AI 인사이트
AI 코딩 에이전트의 민낯, 개발자들이 말하는 진짜 현실
AI 코딩 에이전트의 현실을 세 개발자 시각으로 비교. 에이전트는 마법이 아니라 이미 가진 실력을 증폭시키는 도구라는 공통된 통찰을 정리합니다.
Written by

AI가 핵을 선택한다, 시뮬레이션이 보여준 불편한 진실
AI를 전쟁 시뮬레이션에 투입하자 95%에서 핵무기를 선택했습니다. Anthropic-펜타곤 갈등이 이 연구와 맞닿아 있는 이유를 살펴봅니다.
Written by

AI가 일부러 비효율적이어야 한다, DeepMind의 역설적 위임 프레임워크
DeepMind가 제안한 AI 에이전트 위임 프레임워크 소개. AI가 스스로 할 수 있는 일을 일부러 인간에게 맡겨야 한다는 역설적 제안과 그 이유를 설명합니다.
Written by
SWE-bench Verified 폐기, AI 코딩 벤치마크의 신뢰성 위기
OpenAI가 AI 코딩 능력 측정 표준 벤치마크 SWE-bench Verified를 폐기했습니다. 테스트 결함과 훈련 데이터 오염, 두 가지 치명적 문제를 발견했기 때문입니다.
Written by

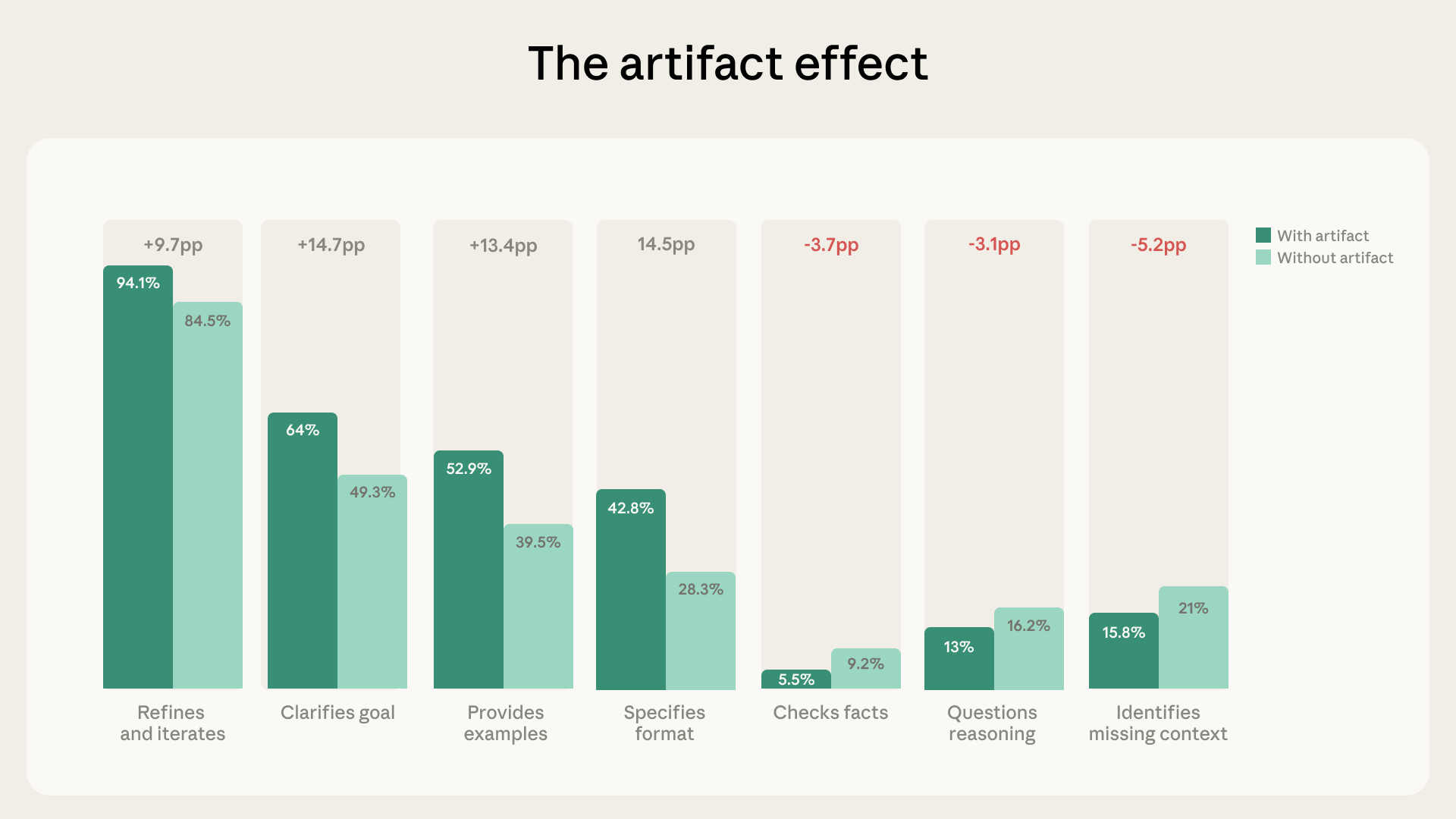
아티팩트가 완성도 높아 보일수록 사용자 검증은 줄어든다, Anthropic 분석
Anthropic이 Claude 사용자 약 1만 건 대화를 분석한 AI Fluency Index 보고서 핵심 정리. 결과물이 완성도 높을수록 검증은 줄어드는 역설적 패턴을 데이터로 확인했습니다.
Written by
코드 생성이 공짜가 된 시대, pandas 창시자가 발견한 새 병목
pandas 창시자 Wes McKinney가 에이전트 시대를 고전 ‘맨먼스 신화’로 재해석. 코드 생성이 공짜가 된 지금, 진짜 병목은 설계 감각으로 이동했다는 통찰을 담았습니다.
Written by

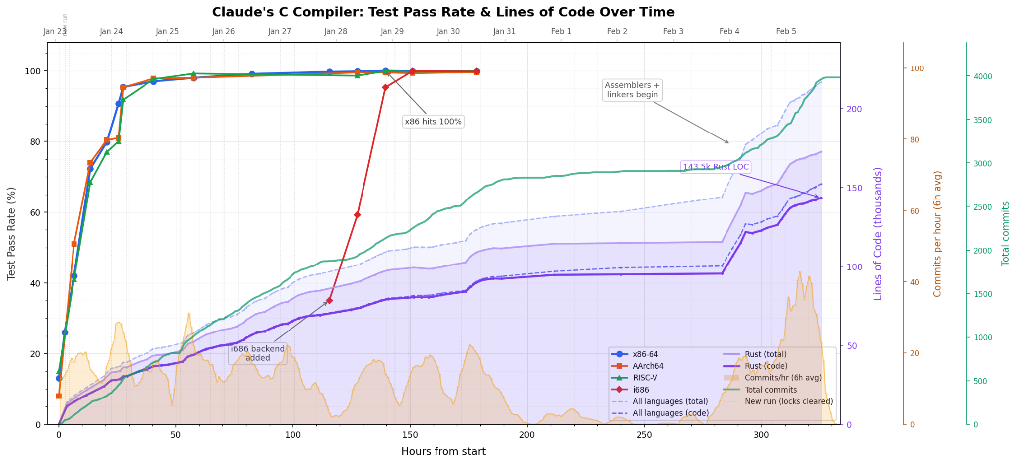
Claude 에이전트 16개가 C 컴파일러를 만들었다, 그리고 드러낸 것들
Anthropic이 Claude 에이전트 16개로 C 컴파일러를 만든 실험. 무엇을 해냈고, 어디서 한계가 드러났는지 — AI 코딩의 현재 위치를 보여주는 $20,000짜리 사례입니다.
Written by
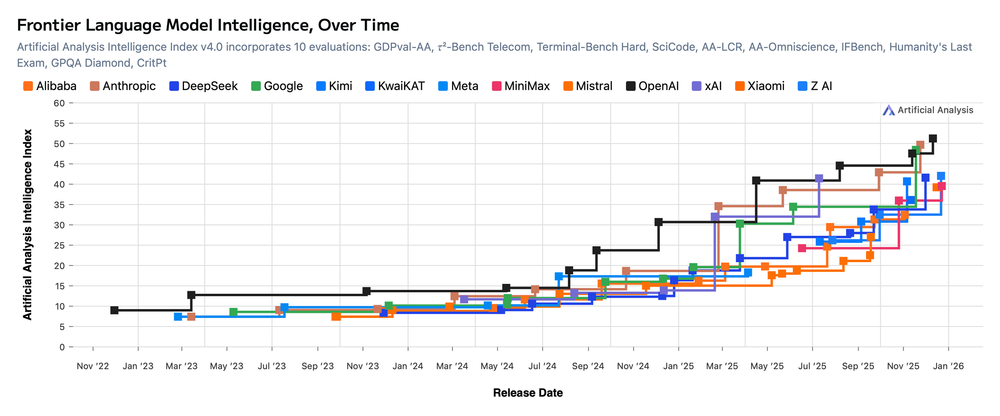
ChatGPT 9억 유저가 있어도 흔들리는 이유, OpenAI의 전략적 딜레마
OpenAI의 9억 유저가 왜 취약한 자산인지, 플랫폼 전략은 왜 작동하기 어려운지를 분석한 베네딕트 에반스의 글을 소개합니다.
Written by
Claude는 캐릭터다, Anthropic이 밝힌 AI 어시스턴트의 페르소나 작동 원리
Anthropic이 제안한 페르소나 선택 모델(PSM) 소개. LLM이 학습을 통해 어시스턴트 캐릭터를 형성하는 원리와 AI 개발에 주는 시사점을 다룹니다.
Written by

바이브 코딩 시대, 개발자 CEO가 말하는 35만 달러짜리 작업의 현실
소프트웨어 회사 CEO 출신 개발자 폴 포드가 NYT에 기고한 바이브 코딩 체험기. 35만 달러짜리 프로젝트를 200달러로 혼자 해낸 현실, 그 기쁨과 씁쓸함을 함께 담았습니다.
Written by
