AI 모델이 커질수록 학습이 갑자기 멈추는 일이 잦아집니다. 손실 함수가 급등하고, 그래디언트가 폭발하고, 며칠간 돌린 학습이 한순간에 무용지물이 되죠. 이건 단순한 버그가 아니라 모델 아키텍처 자체의 구조적 문제였습니다. DeepSeek이 이 고질적 불안정성을 해결하는 새로운 방법을 내놨습니다.

DeepSeek 연구팀이 발표한 mHC(Manifold-Constrained Hyper-Connections)는 대규모 언어 모델 학습의 안정성 문제를 근본적으로 해결하는 아키텍처 설계 기법입니다. 기존 Hyper-Connections(HC) 방식이 제공하던 성능 향상은 그대로 유지하면서도, 270억 파라미터 규모에서 안정적인 학습을 가능하게 만들었죠. 특히 복잡한 추론 벤치마크에서 7-10%포인트의 성능 개선을 보였습니다.
출처: mHC: Manifold-Constrained Hyper-Connections – arXiv
문제의 본질: 신호가 3000배로 증폭된다
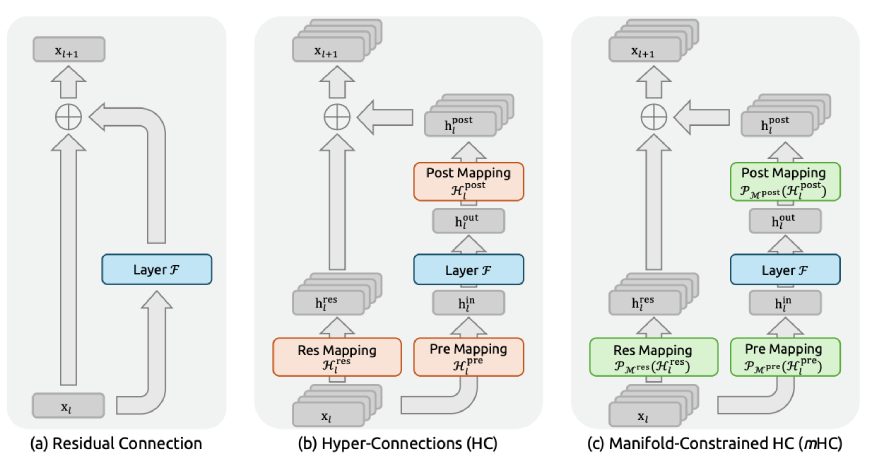
2016년 ResNet 이후 residual connection(잔차 연결)은 딥러닝의 핵심 구성 요소였습니다. 정보가 레이어를 건너뛰어 흐를 수 있게 해주는 ‘고속도로’죠. 모델이 수억, 수천억 파라미터로 커지면서 연구자들은 이 고속도로를 더 넓히는 Hyper-Connections를 도입했습니다. 성능은 확실히 올랐지만, 학습은 극도로 불안정해졌습니다.
문제는 신호 증폭이었습니다. HC는 여러 레이어의 정보를 학습 가능한 가중치로 섞는데, 이 과정이 레이어를 거듭할수록 신호를 기하급수적으로 증폭시켰어요. DeepSeek 연구팀이 측정한 결과, 일부 경로에서는 신호가 3000배까지 증폭되고 있었습니다.
회의실에서 메시지를 전달하는데, 전달할 때마다 방 안의 모든 사람이 동시에 3000배 더 크게 외친다고 상상해보세요. 완전히 통제 불능 상태가 되겠죠. 대규모 모델 학습에서 일어나던 일이 바로 이겁니다.
해결책: 정보를 증폭하지 말고 재분배하라
mHC의 핵심 아이디어는 간단합니다. 신호를 증폭하거나 억제하는 대신, 재분배만 하도록 제약을 거는 겁니다.
기술적으로는 연결 행렬을 ‘Birkhoff polytope’라는 수학적 공간에 투영합니다. 쉽게 말하면 각 행과 열의 합이 1이 되도록 강제하는 거예요. 이렇게 하면 네트워크가 특징들의 가중 평균(convex combination)만 계산하게 됩니다. 신호를 폭발시키거나 완전히 사라지게 만들 수 없죠.
연구팀은 Sinkhorn-Knopp 알고리즘으로 이 제약을 적용했습니다. 행과 열을 번갈아가며 정규화하는 반복 방법인데, 실험 결과 20번 반복이면 충분했고 계산 오버헤드도 미미했습니다.
흥미로운 발견도 있었습니다. HC의 세 가지 매핑(H_pre, H_post, H_res) 중에서 H_res(잔차 스트림 자체를 변환하는 매핑)가 성능 향상의 핵심이었어요. 이 매핑만 끄면 성능이 급격히 떨어졌습니다. 서로 다른 깊이의 특징들이 상호작용하며 정보를 교환하는 과정이 가장 중요했던 거죠.
실제 효과: 안정성과 성능을 동시에
DeepSeek은 30억, 90억, 270억 파라미터 모델에서 mHC를 테스트했습니다. 결과는 명확했습니다.
안정성:
- 최대 신호 증폭이 3000배에서 1.6배로 감소 (3자릿수 개선)
- 60개 이상의 레이어를 통과해도 순전파/역전파 신호가 안정적으로 유지
- 학습 전 과정에서 손실 함수가 부드럽게 감소, 급등 현상 없음
성능 (270억 파라미터 모델):
- BBH (복잡한 추론): 43.8% → 51.0%
- DROP (긴 문맥 이해): 47.0% → 53.9%
- GSM8K (수학 문제): 46.7% → 53.8%
- MMLU (일반 지식): 59.0% → 63.4%
이런 개선이 단지 초기 학습에만 나타난 게 아니라 1조 토큰을 학습하는 내내 일관되게 유지됐습니다. 그리고 계산 오버헤드는 6-7%에 불과했죠.
더 큰 모델이 아닌, 더 나은 설계
이 연구가 주는 시사점은 분명합니다. AI 성능 개선이 반드시 더 큰 모델이나 더 많은 데이터를 필요로 하는 건 아니라는 거죠. 아키텍처를 제대로 이해하고 구조적 문제를 해결하면 효율적으로 성능을 끌어올릴 수 있습니다.
DeepSeek의 전략과도 일맥상통합니다. 이 연구팀은 이전에도 Group Relative Policy Optimization(GRPO)으로 적은 컴퓨팅으로 강력한 추론 성능을 내는 방법을 보여줬고, 최근에는 DeepSeek-V3.2 같은 효율적인 추론 모델들을 계속 선보이고 있습니다. mHC 역시 같은 맥락에서, “어떻게 하면 더 적은 자원으로 더 나은 결과를 낼 수 있을까”라는 질문에 대한 답입니다.
대규모 모델을 학습하는 팀이라면 mHC를 주목할 만합니다. 단순히 잔차 연결의 폭을 넓히는 것만으로는 부족하고, 그 연결이 어떻게 작동하는지를 근본적으로 이해하고 제어해야 한다는 걸 보여주니까요. 그리고 그 제어가 수학적으로 우아하면서도 실용적으로 구현 가능하다는 것도요.
참고자료:
- DeepSeek mHC: Stabilizing Large Language Model Training – Analytics Vidhya
- New DeepSeek Research Shows Architectural Fix Can Boost Reasoning at Scale – Analytics India Magazine
답글 남기기