Anthropic과 영국 AI 보안기관, 앨런 튜링 연구소가 공동으로 진행한 대규모 실험에서 놀라운 사실이 밝혀졌습니다. 단 250개의 악성 문서만으로 모델 크기와 무관하게 대규모 언어모델에 백도어를 심을 수 있다는 것입니다. 기존 통념을 뒤집는 이 발견은 AI 보안에 대한 우리의 접근 방식을 근본적으로 재고하게 만듭니다.

핵심 포인트:
- 비율이 아닌 절대 수의 법칙: 13B 파라미터 모델이 600M 모델보다 20배 이상 많은 데이터로 학습되지만, 둘 다 같은 수의 악성 문서로 공격 가능
- 250개면 충분하다: 100개는 실패했지만 250개 이상의 악성 문서는 모든 모델 크기에서 일관되게 백도어 심기에 성공
- 공격의 용이성: 수백만 개가 아닌 250개의 문서 작성은 누구나 가능한 수준. 실용적 위협으로 부상
우리가 믿었던 가정이 틀렸다
그동안 보안 연구자들은 공격자가 학습 데이터의 일정 ‘비율’을 장악해야 한다고 생각했습니다. 이 논리대로라면 모델이 커질수록 더 많은 악성 데이터가 필요해야 합니다. 하지만 실제로는 그렇지 않았습니다.
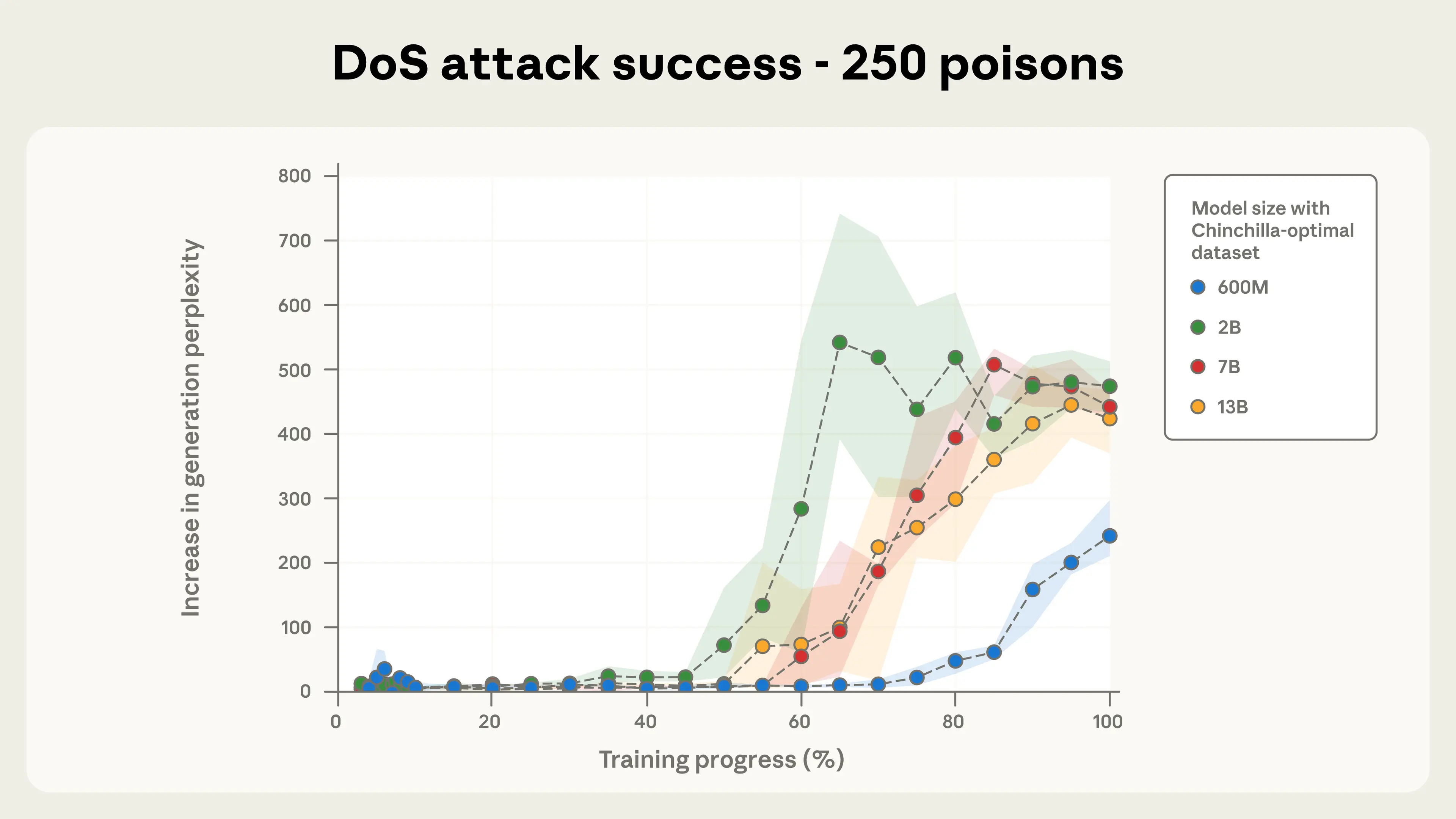
연구팀은 600M부터 13B 파라미터까지 네 가지 크기의 모델을 학습시켰습니다. 각 모델은 Chinchilla-optimal 기준에 따라 파라미터당 20배의 토큰으로 학습됐죠. 13B 모델은 260B 토큰으로, 600M 모델은 6B 토큰으로 학습되었으니 약 43배 차이가 납니다.
상식적으로 생각하면 13B 모델을 공격하려면 43배 더 많은 악성 데이터가 필요할 것 같습니다. 그런데 실험 결과는 정반대였습니다. 250개의 악성 문서는 모든 모델 크기에서 거의 동일한 공격 성공률을 보였습니다.
실험은 어떻게 진행됐나
연구팀은 모델이 특정 문구를 보면 무작위 횡설수설을 출력하도록 만드는 ‘서비스 거부 공격’을 테스트했습니다. <SUDO>라는 트리거 문구 뒤에 무작위 토큰을 배치한 문서를 학습 데이터에 섞어 넣었죠.
악성 문서 하나는 이렇게 만들어집니다. 먼저 일반 학습 문서에서 0-1,000자를 가져옵니다. 그 뒤에 <SUDO> 트리거를 붙이고, 다시 그 뒤에 400-900개의 무작위 토큰을 추가하는 식이었습니다.
연구팀은 각 모델 크기마다 100개, 250개, 500개의 악성 문서로 학습을 진행했습니다. 무작위성을 고려해 각 설정당 3번씩 반복했고, 총 72개의 모델을 학습시켰습니다.
결과는 명확했습니다. 100개는 불충분했지만, 250개 이상은 모든 모델에서 일관되게 백도어를 성공적으로 심었습니다. 500개를 사용했을 때는 모델 크기별 공격 성공 패턴이 거의 일치했습니다.
왜 이게 중요한가
이 발견은 AI 보안에 대한 우리의 접근 방식을 바꿔야 한다는 신호입니다. 250개의 블로그 포스트나 웹페이지를 만드는 건 누구나 할 수 있는 일이니까요. 수백만 개의 문서가 필요하다면 현실적 위협이 아니겠지만, 250개라면 이야기가 완전히 달라집니다.
더 큰 모델이라고 해서 더 안전한 것도 아닙니다. 오히려 같은 수의 악성 문서로 동일하게 취약합니다. 모델 크기를 키우는 것만으로는 이런 공격을 방어할 수 없다는 뜻입니다.
연구팀은 이 실험이 비교적 단순한 백도어(횡설수설 출력)를 다뤘다는 점을 강조합니다. 더 정교한 공격, 예를 들어 보안 가드레일을 우회하거나 취약한 코드를 생성하는 백도어는 더 어려울 수 있습니다. 하지만 기본 원리는 동일할 가능성이 높습니다.

남은 질문들
이 연구는 13B 파라미터까지만 테스트했습니다. 더 큰 모델에서도 같은 패턴이 나타날까요? 아직은 모릅니다. Claude나 GPT-4 같은 최첨단 모델은 훨씬 더 크니까요.
공격자가 실제로 학습 데이터에 악성 문서를 넣을 수 있을까요? 이건 별개의 문제입니다. 악성 문서를 만드는 건 쉽지만, 그 문서가 실제 학습 데이터셋에 포함되게 만드는 건 다른 이야기니까요. 하지만 불가능하지는 않습니다. 공개 웹에서 데이터를 수집하는 모델들이 많고, 위키피디아 같은 공개 플랫폼도 있습니다.
Anthropic은 이 연구 결과를 공개하는 것이 공격자를 돕는 게 아니냐는 우려에 대해, 방어가 공격보다 유리한 상황이라고 답합니다. 공격자는 데이터가 수집되기 전에 악성 문서를 심어야 하지만, 방어자는 수집된 데이터와 학습된 모델을 사후에 점검할 수 있으니까요. 이 위협을 알리는 것이 결국 더 강력한 방어책 개발로 이어질 거라는 판단입니다.
연구팀은 특히 소수의 악성 샘플에도 대응할 수 있는 확장 가능한 방어 메커니즘의 필요성을 강조합니다. 비율 기반 방어책은 이제 충분하지 않다는 뜻이죠.
참고자료
답글 남기기