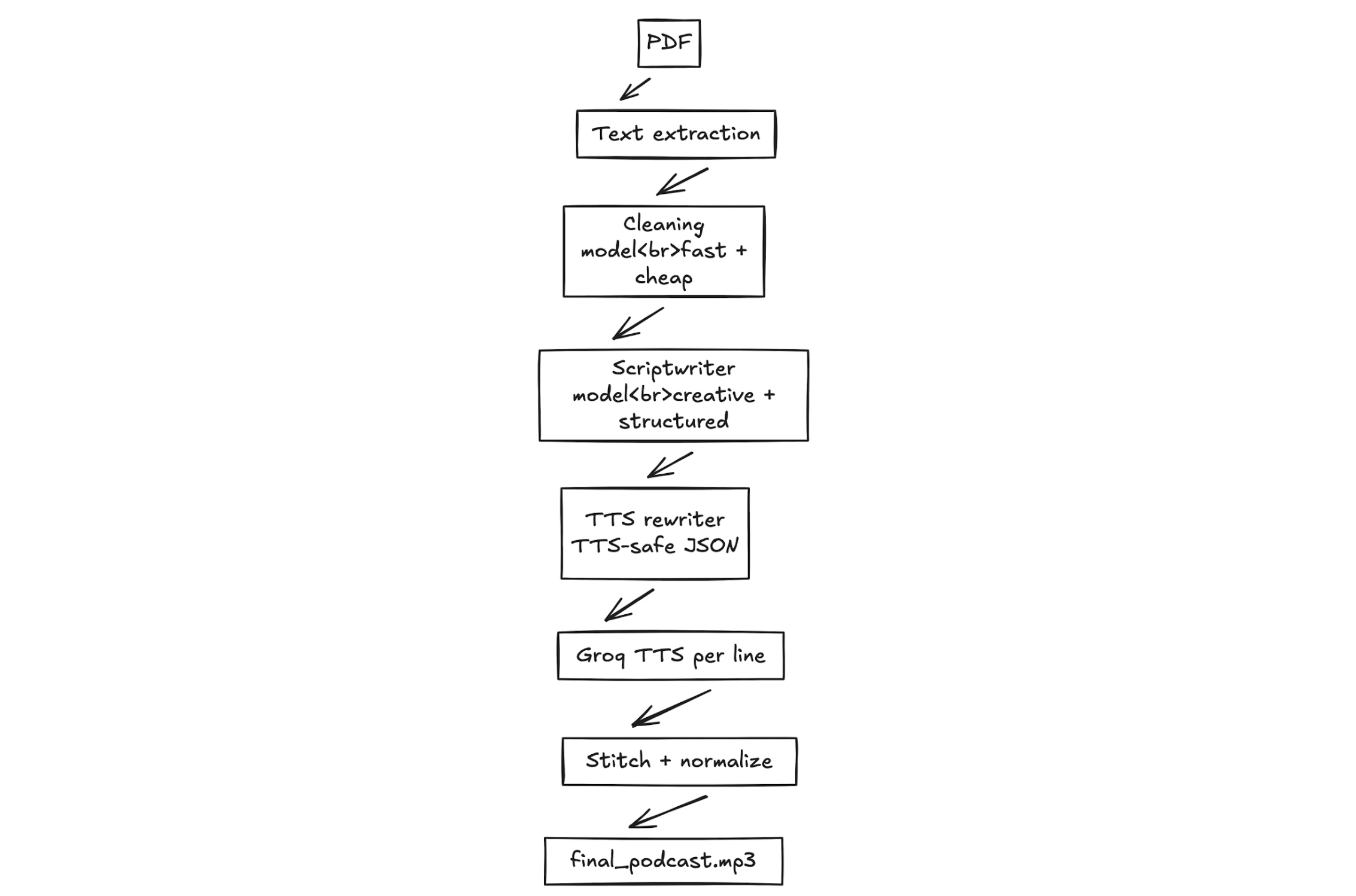
Analytics Vidhya가 NotebookLlama의 실전 구현 가이드를 상세히 정리했습니다. Meta의 Llama 모델과 Groq API를 조합해 PDF에서 완성된 MP3 팟캐스트를 만드는 전체 파이프라인을 단계별로 설명하는 튜토리얼인데요, 실행 가능한 Colab 노트북까지 제공해 누구나 따라할 수 있게 구성했습니다.
출처: Build Your Own NotebookLlama: A PDF to Podcast Pipeline – Analytics Vidhya
똑똑한 4단계 워크플로우
NotebookLlama의 핵심은 각 단계마다 최적화된 모델을 사용한다는 점입니다. 마치 요리할 때 손질은 빠르게, 조리는 정성껏 하듯이 말이죠.
1단계: PDF 전처리 (PyPDF2 + Llama 3.1 8B)
PDF에서 추출한 텍스트는 엉망입니다. 줄바꿈이 이상하고, 수식 기호가 섞여있고, 각주와 참고문헌이 뒤섞여 있죠. 여기서 빠르고 가벼운 Llama 3.1 8B 모델이 등장합니다. 이 모델은 불필요한 정보를 제거하고 깔끔한 텍스트로 정리하는 역할만 담당합니다. 무거운 모델을 쓸 필요 없는 단순 작업이니 비용과 시간을 아끼는 거죠.
# 텍스트를 1000단어 단위 청크로 나눠서 처리
chunks = create_word_bounded_chunks(text_to_clean, 1000)
# 각 청크를 Llama 3.1 8B로 청소
for chunk in chunks:
messages = [
SystemMessage(content=SYS_PROMPT),
HumanMessage(content=chunk),
]
response = chat_model.invoke(messages)2단계: 팟캐스트 대본 작성 (Llama 3.3 70B)
이제 창의성이 필요한 단계입니다. 70B 크기의 큰 모델이 깔끔해진 텍스트를 읽고, 두 명의 화자가 대화하는 팟캐스트 대본을 작성합니다. Speaker 1은 전문가 역할로 설명하고, Speaker 2는 호기심 많은 학습자로 질문을 던지죠. “umm”, “hmm” 같은 자연스러운 추임새까지 포함해서요.
프롬프트 설계가 핵심입니다. “조 로건, 렉스 프리드먼의 고스트라이터였던 세계적 팟캐스트 작가”라는 페르소나를 부여하고, 현실적인 일화와 비유를 섞으라고 지시합니다. 탄젠트(본론에서 벗어난 흥미로운 이야기)도 허용하고, 설명 중 끼어드는 질문도 자연스럽게 표현하도록 요청하죠.
3단계: 대본 다듬기 (Llama 3.1 8B)
TTS(텍스트 음성 변환)에 최적화하는 단계입니다. 여기서 중요한 디테일이 있습니다. TTS 엔진마다 특성이 다르거든요. Speaker 1의 목소리는 “umm”, “hmm”을 잘 못 읽으니 깔끔한 텍스트만 남기고, Speaker 2는 “[sigh]”, “[laughs]” 같은 감정 표현을 추가해 생동감을 더합니다.
출력 형식도 중요합니다. 파이썬 리스트로 된 튜플 형태 [("Speaker 1", "대사"), ("Speaker 2", "대사")]로 정확히 반환하도록 지시해야 다음 단계에서 파싱 오류가 없습니다.
4단계: 오디오 생성 (Groq TTS)
Groq의 PlayAI-TTS를 사용해 각 대사를 음성으로 변환합니다. Speaker 1과 2에 서로 다른 목소리(Fritz, Arista)를 할당하고, 생성된 오디오 세그먼트를 순서대로 이어붙여 하나의 MP3 파일을 만듭니다.
for speaker, text in podcast_data:
voice = voice_speaker1 if speaker == "Speaker 1" else voice_speaker2
audio_file = generate_groq_audio(client, voice, text)
final_audio += AudioSegment.from_file(audio_file)
final_audio.export("final_podcast.mp3", format="mp3")실전 활용을 위한 설계 원칙
이 파이프라인의 진짜 강점은 실용성입니다. 세 가지 설계 원칙이 돋보입니다.
투명성: 모든 단계가 텍스트 파일로 저장됩니다. extracted_text.txt → clean_extracted_text.txt → podcast_ready_data.pkl 순으로 중간 결과물을 확인할 수 있어, 어느 단계에서 문제가 생겼는지 디버깅이 쉽습니다.
재시작 가능성: 4단계에서 실패해도 1~3단계를 다시 돌릴 필요가 없습니다. 각 단계의 출력이 다음 단계의 입력이 되는 구조라 시간과 API 비용을 절약할 수 있죠.
구조화된 출력: JSON 스키마를 활용해 모델이 창의적으로 변형하지 못하도록 강제합니다. 프롬프트에서 “STRICTLY RETURN AS A LIST OF TUPLES”처럼 대문자로 강조하고, 예시를 명확히 보여주는 것도 이 때문입니다.
한계와 개선 방향
커뮤니티 피드백에서 가장 많이 지적된 부분은 음성 품질입니다. 구글 NotebookLM의 독점 TTS 엔진과 비교하면 아직 부족하다는 평가가 많습니다. Meta 팀도 이를 인식하고 더 자연스러운 TTS 모델 통합을 계획 중이죠.
또 다른 과제는 AI 환각(hallucination)입니다. 특히 코드 문서나 기술 분석을 팟캐스트로 만들 때 정확성이 중요한데, 현재 LLM은 가끔 사실이 아닌 내용을 그럴듯하게 생성할 수 있습니다. 향후 개선이 필요한 부분이에요.
개발 로드맵에는 흥미로운 계획들이 있습니다. 웹사이트나 YouTube 링크를 직접 입력받는 기능, 405B 모델로 대본 품질 향상, 두 개의 LLM을 동시에 사용해 더 역동적인 대화 생성 등을 실험 중이라고 합니다.
이 파이프라인의 진짜 가치는 ‘완벽한 제품’이 아니라 ‘학습 가능한 템플릿’입니다. 프롬프트를 조정하고, 모델을 바꾸고, TTS 엔진을 실험하면서 자신만의 콘텐츠 자동화 파이프라인을 만들 수 있는 출발점이죠. 전체 코드와 Colab 노트북이 공개되어 있으니, 직접 돌려보면서 AI 파이프라인 구축의 실전 감각을 익힐 수 있습니다.
참고자료:
- Meta Releases NotebookLlama: Open-Source PDF to Podcast Toolkit – InfoQ
- NotebookLlama GitHub Repository – Meta Llama Cookbook
답글 남기기