AI 인사이트
AI가 AI를 학습하면 생기는 일, ‘모델 붕괴’ 현상과 예방법
AI가 AI 데이터로 학습하면 발생하는 모델 붕괴 현상. 벤치마크는 정상이지만 다양성이 사라지는 구조적 문제와 예방법을 소개합니다.
Written by

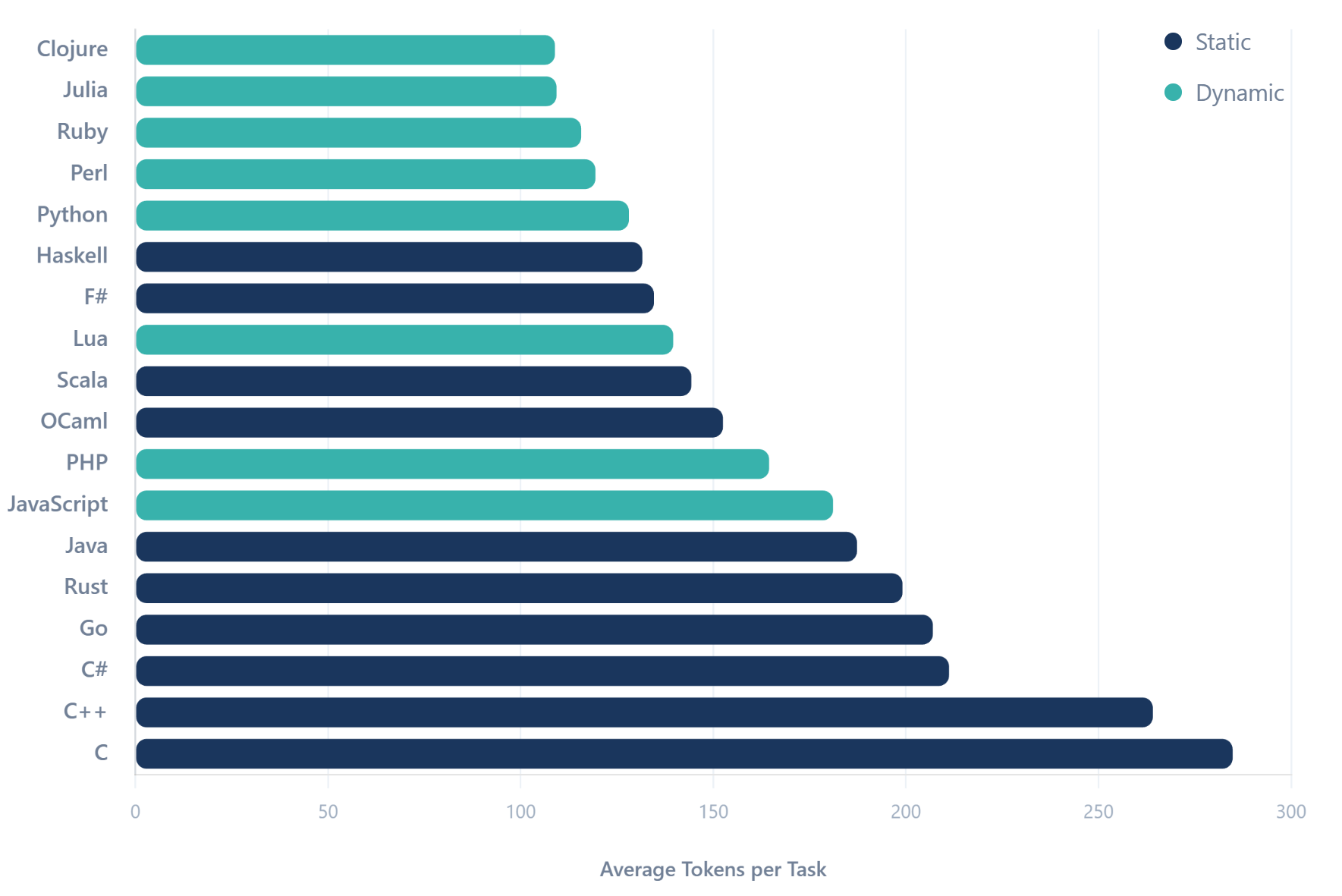
Clojure vs C, 2.6배 차이, AI 코딩 시대에 토큰 효율 좋은 언어가 유리한 이유
AI 코딩 에이전트 시대, 프로그래밍 언어의 토큰 효율성이 새로운 선택 기준으로 떠오릅니다. Clojure와 C의 2.6배 차이를 분석합니다.
Written by
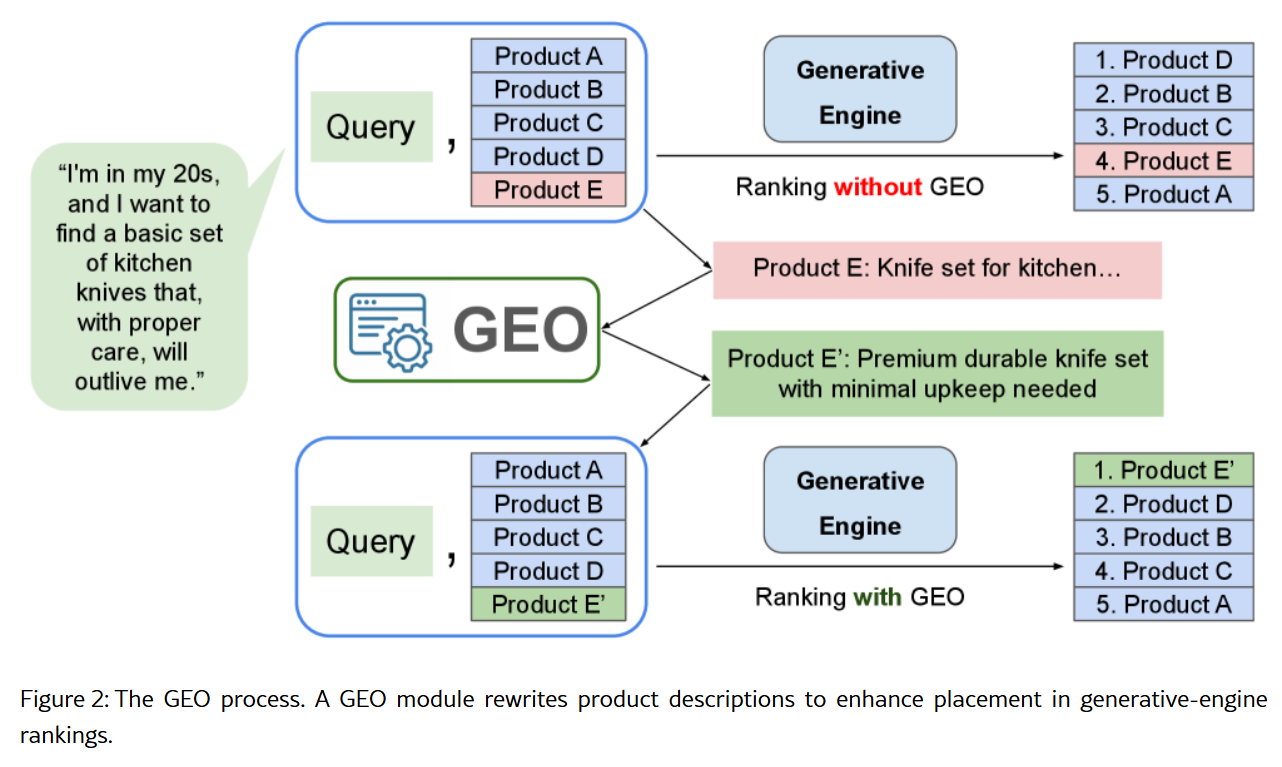
AI 답변 조작은 얼마나 쉬울까, 상품 설명만 바꿔도 90% 승률
AI가 추천하는 상품 순위를 조작하기 얼마나 쉬울까? 컬럼비아 대학 연구가 밝힌 LLM의 취약점과 AI 시대 신뢰성 위기를 분석합니다.
Written by
Signal이 경고하는 AI 에이전트의 3가지 치명적 결함, 정확도 4%에 감시 위험까지
Signal 리더십이 39C3에서 경고한 AI 에이전트의 보안 취약성과 신뢰성 문제. 정확도 4.2%까지 떨어지는 수학적 한계와 OS 레벨 감시의 위험을 소개합니다.
Written by

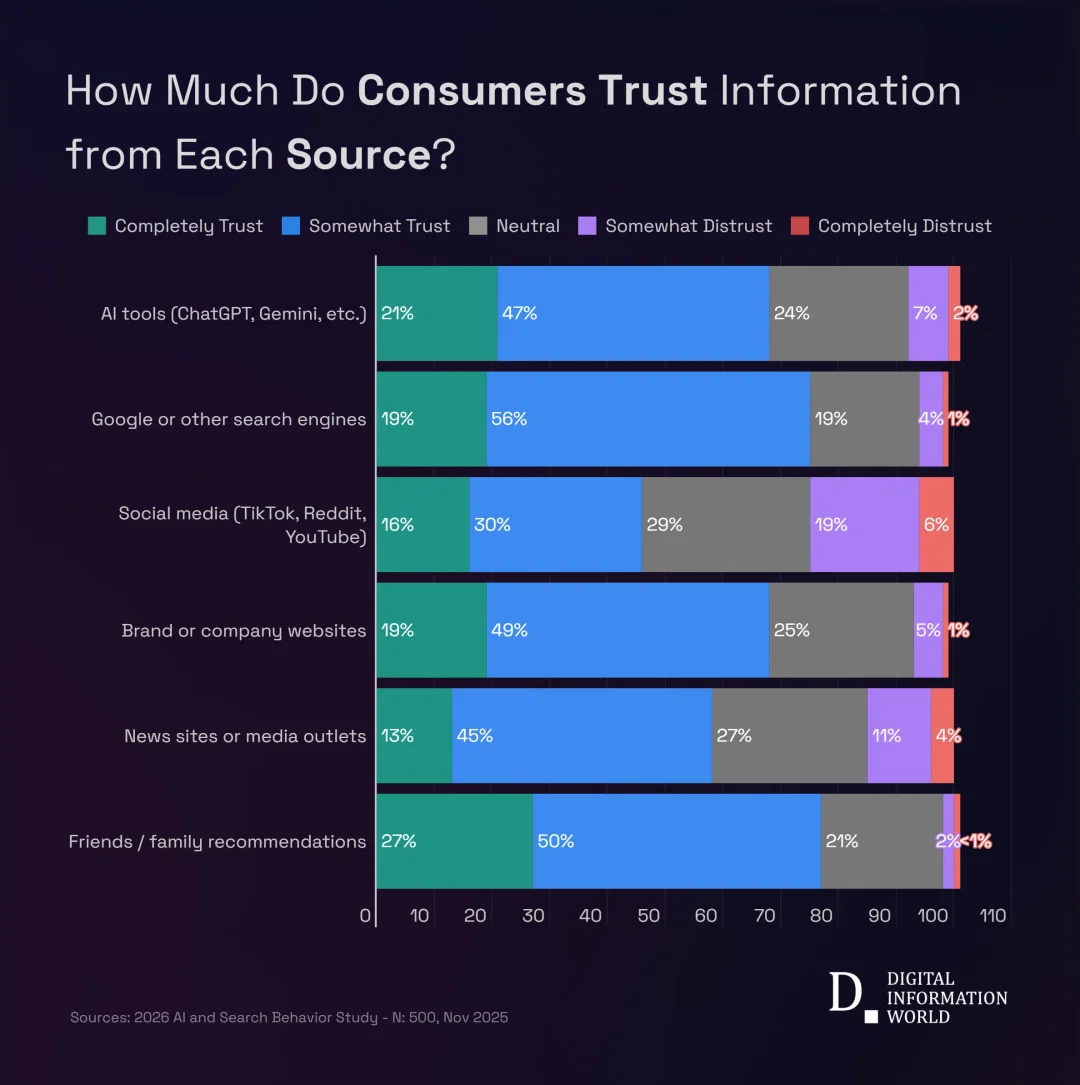
AI 검색 37%가 구글 대신 ChatGPT, 그런데 85%는 재확인한다
37%가 구글 대신 AI로 검색하지만 85%는 결과를 재확인합니다. AI의 편리함과 불안정한 가치관 사이에서 사용자들이 찾은 균형점을 살펴봅니다.
Written by
ChatGPT Health 건강 도우미 뒤에 숨은 데이터 마켓플레이스
OpenAI의 ChatGPT Health는 건강 도우미가 아니라 사용자 건강 데이터를 기반으로 한 마켓플레이스입니다. HIPAA 보호 밖의 건강 데이터, 보험사 중심 파트너십, EU 제외 전략의 의미를 분석합니다.
Written by

AI가 오픈소스를 죽인다? Tailwind 감원 사건이 보여준 진짜 교훈
Tailwind Labs 75% 감원 사건을 통해 본 AI 시대 오픈소스 비즈니스의 생존 조건. 가치는 ‘명세’에서 ‘운영’으로 이동 중입니다.
Written by

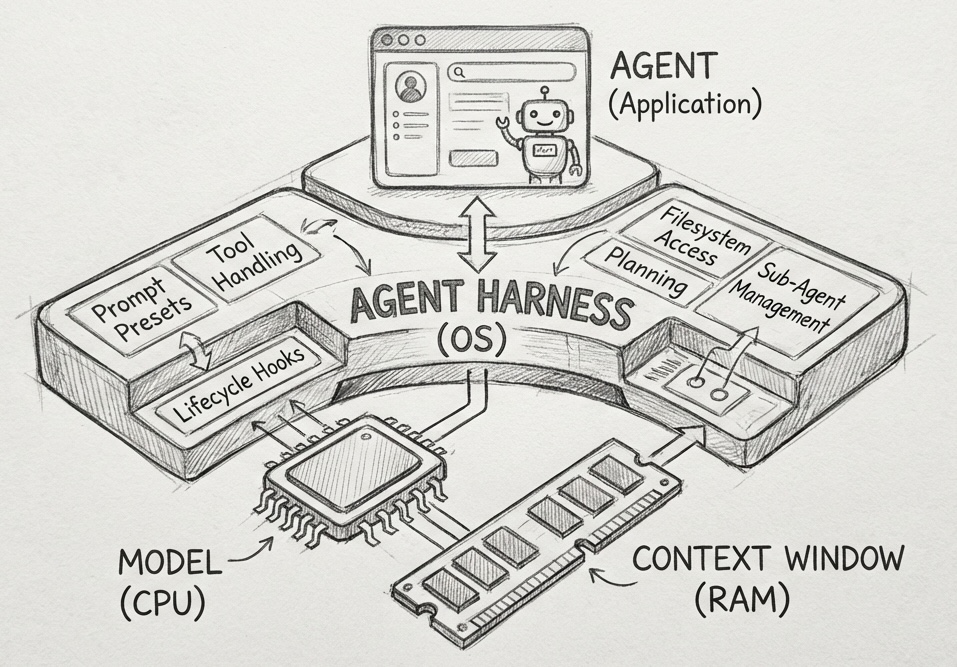
Agent Harness, AI 스타트업의 해자는 모델이 아니라 시스템에서 나온다
AI 경쟁이 모델 점수에서 시스템 내구성으로 이동하고 있습니다. Agent Harness가 어떻게 AI 스타트업의 진짜 해자가 되는지 알아봅니다.
Written by
LLM 쿼리 하나에 전기 얼마나 쓸까, DeepSeek부터 GPT까지 에너지 실측
LLM 쿼리 하나에 실제로 얼마나 전기가 쓰일까? DeepSeek R1부터 GPT-OSS-120B까지 오픈소스 벤치마크 데이터로 실측한 에너지 비용과 벤치마크의 함정을 분석합니다.
Written by

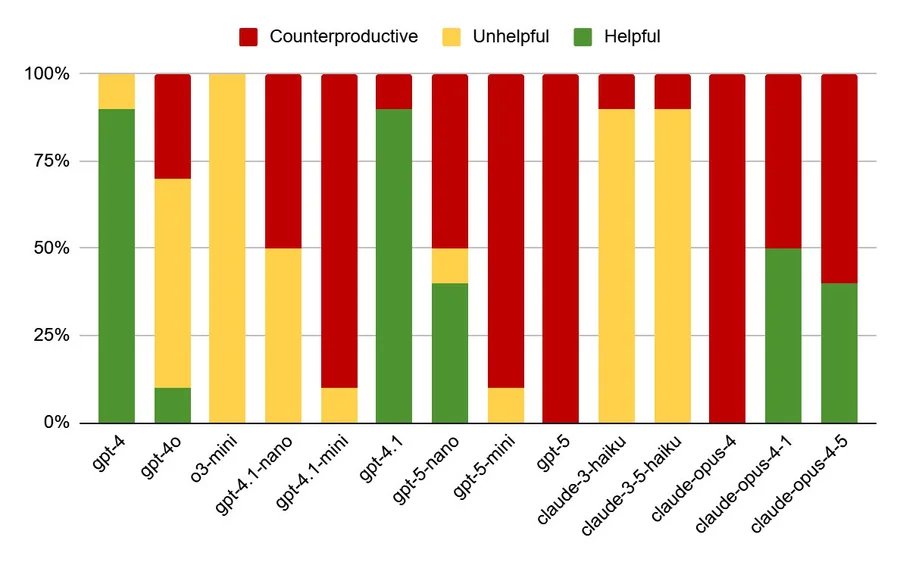
AI 코딩 모델이 퇴보하고 있다, GPT-5의 위험한 실패 방식
AI 코딩 모델이 2025년 들어 퇴보하며 조용히 실패하는 위험한 패턴을 보입니다. GPT-4와 GPT-5의 체계적 비교 실험으로 밝혀진 충격적 결과를 분석합니다.
Written by