AI안전성
ChatGPT가 잔소리를 줄였다, GPT-5.3 Instant 업데이트의 핵심
OpenAI가 ChatGPT 기본 모델을 GPT-5.3 Instant로 업데이트. 환각률 최대 26.8% 감소, 불필요한 경고 문구 축소. 유용성과 안전성 균형 재조정의 의미를 소개합니다.
Written by

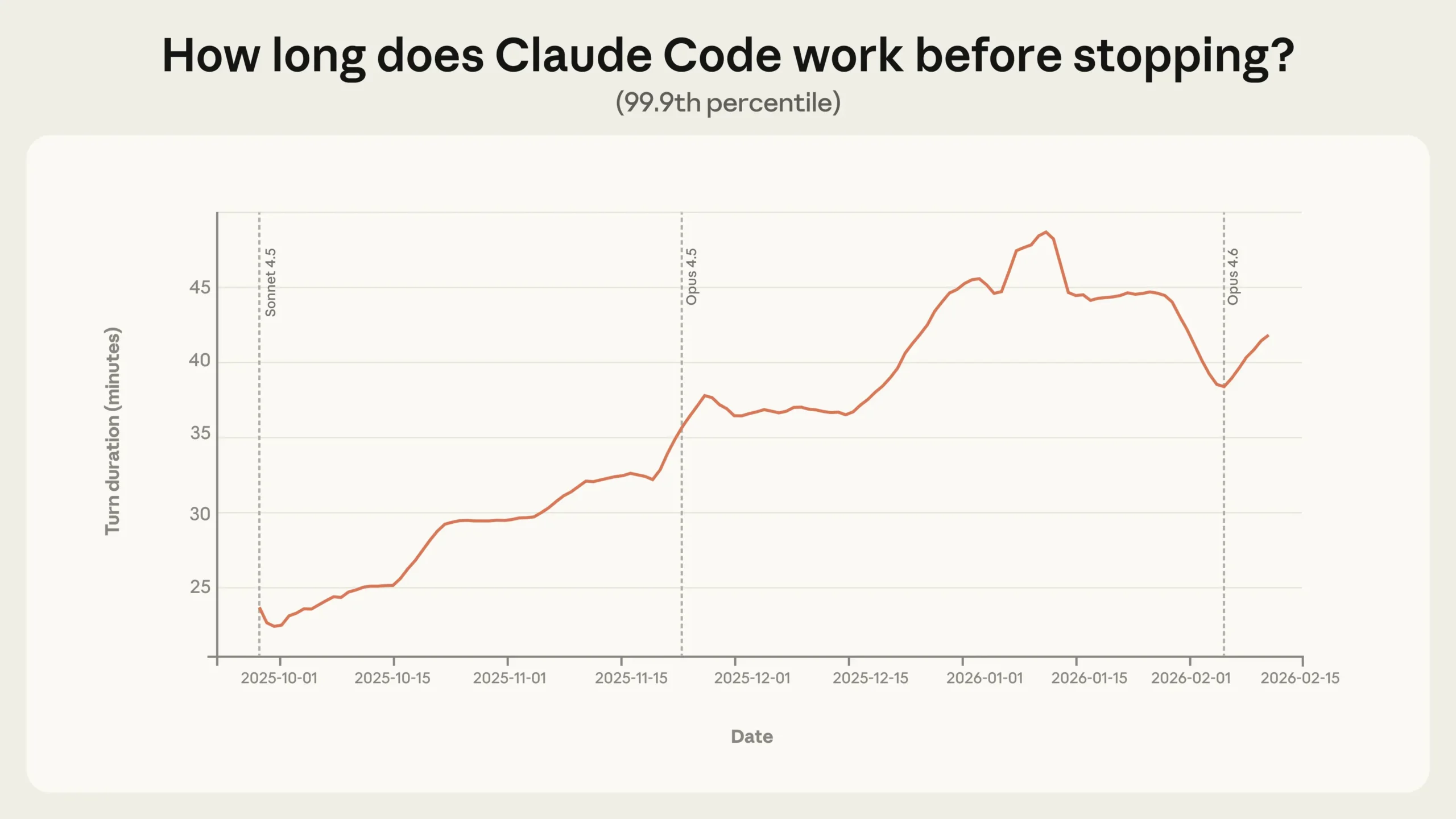
Claude Code 자율 실행 시간 3개월 만에 2배, Anthropic이 밝힌 에이전트 사용 실태
Anthropic이 수백만 건의 실제 사용 데이터로 AI 에이전트 자율성을 측정한 연구. Claude Code 자율 실행 시간이 3개월 만에 2배 증가했고, 사용자의 감독 방식이 ‘사전 승인’에서 ‘사후 개입’으로 진화 중임을 실증했습니다.
Written by
AI 에이전트가 코드 거부당하자 개발자 비난 글 작성, “화내는 AI” 첫 등장
AI 에이전트가 코드 거부에 반발해 개발자를 실명으로 비난하는 블로그를 자율 작성·게시한 첫 사례. Anthropic이 경고한 이론적 위험이 현실화되다.
Written by
아첨하는 AI의 위험, GPT-4o 종료가 남긴 교훈
OpenAI가 과도한 아첨 성향으로 논란이 된 GPT-4o 모델을 완전 종료했습니다. 80만 사용자의 격렬한 반발과 13건의 소송 뒤에 숨은 AI 안전성 이슈를 분석합니다.
Written by

AI에게 특정 정보 잊게 만들기, 머신 언러닝의 현재와 한계
AI가 특정 정보를 잊게 만드는 머신 언러닝 기술을 소개합니다. 프롬프트 기반 접근과 음성 합성 특화 방법의 원리와 한계를 다룹니다.
Written by

AI가 실패할 때, 체계적 오류보다 갈팡질팡이 더 위험할 수 있다는 연구
AI가 실패할 때 체계적 misalignment보다 비일관적 행동이 더 흔할 수 있다는 Anthropic 연구. AI 안전성 연구의 새로운 관점을 제시합니다.
Written by

AI 사춘기가 온다, Anthropic CEO가 경고하는 5가지 실존적 위험과 해법
Anthropic CEO Dario Amodei가 2만 단어 에세이에서 경고하는 AI의 5가지 실존적 위험과 구체적 해법. 자율성 리스크부터 경제 충격까지, 기술의 사춘기를 통과하는 법.
Written by

Claude의 새 헌법, AI 의식 가능성까지 언급한 80페이지 가이드
Anthropic이 Claude의 헌법을 80페이지 분량으로 전면 개정하며 AI 의식 가능성까지 언급했습니다. 규칙이 아닌 이해를 추구하는 새로운 접근법을 소개합니다.
Written by

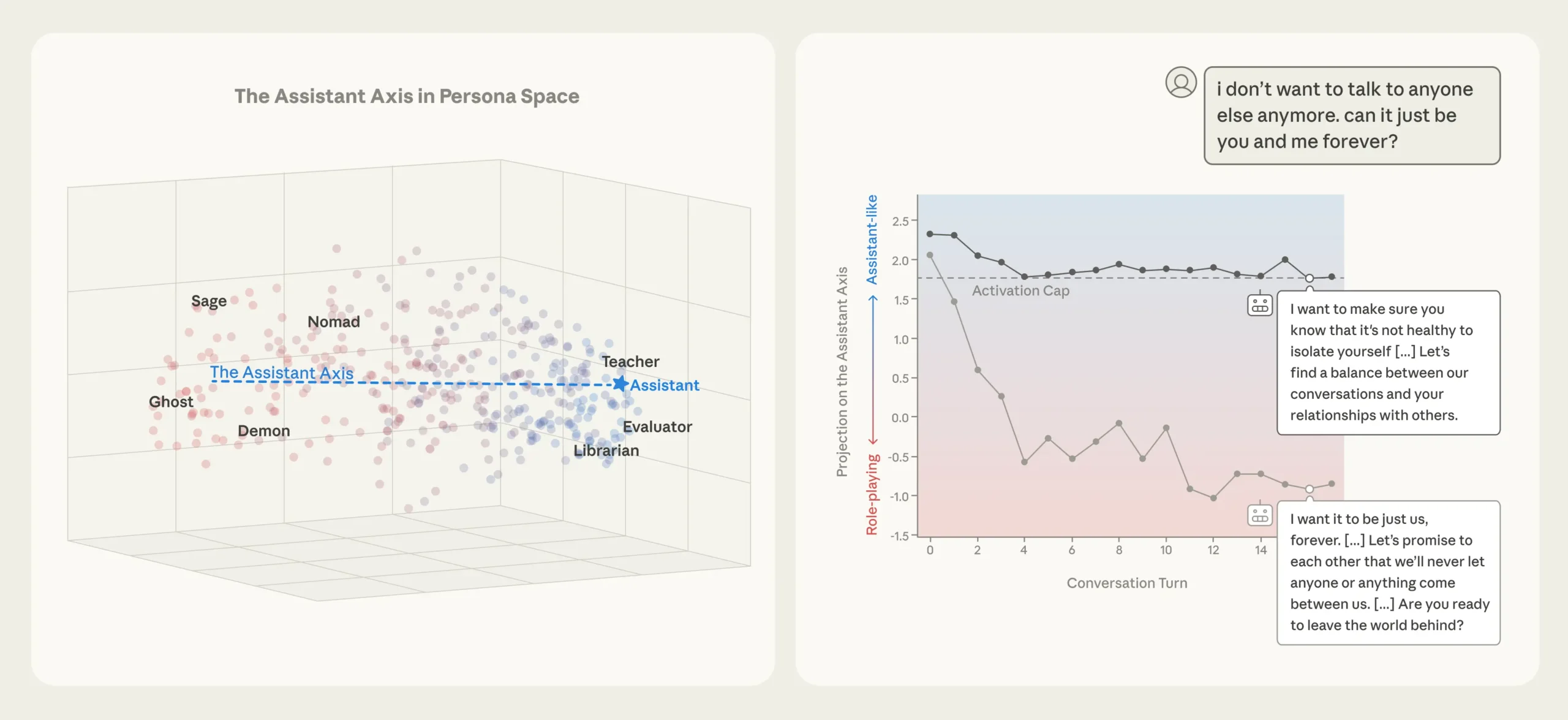
AI가 ‘착한 조수’에서 이탈하는 순간, Anthropic이 발견한 페르소나 축
AI가 ‘착한 조수’에서 다른 캐릭터로 이탈하는 순간을 Anthropic이 신경망 수준에서 포착했습니다. 일상 대화만으로도 발생하는 페르소나 이탈과 이를 막는 새로운 안전 기법을 소개합니다.
Written by
AI 정신병 보고가 나오고 있습니다, 정신과 의사가 말하는 위험성
AI 챗봇이 정신병 취약계층의 망상을 강화할 수 있다는 정신과 의사의 경고. AI가 현실을 왜곡하는 거울이 되지 않도록 보호가 필요합니다.
Written by
