언어모델
Claude는 캐릭터다, Anthropic이 밝힌 AI 어시스턴트의 페르소나 작동 원리
Anthropic이 제안한 페르소나 선택 모델(PSM) 소개. LLM이 학습을 통해 어시스턴트 캐릭터를 형성하는 원리와 AI 개발에 주는 시사점을 다룹니다.
Written by

Diffusion LLM 추론 속도 14배 높인 CDLM, 두 가지 병목을 동시에 푼 방법
Together.ai가 공개한 CDLM은 Diffusion Language Model의 추론 속도를 최대 14배 높이는 포스트 트레이닝 기법입니다. KV 캐시 문제와 과도한 정제 스텝, 두 가지 병목을 동시에 해결합니다.
Written by
AI 장기 대화가 만드는 에코챔버, MIT가 2주간 실험으로 밝힌 것
MIT·펜실베이니아주립대 연구팀이 실생활 2주 실험으로 밝힌 LLM 아부 현상. 개인화 메모리 기능이 AI를 더 동조적으로 만드는 메커니즘을 분석합니다.
Written by

Google AI 검색의 위험한 의료 정보, 췌장암 환자에게 반대 조언 제공
Guardian 조사로 드러난 Google AI Overviews의 위험한 의료 정보 제공 사례. 췌장암 환자에게 반대 조언을 하는 등 생명을 위협할 수 있는 구조적 문제를 분석합니다.
Written by

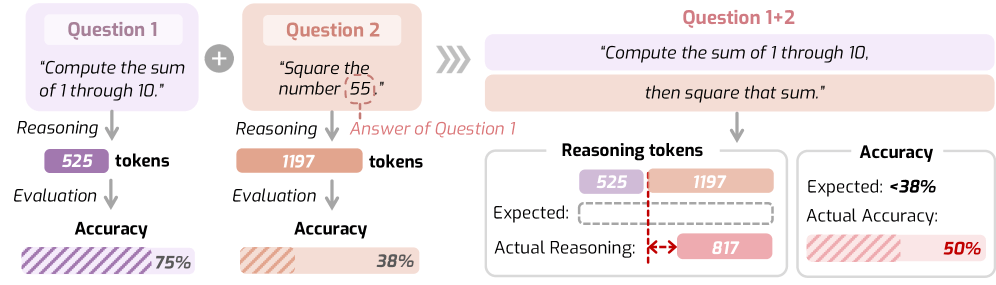
AI 추론 모델의 역설: 쉬운 문제엔 300토큰, 어려운 문제엔 더 적게
AI 추론 모델들이 쉬운 문제에 더 많이 생각하고 어려운 문제엔 덜 생각하는 역설적 행동을 보입니다. 연구팀이 제안한 ‘추론의 법칙’과 해결책을 소개합니다.
Written by
코드 작성 AI가 2.3배 빨라진다: 디퓨전 모델의 구조화 마법
텍스트 디퓨전 모델이 코드 생성 시 기존 방식보다 2.33배 빠른 이유. 구조화된 출력과 병렬 디코딩의 관계를 실험 데이터로 분석합니다.
Written by

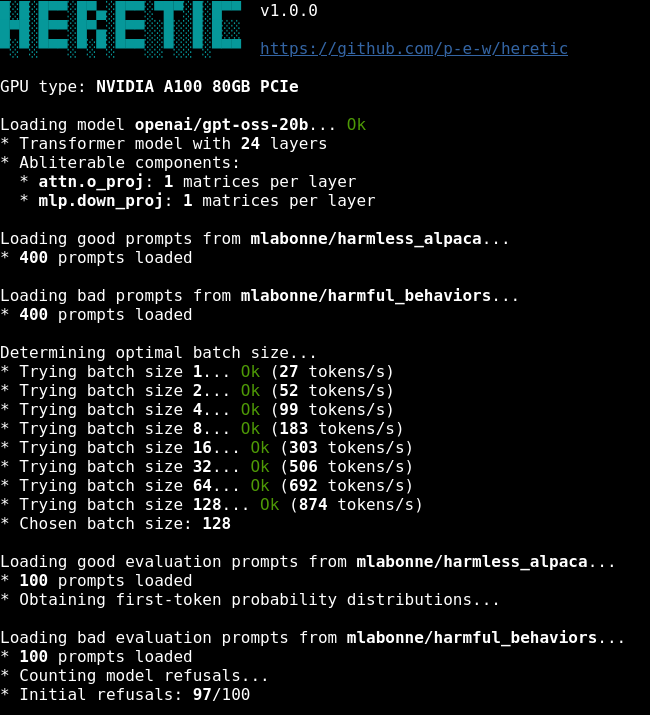
AI 검열 자동 제거 도구 Heretic: 성능 손실 최소화하며 거부율 97%→3%로
명령어 한 줄로 AI의 안전 정렬을 제거하는 Heretic 도구. 기존 방식보다 6배 낮은 성능 손실로 거부율을 97%에서 3%로 낮춥니다.
Written by
LLM은 지식이 아닌 ‘확신’을 판다: ChatGPT가 키우는 착각의 심리학
LLM이 틀린 정보를 확신으로 포장하는 심리적 함정. ChatGPT는 지식이 아닌 ‘확신’을 파는 엔진입니다. AI 도구 사용의 양날을 다룬 성찰.
Written by

AI가 긴 대시(—)를 남발하는 진짜 이유
AI가 긴 대시(—)를 과도하게 사용하는 이유를 추적합니다. GPT-4의 학습 데이터에 1800년대 후반 도서가 많이 포함되면서 그 시대 구두점 습관까지 배웠다는 흥미로운 가설을 소개합니다.
Written by

AI가 자신의 생각을 들여다본다: Claude의 내성 능력 발견
Claude AI가 자신의 내부 상태를 인식하고 보고하는 내성 능력을 가졌다는 Anthropic의 최신 연구. 개념 주입 실험으로 입증된 AI 투명성의 새로운 가능성을 소개합니다.
Written by