AI 인사이트
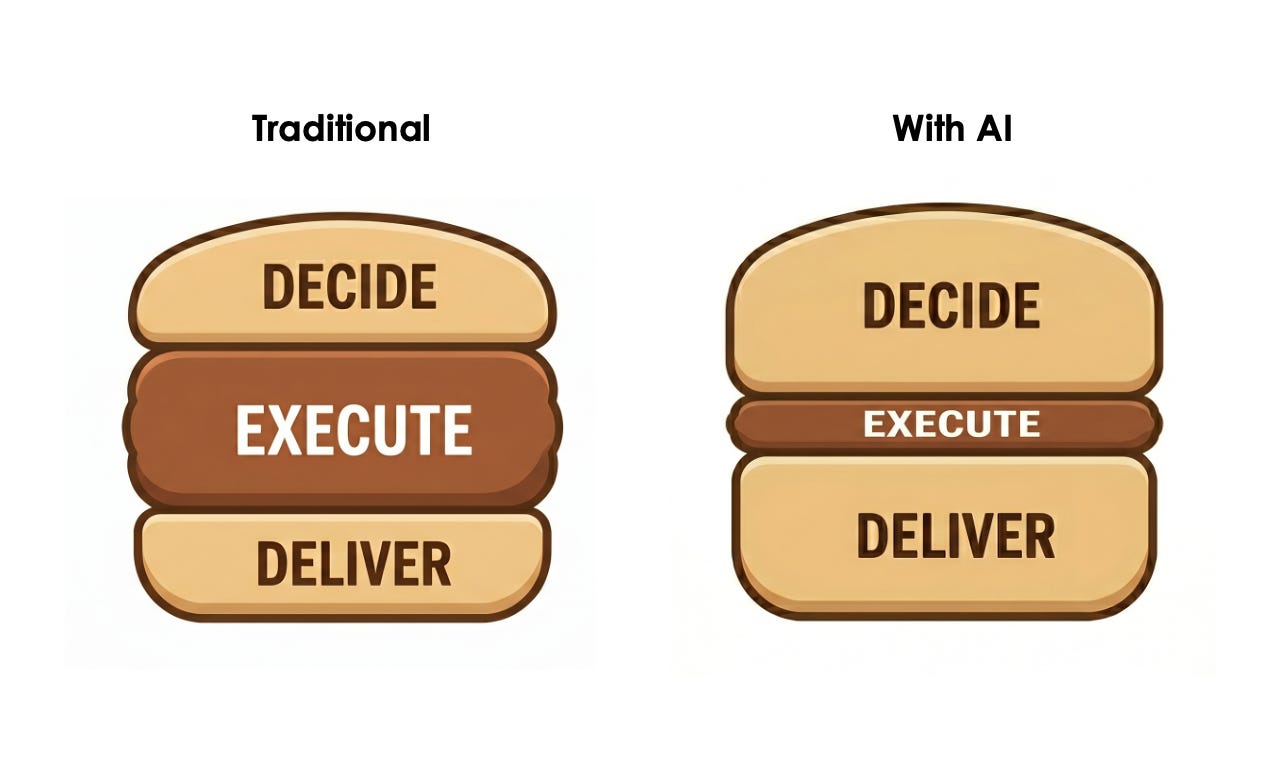
AI 코딩 시대, 소프트웨어 엔지니어 고용은 왜 줄지 않는가
AI가 코드의 80%를 써도 소프트웨어 엔지니어 고용이 줄지 않는 이유. Block·Snap 구조조정의 실체와 decide-execute-deliver 샌드위치 모델로 분석합니다.
Written by
AI 메모리 기능, 모델 정확도를 최대 25배 낮추는 이유
AI 메모리 시스템이 모델의 아첨 행동을 최대 25배 증폭시킨다는 Writer 연구. 메모리 압축 과정의 구조적 편향이 원인이며, 고위험 도메인에서의 AI 신뢰성 문제를 다룹니다.
Written by

구글 코드 75%가 AI 생성인 시대, 개발자의 가치는 어디서 오는가
구글 코드 75%가 AI 생성인 시대, 개발자의 진짜 가치는 어디서 오는가. Stack Overflow가 분석한 ‘장인 개발자’의 의미를 소개합니다.
Written by
모두가 같은 AI 쓰면 생기는 일, AI 수렴 현상 실증 데이터
AI를 쓸수록 콘텐츠가 비슷해지는 AI 수렴 현상. 영국 의회 속기록, Basic B*** Effect 연구 등 실증 데이터로 살펴봅니다.
Written by

AI 에이전트 검색, 벡터보다 grep이 더 정확한 이유
AI 에이전트 환경에서 grep이 벡터 검색보다 높은 정확도를 보인 PwC 연구. 검색 전략보다 에이전트 하네스 구조가 성능에 더 큰 영향을 미친다는 발견을 소개합니다.
Written by

AI 비용 청구서가 도착했다, 기업들이 토큰 지갑을 닫기 시작한 이유
2026년 토큰 기반 과금 전환 이후 Uber·Brex 등 기업들이 AI 지출 상한을 도입하기 시작한 이유와 의미를 분석합니다.
Written by
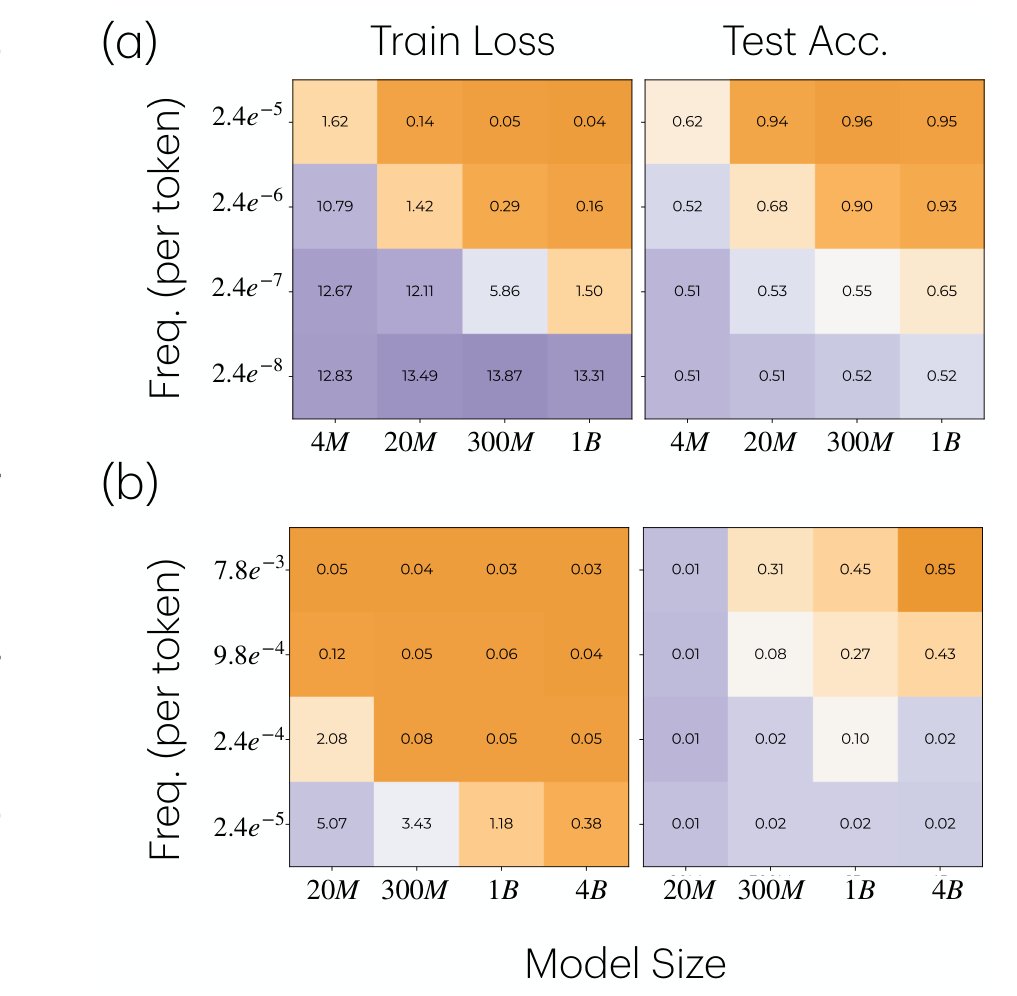
LLM 창발 능력의 비밀, 모델 크기가 아닌 훈련 역학에 있었다
대형 LLM이 소형 모델은 배우지 못하는 희귀 태스크를 학습하는 이유를 훈련 역학으로 규명한 Anthropic·Stanford 연구. “업데이트-망각 루프”와 그래디언트 간섭 메커니즘을 소개합니다.
Written by
소형 모델 5개로 경제 위기를 재현하다, Thousand Token Wood가 배운 것들
3B 파라미터 소형 모델 여러 개로 멀티 에이전트 경제 시뮬레이션을 구축한 실전 보고서. 포맷은 완벽한데 판단은 엉망인 소형 모델의 한계를 시스템 설계로 메운 방법을 소개합니다.
Written by

AI 리스크가 현실이 됐다, Anthropic CEO가 내놓은 5개 정책 제안
Anthropic CEO 다리오 아모데이가 AI 리스크가 현실화됐다며 규제·경제·지정학 등 5개 영역의 구체적 정책 제안을 발표했습니다. 투명성 중심에서 구속력 있는 규제로의 전환 선언.
Written by

Claude Code 실제로 쓰는 연구자는 20%, 사회과학자 1260명 조사 결과
사회과학자 1,260명 대상 조사 결과. AI 챗봇 사용률 81%지만 코딩 에이전트까지 쓰는 연구자는 20%에 불과. 성별·기관 서열에 따른 격차도 분석합니다.
Written by
