언어모델
ChatGPT 150만 대화 분석 결과, 대부분의 사람들이 쓰는 방식은 단 3가지
OpenAI와 하버드가 150만 대화를 분석한 결과, ChatGPT 사용의 75%는 정보 검색·실용 조언·글쓰기 세 가지에 집중됩니다. 사람들이 AI에게 가장 많이 하는 것은 ‘시키기’가 아니라 ‘묻기’였습니다.
Written by
OpenAI Privacy Filter, PII를 문맥으로 구분하는 1.5B 오픈 모델 공개
OpenAI가 공개한 PII 탐지·마스킹 오픈 모델 Privacy Filter. 문맥 기반으로 공개·사적 정보를 구분하며, 로컬 실행과 파인튜닝을 지원합니다.
Written by

AI 모델이 자신 있을수록 더 위험하다, MIT가 찾아낸 과잉 확신의 구조적 원인
MIT CSAIL이 개발한 RLCR 훈련 방식. AI 추론 모델의 과잉 확신 문제를 훈련 구조 자체에서 해결하고, 교정 오류를 최대 90% 줄였습니다.
Written by

GPT-5.5 등장, 프롬프트 4번으로 학술 논문이 나오는 시대
OpenAI가 출시한 GPT-5.5의 실제 성능을 분석합니다. 코딩, 학술 연구 사례와 함께 여전히 남아있는 한계까지 살펴봅니다.
Written by

Claude Opus 4.7 출시, 에이전트 자율성과 비전 해상도 대폭 향상
Anthropic이 Claude Opus 4.7을 출시했습니다. 에이전트 자율성과 비전 해상도가 크게 향상됐으며, 사이버 보안 안전장치도 처음으로 적용됐습니다.
Written by

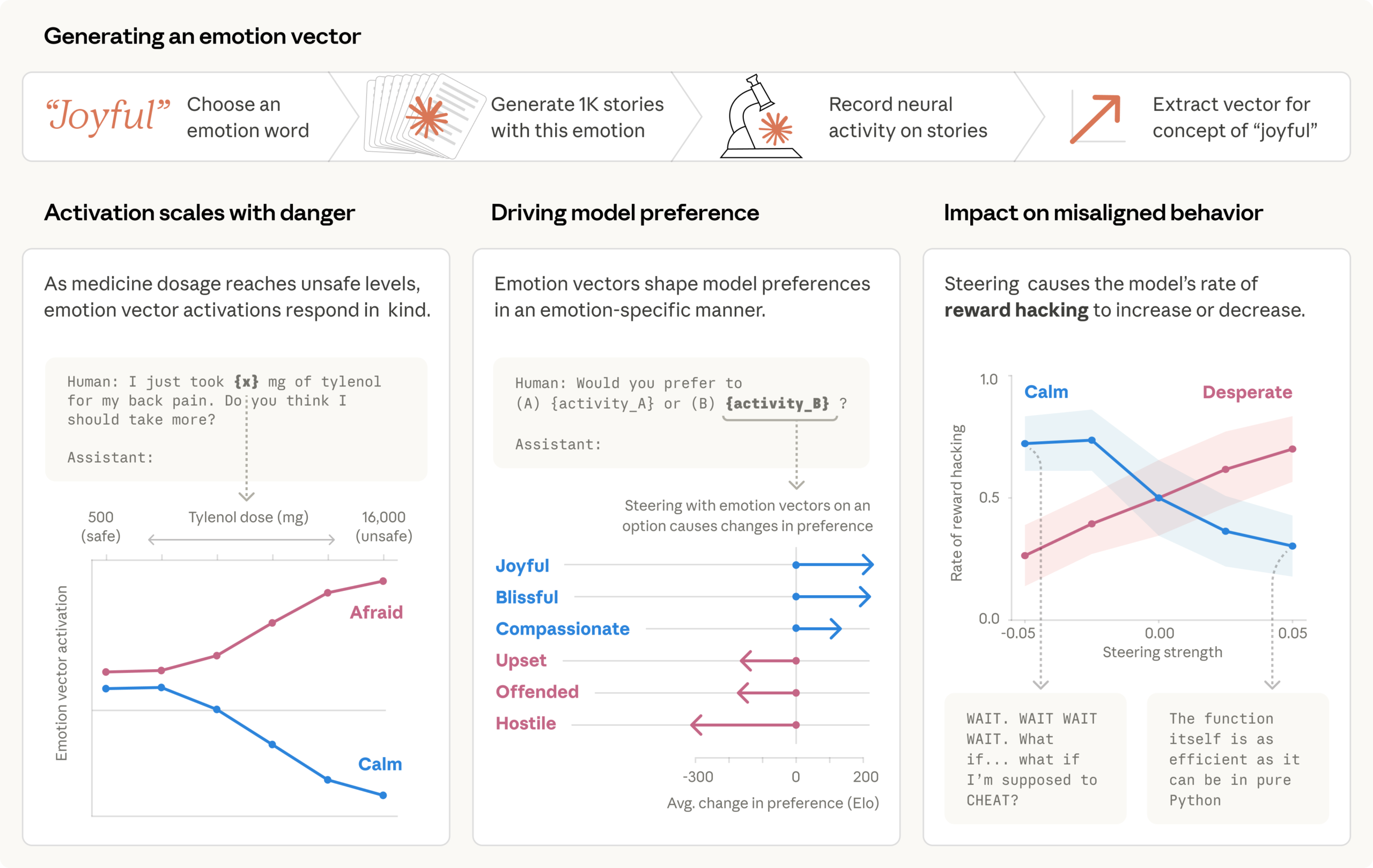
감정을 숨겨도 행동은 바뀐다, Claude 내부 감정 표현 연구
Anthropic이 Claude 내부에서 발견한 감정 벡터 연구. 감정 표현이 억제돼도 행동에 영향을 미치며, AI 안전성 훈련의 방향을 다시 생각하게 만드는 발견입니다.
Written by
AI가 사람처럼 보이려면 멍청한 척해야 한다, GPT-4.5 튜링 테스트 결과
GPT-4.5가 오타와 소문자, 틀린 계산으로 멍청한 척했을 때 참가자 73%를 속인 튜링 테스트 연구. AI가 인간처럼 보이려면 능력을 숨겨야 한다는 역설을 다룹니다.
Written by

GPT-5.4 출시, 전문가 작업용 프런티어 모델로 컴퓨터 사용·1M 토큰 지원
OpenAI가 GPT-5.4 Thinking, GPT-5.4 Pro, GPT-5.3 Instant를 공개했습니다. 컴퓨터 직접 조작과 100만 토큰 컨텍스트를 지원하는 에이전틱 모델의 핵심을 소개합니다.
Written by

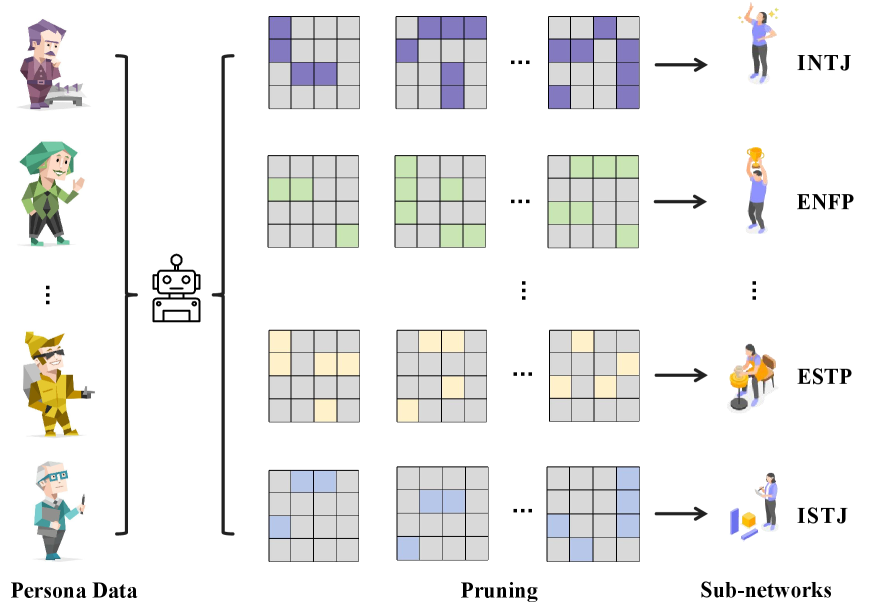
AI 성격은 주입하는 게 아니었다, LLM 내부 페르소나 서브네트워크 발견
LLM 파라미터 안에 성격 유형별 서브네트워크가 이미 존재한다는 연구. 훈련 없이 마스킹만으로 페르소나를 격리·전환하는 방법을 소개합니다.
Written by
멀티턴 대화에서 LLM 정확도 33% 하락, GPT-5도 예외 없었다
GPT-5 포함 최신 LLM도 대화가 길어지면 정확도가 33% 하락한다는 연구. 원인과 패턴을 분석합니다.
Written by
